基于BERT类的MRPC语义相似度检测(从0到-1系列)
基于BERT类的MRPC语义相似度检测(从0到-1系列)
介绍
BERT(Bidirectional Encoder Representations from Transformers)是由Google开发的一种预训练模型,它是一种基于Transformer机制的深度双向模型,可以对大规模文本数据进行无监督预训练,然后在各种NLP任务中进行微调。BERT 模型在多项自然语言处理任务上取得了巨大成功,成为了NLP 领域里的一个重要里程碑。
语意相似度检测任务是NLP领域中一项重要的任务,它旨在判断两个文本片段之间的语义相似程度。在这项任务中,我们需要输入两个文本片段,然后输出一个相似度分数,表示这两个文本片段之间的语义相似程度。语义相似度检测任务在很多NLP应用中非常有用,比如信息检索、问答系统、自动摘要等领域。
BERT 在语意相似度检测任务中的应用非常成功,通过将两个文本片段拼接并输入到BERT模型中,可以得到两个文本片段的语义表示,然后通过一些微调层或者特定的输出层进行语义相似度的判断。BERT 模型具有强大的语义表达能力,可以有效地捕捉文本之间的语义信息,因此在语义相似度检测任务中取得了很好的效果。
数据预处理
分析数据基本结构
Quality #1 ID #2 ID #1 String #2 String
1 702876 702977 Amrozi accused his brother , whom he called " the witness " , of deliberately distorting his evidence . Referring to him as only " the witness " , Amrozi accused his brother of deliberately distorting his evidence .
0 2108705 2108831 Yucaipa owned Dominick 's before selling the chain
to Safeway in 1998 for $ 2.5 billion . Yucaipa bought Dominick 's in
1995 for $ 693 million and sold it to Safeway for $ 1.8 billion in
1998 .
数据由五个列组合而成,其中 ID 这一属性对该任务无明显作用,故使用 py 脚本剔除,python脚本如下:
#!/usr/bin/env python
# -*- coding:utf-8 -*-
# author: bruanlin
# datetime: 2025/4/23 13:44
# software: PyCharm
# project: [Bert-mrpc]-[data_trasform]
""" Code Describe :nothing!!
"""import pandas as pd
from typing import Tuple
import logging
import os
from pathlib import Path# 配置日志记录
logging.basicConfig(level=logging.INFO)
logger = logging.getLogger(__name__)def load_mrpc_data(file_path: str) -> Tuple[pd.DataFrame, int]:"""加载MRPC数据集"""try:# 显式指定列类型防止自动类型推断错误dtype_spec = {'#1 ID': 'string','#2 ID': 'string','#1 String': 'string','#2 String': 'string','Quality': 'int8'}# 分块读取大文件(适用于Colab内存受限情况)chunks = pd.read_csv(file_path,sep='\t',header=0,dtype=dtype_spec,usecols=['Quality', '#1 String', '#2 String'], # 明确指定需要列chunksize=1000,on_bad_lines='warn' # 跳过格式错误行)df = pd.concat(chunks)except FileNotFoundError:logger.error(f"文件未找到: {file_path}")raiseexcept pd.errors.ParserError as e:logger.error(f"TSV解析错误: {str(e)}")raise# 记录初始行数original_rows = df.shape[0]# 数据清洗df = df.dropna(subset=['#1 String', '#2 String']) # 删除空值行df = df.rename(columns={'Quality': 'label','#1 String': 'sentence1','#2 String': 'sentence2'})# 记录清洗结果cleaned_rows = df.shape[0]logger.info(f"数据清洗完成: 原始行数={original_rows}, 有效行数={cleaned_rows}, "f"丢弃行数={original_rows - cleaned_rows}")return df.reset_index(drop=True), (original_rows - cleaned_rows)def save_processed_data(df: pd.DataFrame,output_dir = "processed_data",file_name = "mrpc_processed",formats ='tsv') -> None:"""保存数据"""# 创建输出目录Path(output_dir).mkdir(parents=True, exist_ok=True)# 确保列顺序正确df = df[['label', 'sentence1', 'sentence2']]# 保存不同格式try:full_path = os.path.join(output_dir, f"{file_name}.