数据库 AI 助手测评:Chat2DB、SQLFlow 等工具如何提升开发效率?
一、引言:数据库开发的 “效率革命” 正在发生
在某互联网金融公司的凌晨故障现场,资深 DBA 正满头大汗地排查一条执行超时的 SQL—— 该语句涉及 7 张核心业务表的复杂关联,因索引缺失导致全表扫描,最终引发交易系统阻塞。这类场景在传统数据库开发中屡见不鲜:据 Gartner 调研,开发人员 43% 的时间消耗在 SQL 编写与调优,32% 的生产故障源于 SQL 性能问题,而跨数据库方言适配更让开发效率降低 40% 以上。
随着 AIGC 技术的成熟,数据库 AI 助手应运而生。阿里 Chat2DB、微软 SQLFlow、开源项目 DB-GPT 等工具的出现,正在重塑数据库开发范式:某中型电商实测显示,AI 助手使 SQL 编写效率提升 68%,跨库迁移成本下降 75%,慢 SQL 优化周期从 4 小时缩短至 15 分钟。本文将从技术原理、工具测评、实战案例、生态构建四个维度,深度解析数据库 AI 助手如何重构开发生产力。
二、传统数据库开发的 “不可能三角” 困境
2.1 技术壁垒:从语法差异到复杂逻辑的层层关卡
(1)跨库方言的 “翻译鸿沟”
| 数据库 | 分页语法 | 字符串模糊匹配 | 序列生成方式 | ||||
|---|---|---|---|---|---|---|---|
| MySQL | LIMIT OFFSET | LIKE %?% | AUTO_INCREMENT | ||||
| PostgreSQL | LIMIT OFFSET | ILIKE %?% | SERIAL8 | ||||
| Oracle | ROWNUM <= ? | LIKE '%' | ? | '%' | CREATE SEQUENCE | ||
| SQL Server | OFFSET ? ROWS FETCH NEXT | LIKE '%' + ? + '%' | IDENTITY(1,1) |
某跨境电商需同时维护 MySQL(主库)、PostgreSQL(日志库)、Oracle(旧系统),开发团队需为同一查询编写 3 套 SQL,仅语法适配就消耗 20% 的开发时间。
