开源 RAG 框架对比:LangChain、Haystack、DSPy 技术选型指南
一、引言
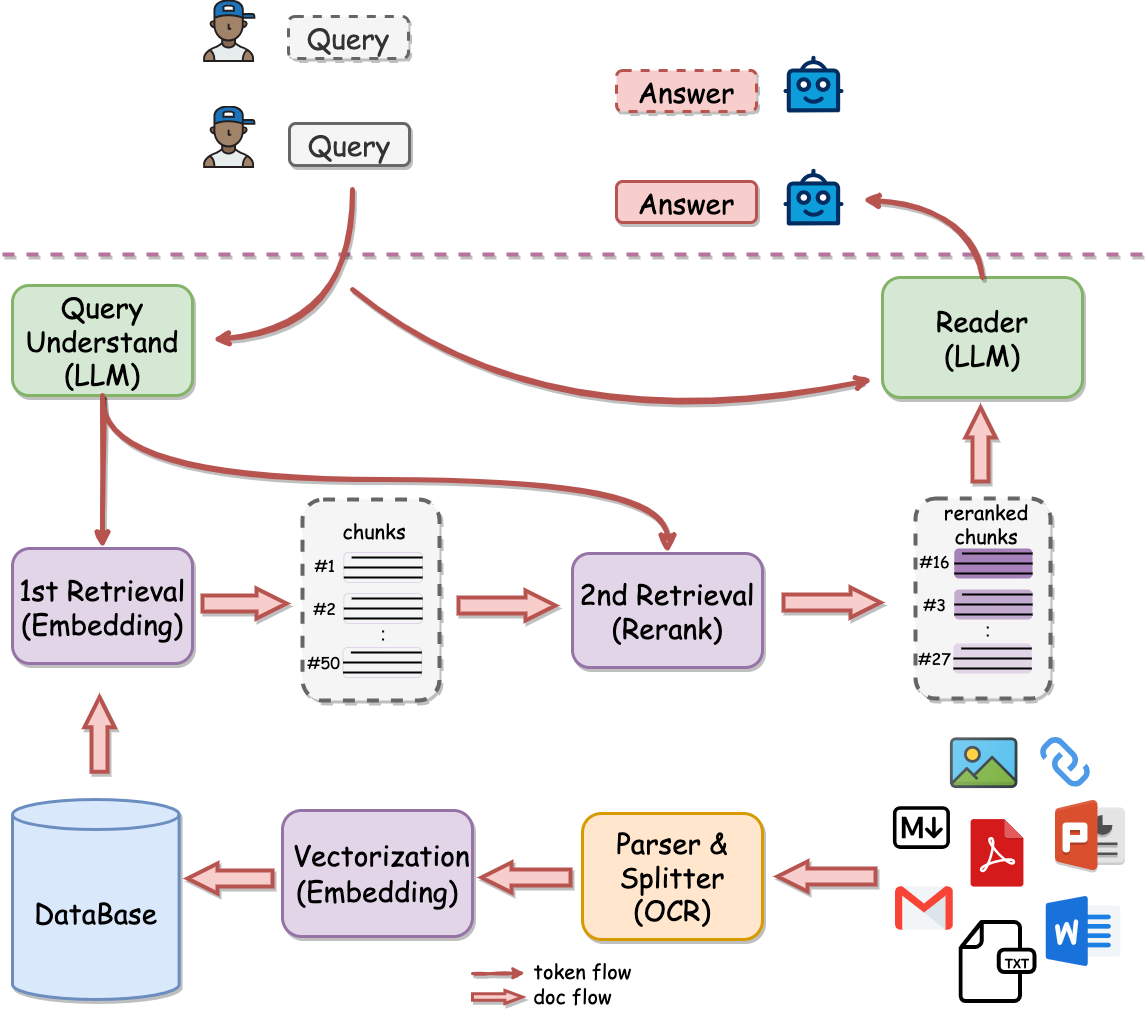
检索增强生成(RAG)通过结合大语言模型(LLM)与外部知识库,显著提升了模型在专业领域和时效性问题上的准确性。本文将从技术架构、核心功能、适用场景等维度对比分析 LangChain、Haystack、DSPy 三大开源 RAG 框架,为开发者提供选型参考。
二、框架核心特性对比
| 维度 | LangChain | Haystack | DSPy |
|---|---|---|---|
| 架构设计 | 模块化链式结构,支持动态组合工具和链 | 基于管道的组件化架构,支持混合检索和多模态处理 | 声明式编程范式,通过编译器自动优化 RAG 流水线 |
| 核心功能 | 工具集成、提示工程、多模态支持 | 文档检索、多模态问答、生产级部署优化 | 自动提示生成、检索策略优化、小模型增强 |
| 易用性 | 高阶 API 友好,适合快速原型开发 | 提供可视化调试工具,支持低代码配置 | 声明式语法降低开发门槛,自动优化减少人工调优 |
| 扩展性 | 支持 700 + 三方工具集成,生态丰富 | 支持 K8s 原生部署,适合大规模数据处理 | 模块化架构支持动态替换组件,适配不同场景 |
| 性能优化 | 流式处理、异步支持 | GPU 加速、混合检索(向量 + 关键词) | 自动调优器(如 MIPROv2)提升检索效率,减少 LLM 调用次数 |
| 社区支持 | GitHub 星标超 40k,活跃开发者社区 | 企业级案例丰富(IBM、Elsevier) | 学术研究驱动,斯坦福大学等机构支持 |