{formats}")if formats == 'tsv':# TSV格式(默认格式)df.to_csv(full_path,sep='\t',index=False,header=True, # 根据需求调整quoting=3, # 与原始数据一致escapechar='\\')elif formats == 'csv':# CSV格式(带列名)df.to_csv(full_path,index=False,quotechar='"',escapechar='\\')else:raise ValueError(f"不支持的格式: {formats}")print(f"成功保存 {full_path} ({os.path.getsize(full_path) / 1024:.1f}KB)")except Exception as e:print(f"保存 {formats} 格式失败: {str(e)}")# 使用示例
if __name__ == "__main__":try:train_df, train_dropped = load_mrpc_data("DATASET/MRPC/train.tsv")dev_df, dev_dropped = load_mrpc_data("DATASET/MRPC/dev.tsv")# 展示样本结构print("\n训练集样例:")print(train_df[['label', 'sentence1', 'sentence2']].head(3))# 数据分布分析print("\n标签分布:")print(train_df['label'].value_counts(normalize=True))# 保存数据try:# 保存训练集数据save_processed_data(train_df,"./DATASET/train_processed","train_processed_mrpc","tsv")save_processed_data(dev_df,"./DATASET/dev_processed","dev_processed_mrpc","tsv")except Exception as e:logger.error(f"保存数据失败: {e}")except Exception as e:logger.error("数据加载失败,请检查文件路径和格式")剔除后的实验数据如下:
label sentence1 sentence2
1 He said the foodservice pie business doesn 't fit the company 's
long-term growth strategy . The foodservice pie business does not fit
our long-term growth strategy .
0 The dollar was at 116.92 yen against the yen , flat on
the session , and at 1.2891 against the Swiss franc , also flat . The
dollar was at 116.78 yen JPY = , virtually flat on the session , and
at 1.2871 against the Swiss franc CHF = , down 0.1 percent .
创建 dataset 和 dataloader
# 参数设置
Max_length = 128
Batch_size = 32
Lr = 2e-5
Epochs = 10
Model_name = 'bert-base-uncased'
train_tsv_path = "/kaggle/input/mrpc-bert/train_processed_mrpc.tsv"
dev_tsv_path = "/kaggle/input/mrpc-bert/dev_processed_mrpc.tsv"
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')# 加载
def load_mrpc_data(file_path):"""加载并预处理MRPC TSV文件"""try:chunks = pd.read_csv(file_path,sep='\t',header=0,dtype=str,usecols=['label', 'sentence1', 'sentence2'], # 关键修改点chunksize=1000,on_bad_lines='warn')df = pd.concat(chunks)# 类型转换df['label'] = pd.to_numeric(df['label'], errors='coerce').astype('Int8')df = df.dropna().reset_index(drop=True)return dfexcept Exception as e:print(f"Error: {e}")return None # 确保异常时返回明确空值# 创建自定义Dataset