(2)复杂查询的 “知识壁垒”
- 多表关联:超过 5 张表的 JOIN 操作,开发人员平均需要查阅 3 次文档,出错率达 28%
- 窗口函数:
ROW_NUMBER()/RANK()/DENSE_RANK()的适用场景混淆,导致排序逻辑错误 - CTE 递归:在物料清单(BOM)查询等场景中,递归 CTE 的语法误用可能引发性能灾难
2.2 经验依赖:性能调优的 “黑箱” 困境
(1)索引优化的 “试错迷宫”
传统索引优化流程:
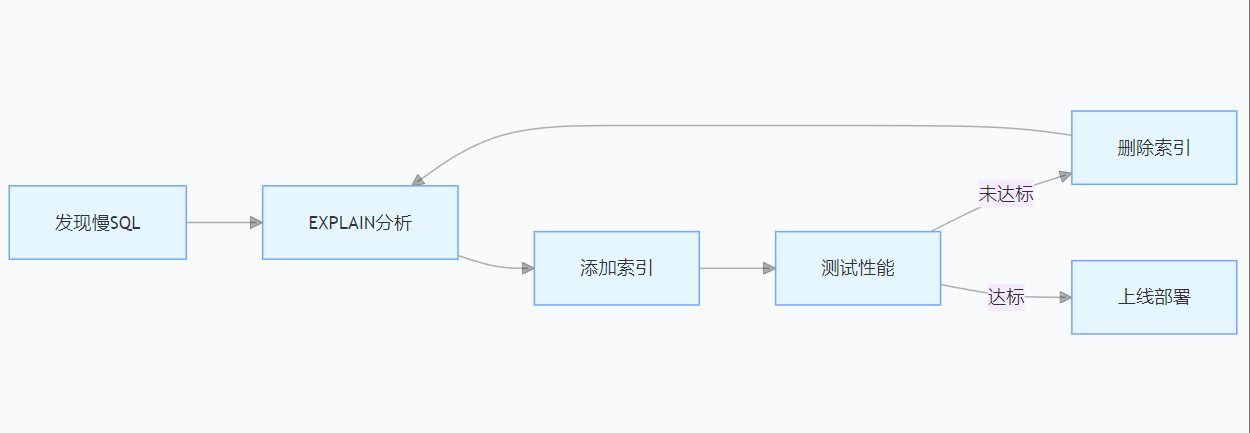
某零售企业曾为订单查询语句尝试 5 次索引组合,耗时 2 天,最终通过 AI 助手一次生成最优索引。
(2)执行计划的 “经验门槛”
解读 EXPLAIN 输出需要掌握:
- 访问类型(ALL/INDEX/Range/Ref)的性能差异
- 关联算法(Nested Loop/Hash Join/Merge Join)的适用场景
- 成本计算(cost 值的构成与优化方向)
初级工程师误判率超过 60%,导致优化方向南辕北辙。
2.3 协作割裂:数据需求的 “失真传递”
业务人员与开发人员的需求沟通存在三层损耗:
- 语义转换:“统计各地区复购率” 需转化为 “识别 90 天内重复购买的用户 ID”
- 字段映射:业务术语 “客户编号” 对应数据库字段 “cust_id”
- 逻辑细化:“复购” 需明确 “同一用户购买同一商品” 或 “任意商品”
某教育平台因需求理解偏差,报表开发返工率高达 45%,平均每个需求需 3.2 轮沟通。
三、主流数据库 AI 助手技术解析与横向测评
3.1 全链路智能工具:阿里 Chat2DB(企业级首选)
(1)技术架构:三层智能引擎驱动
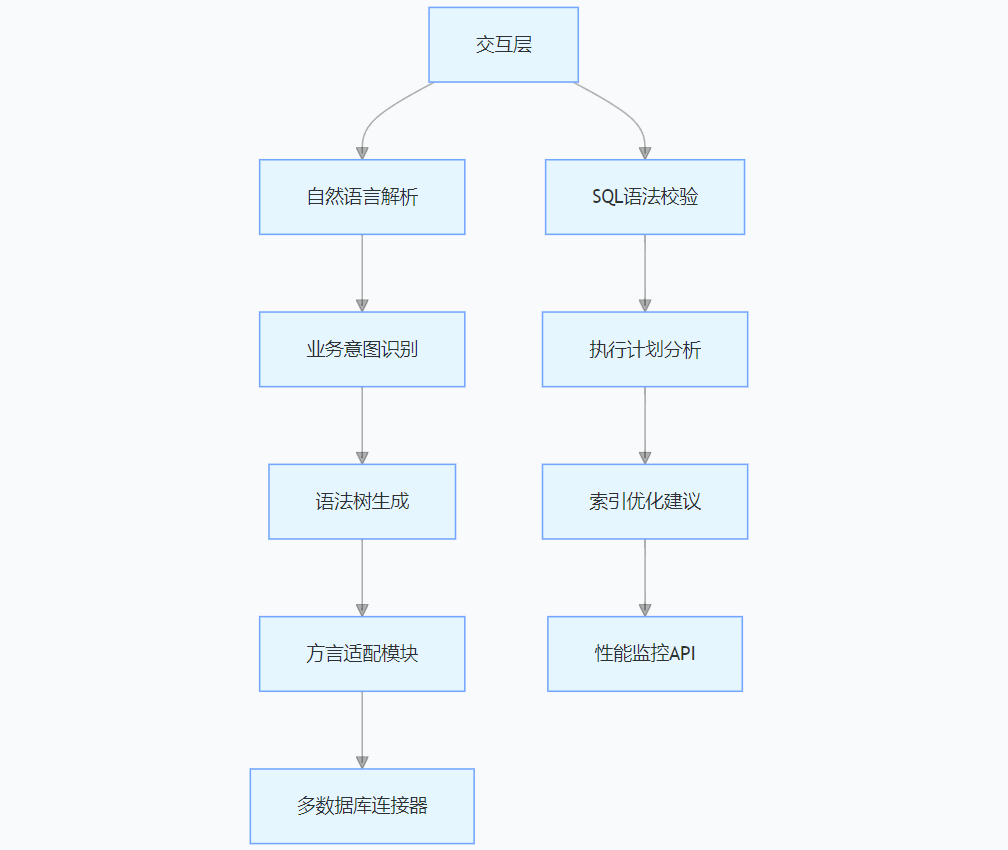
- NL2SQL 引擎:基于 T5 模型微调,支持 20 + 数据库方言,复杂查询生成准确率达 92%
python
# 自然语言转SQL示例(含窗口函数) input: