怎么选?时间序列数据预测-Transformer架构的模型和算法
随着Transformer架构在自然语言处理(NLP)领域取得巨大成功,其强大的序列建模能力被迅速迁移至时间序列预测领域,引发了一场深刻的范式革命。从最初为解决长序列计算瓶颈而设计的效率优化模型(如Informer、Autoformer),到通过“分块”(Patching)思想重塑时间序列表示的PatchTST和TimesNet,再到当前以TimeGPT、Chronos、TimesFM为代表的大规模预训练基础模型的兴起,该领域的研究呈现出爆炸式增长。本文系统性地梳理一系列关键的基于Transformer的时间序列算法与大模型,详细介绍其核心架构创新,对比分析其设计哲学与性能差异,并总结它们在主流基准数据集上的表现。
从NLP到时间序列:Transformer的跨界优势
Transformer架构的核心是自注意力(Self-Attention)机制,它能够捕捉序列中任意两个位置之间的依赖关系,而不受它们之间距离的限制。这一特性使其在处理长距离依赖问题上天然优于循环神经网络(RNN)和长短期记忆网络(LSTM)等传统序列模型,LSTM在处理长序列时容易出现梯度消失或爆炸问题。此外,Transformer的并行计算能力使其能够高效处理大规模数据集,为构建大型模型奠定了基础。这些优势使其成为时间序列预测领域极具吸引力的选择。
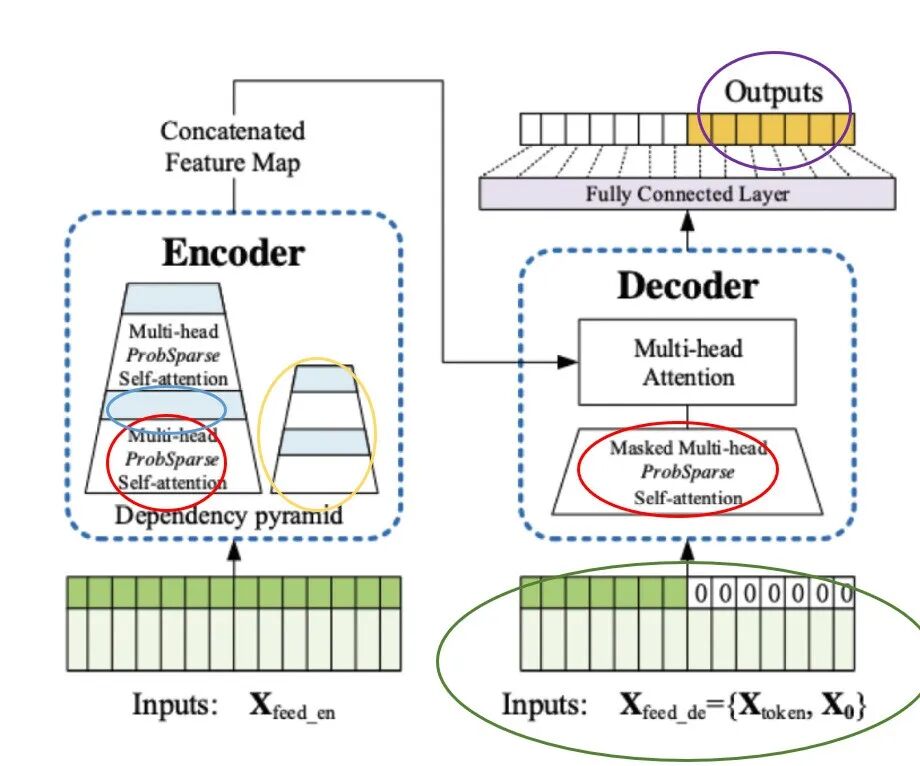
经典Transformer面临的挑战
然而,将原版Transformer直接应用于时间序列预测面临两大核心挑战:
- 二次方计算复杂度:自注意力机制的计算和内存复杂度与输入序列长度 L 的平方O(L^2)成正比 。对于通常包含数千甚至数万个时间点的长序列时间序列(LSTF)预测任务,这种复杂度是不可接受的。
- 时间序列特性失配:原版Transformer为处理离散的文本符号而设计,缺乏对时间序列连续性、局部上下文信息、以及多尺度周期性等关键特性的有效建模。
为了克服这些挑战,研究者们从不同角度出发,提出了一系列创新的Transformer变体。
演进路线:从效率优化到大规模预训练
基于Transformer的时间序列模型演进大致遵循以下路径:
- 效率优化:早期研究聚焦于降低自注意力机制的计算复杂度,代表模型包括Informer、Autoformer、FEDformer等。
- 表征学习:中期研究转向如何更好地表示时间序列,Patching思想应运而生,将时间序列分割成块进行处理,催生了PatchTST、TimesNet等模型。
- 架构探索:研究者们探索了混合架构(如LSTM-Transformer)、新的注意力机制(DeformableTST)以及不同的维度建模方式(iTransformer)。
- 大规模预训练:当前最前沿的趋势是构建时间序列基础模型,利用海量数据进行预训练,以实现强大的零样本泛化能力,如TimeGPT、Chronos、MOMENT等。
Transformer效率优化:处理长序列的探索
这类模型的共同目标是解决原生Transformer在长序列上的计算瓶颈,使其能够高效地应用于LSTF任务。