class MRPCDataset(Dataset):def __init__(self, dataframe, tokenizer, max_len):self.data = dataframeself.tokenizer = tokenizerself.max_len = max_lendef __len__(self):return len(self.data)def __getitem__(self, index):# 提取单行数据row = self.data.iloc[index]sentence1 = str(row['sentence1'])sentence2 = str(row['sentence2'])label = int(row['label'])# 分词与编码encoding = self.tokenizer.encode_plus(text=sentence1,text_pair=sentence2,add_special_tokens=True, # 添加[CLS], [SEP]max_length=self.max_len,padding='max_length',truncation=True,return_tensors='pt', # 返回PyTorch Tensorreturn_token_type_ids=True,return_attention_mask=True)return {'input_ids': encoding['input_ids'].flatten(),'attention_mask': encoding['attention_mask'].flatten(),'token_type_ids': encoding['token_type_ids'].flatten(),'label': torch.tensor(label, dtype=torch.long)}# 初始化组件
tokenizer = BertTokenizer.from_pretrained(Model_name,cache_dir="./huggingface_models", # 指定缓存目录mirror='https://mirror.sjtu.edu.cn/huggingface' # 上海交大镜像)
df = load_mrpc_data(train_tsv_path)
dataset = MRPCDataset(df, tokenizer, max_len=Max_length)# 创建DataLoader
dataloader = DataLoader(dataset,batch_size=Batch_size,shuffle=True,num_workers=4, # 多进程加载pin_memory=True # 加速GPU传输
)# 加载验证集
dev_df = load_mrpc_data(dev_tsv_path)
dev_dataset = MRPCDataset(dev_df, tokenizer, Max_length)
dev_dataloader = DataLoader(dev_dataset,batch_size=Batch_size,shuffle=False,num_workers=2
)
训练
训练指标
训练平台 kaggle-GPUT4
优化器 Adamw
Max_length 128
Batch_size 32
Lr 2e-5
Epochs 30# ====================创建训练组件===============
model = BertForSequenceClassification.from_pretrained(Model_name,num_labels=2, # 二分类任务force_download=True, # 强制重新下载mirror='https://mirror.sjtu.edu.cn/huggingface',cache_dir="./huggingface_models"
)
model.to(device)# ===============优化器 ==================
# 修改优化器初始化代码
optimizer = AdamW(model.parameters(), lr=Lr, weight_decay=0.01)
total_steps = len(dataloader) * Epochs
scheduler = get_linear_schedule_with_warmup(optimizer,num_warmup_steps=0,num_training_steps=total_steps
)训练函数
def train_epoch(model, dataloader, optimizer, scheduler, device):model.train()total_loss = 0progress_bar = tqdm(dataloader, desc="Training", leave=False)for batch in progress_bar:optimizer.zero_grad()input_ids = batch['input_ids'].to(device)attention_mask = batch['attention_mask'].to(device)token_type_ids = batch['token_type_ids'].to(device)labels = batch['label'].to(device)outputs = model(input_ids=input_ids,attention_mask=attention_mask,token_type_ids=token_type_ids,labels=labels)loss = outputs.losstotal_loss += loss.item()loss.backward()torch.nn.utils.clip_grad_norm_(model.parameters(), 1.0)optimizer.step()scheduler.step()progress_bar.set_postfix({'loss': f"{loss.item():.4f}"})return total_loss / len(dataloader)
验证函数
def evaluate(model, dataloader, device):model.eval()total_loss = 0predictions = []true_labels = []with torch.no_grad():for batch in tqdm(dataloader, desc="Evaluating", leave=False):input_ids = batch['input_ids'].to(device)attention_mask = batch['attention_mask'].to(device)token_type_ids = batch['token_type_ids'].to(device)labels = batch['label'].to(device)outputs = model(input_ids=input_ids,attention_mask=attention_mask,token_type_ids=token_type_ids,labels=labels)loss = outputs.losstotal_loss += loss.item()logits = outputs.logitspreds = torch.argmax(logits, dim=1)predictions.extend(preds.cpu().numpy())true_labels.extend(labels.cpu().numpy())accuracy = accuracy_score(true_labels, predictions)f1 = f1_score(true_labels, predictions)avg_loss = total_loss / len(dataloader)return avg_loss, accuracy, f1if __name__ == "__main__":# 查看第一个batchsample_batch = next(iter(dataloader))print(f"Batch输入尺寸:")print(f"Input IDs: {sample_batch['input_ids'].shape}")print(f"Attention Mask: {sample_batch['attention_mask'].shape}")print(f"Token Type IDs: {sample_batch['token_type_ids'].shape}")print(f"Labels: {sample_batch['label'].shape}")# 输出示例print("\n解码第一个样本:")print(tokenizer.decode(sample_batch['input_ids'][0]))print(f"======== training model ===========")# 主训练循环# 初始化指标存储列表metrics_data = []best_f1 = 0for epoch in range(Epochs):print(f"\nEpoch {epoch + 1}/{Epochs}")print("-" * 40)# 训练阶段train_loss = train_epoch(model, dataloader, optimizer, scheduler, device)print(f"Train Loss: {train_loss:.4f}")# 验证阶段val_loss, val_acc, val_f1 = evaluate(model, dev_dataloader, device)print(f"Val Loss: {val_loss:.4f} | Accuracy: {val_acc:.4f} | F1: {val_f1:.4f}")# 记录指标metrics_data.append({'Epoch': epoch + 1,'Train Loss': round(train_loss, 4),'Val Loss': round(val_loss, 4),'Accuracy': round(val_acc, 4),'F1 Score': round(val_f1, 4)})metrics_df = pd.DataFrame([metrics_data[-1]]) # 只取最新数据if epoch == 0:metrics_df.to_excel("training_metrics.xlsx", index=False)else:with pd.ExcelWriter("training_metrics.xlsx", mode='a', engine='openpyxl',if_sheet_exists='overlay') as writer:metrics_df.to_excel(writer, index=False, header=False, startrow=epoch + 1)# 保存最佳模型if val_f1 > best_f1:best_f1 = val_f1model.save_pretrained("./best_model")tokenizer.save_pretrained("./best_model")print(f"New best model saved with F1: {val_f1:.4f}")print("\nTraining completed!")print(f"Best Validation F1: {best_f1:.4f}")
总体结果与实验总结
采用预训练模型bert-base-uncased,在数据集 MRPC 上测试得到的情况如下:
| Train Loss | 0.0024 |
|---|---|
| Val Loss | 1.6600 |
| Accuracy | 0.8247 |
| Val Loss | 0.8811 |
| F1 | 0.0024 |
| Best Validation F1 | 0.8862 |
分析比对现有方法,形成简单的总结报告,想办法提升性能(不一定要比所有方法都好,接近即可),制作表格,自己方法与其他方法的性能对比。
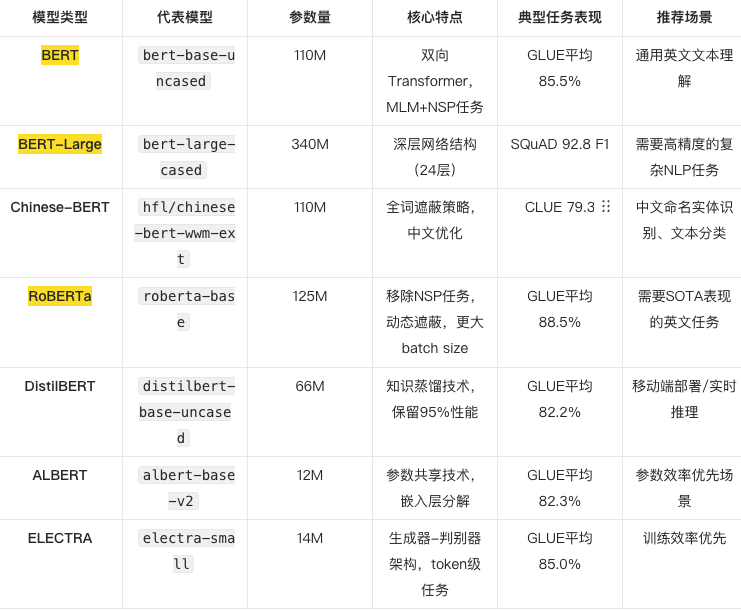
相似度检测任务的现有方法
模型对比
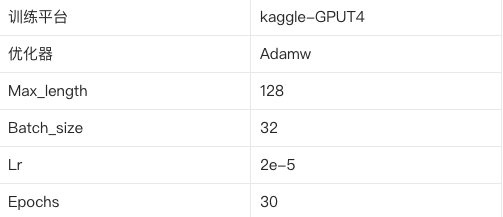
训练结果如下,超参数设置如下
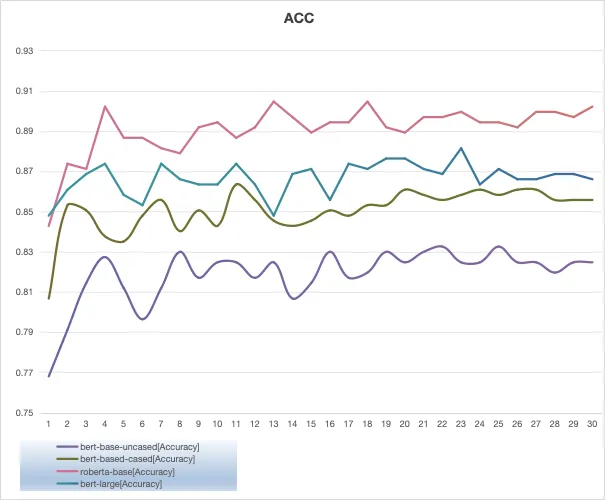
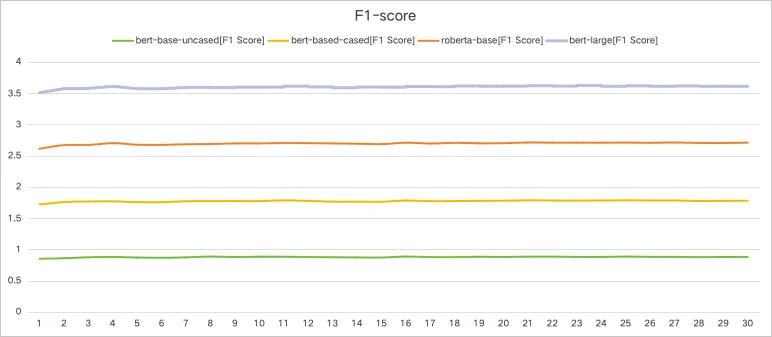
总结对比
优化改进
| 数据 | 数据增强 |
|---|---|
| 训练过程 | AdamW 分层学习率设置 |
| 训练过程 | 超参数搜索 |
| 模型 | 模型集成 |
数据增强

分层学习率
def create_model(model_name, num_labels=2):"""创建带分层参数的模型"""model = AutoModelForSequenceClassification.from_pretrained(model_name,num_labels=num_labels)# 参数分组no_decay = ["bias", "LayerNorm.weight"]optimizer_grouped_parameters = [{"params": [p for n, p in model.named_parameters()if "embeddings" in n and not any(nd in n for nd in no_decay)],"lr": config['lr'] * 0.1,"weight_decay": 0.0},{"params": [p for n, p in model.named_parameters()if "classifier" in n],"lr": config['lr'] * 10,"weight_decay": 0.01}]return model, optimizer_grouped_parameters
● 分层逻辑
○ 排除动态学习率
■ Bias参数:偏移量不需要正则化(过大的L2惩罚会降低模型灵活性)
■ LayerNorm参数:标准化层权重已自带缩放机制,额外正则化可能破坏分布
○ 词嵌入层的学习率设置:“lr”: config[‘lr’] * 0.1,“weight_decay”: 0.0
○ 分类器学习率设置: “lr”: config[‘lr’] * 10,“weight_decay”: 0.01
超参数搜索
def objective(trial):"""Optuna超参数优化目标函数"""# 超参数建议范围config.update({'lr': trial.suggest_float('lr', 1e-6, 5e-5, log=True),'batch_size': trial.suggest_categorical('batch_size', [16, 32, 64]),'aug_prob': trial.suggest_float('aug_prob', 0.1, 0.3)})# 初始化模型集合models = []optimizers = []schedulers = []for model_name in config['model_names']:model, params = create_model(model_name)model.to(device)optimizer = AdamW(params)scheduler = get_linear_schedule_with_warmup(optimizer,num_warmup_steps=100,num_training_steps=len(train_loader) * config['epochs'])models.append(model)optimizers.append(optimizer)schedulers.append(scheduler)# 训练循环best_f1 = 0for epoch in range(config['epochs']):for model, optimizer, scheduler in zip(models, optimizers, schedulers):train_epoch(model, train_loader, optimizer, scheduler, device)metrics = evaluate_ensemble(models, dev_loader, device)trial.report(metrics['f1'], epoch)if metrics['f1'] > best_f1:best_f1 = metrics['f1']if trial.should_prune():raise optuna.TrialPruned()return best_f1模型集成评估
"model_names": ['bert-base-uncased','roberta-base','google/electra-small-discriminator'],
"ensemble_weights": [0.4, 0.3, 0.3]def evaluate_ensemble(models, dataloader, device):"""集成模型评估"""all_logits = []true_labels = []for model in models:model.eval()model_logits = []with torch.no_grad():for batch in tqdm(dataloader):inputs = {k: v.to(device) for k, v in batch.items() if k != 'label'}outputs = model(**inputs)model_logits.append(outputs.logits.cpu().numpy())if len(true_labels) == 0:true_labels.extend(batch['label'].cpu().numpy())all_logits.append(np.concatenate(model_logits))# 加权集成weighted_logits = np.zeros_like(all_logits[0])for i, weight in enumerate(config['ensemble_weights']):weighted_logits += all_logits[i] * weightpredictions = np.argmax(weighted_logits, axis=1)return {'accuracy': accuracy_score(true_labels, predictions),'f1': f1_score(true_labels, predictions)}