三、框架深度解析
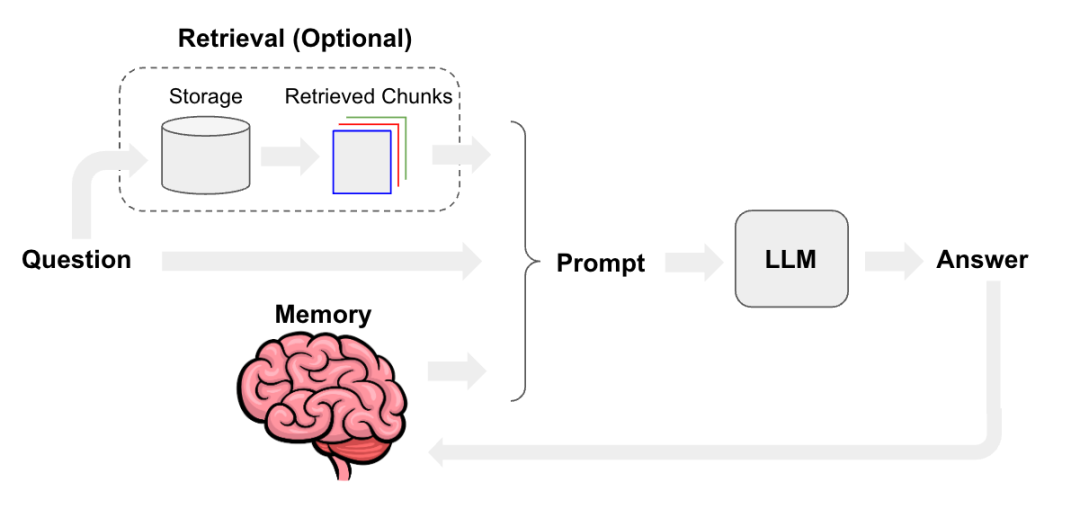
1. LangChain:灵活性与生态优势
- 核心优势:
- 工具链集成:支持 OpenAI、Anthropic 等 LLM,以及 Pinecone、Weaviate 等向量数据库,提供 700 + 三方工具集成。
- 动态组合:通过 LCEL 语言实现链式结构的灵活定制,支持批处理和并行化。
- 可观察性:集成 LangSmith 提供日志追踪和调试功能,支持细化到组件的输入输出分析。
- 典型场景:
- 快速原型开发:利用预制链(如
ConversationalRetrievalChain)快速搭建问答系统。 - 复杂逻辑处理:结合代理(Agent)实现多步推理,如电商客服中的订单查询与促销规则整合。
- 快速原型开发:利用预制链(如
- 局限性:
- 对新手友好但深度定制需较高学习成本。
- 大规模数据处理时性能依赖外部优化(如向量数据库调优)。
2. Haystack:生产级检索与多模态能力
- 核心优势:
- 检索优化:支持 BM25、语义检索混合策略,结合 HNSW 索引实现十亿级数据毫秒级响应。
- 多模态支持:原生处理 PDF 表格、图片等非结构化数据,适合医疗、法律等专业领域。
- 企业级特性:提供 K8s 工作流、监控模块和缓存机制,支持高并发场景。
- 典型场景:
- 医疗问答:整合医学文献和病历,生成个性化治疗建议,错误率降低 25%。
- 教育智能辅导:解析教材并动态推荐练习题,知识点掌握率提升 40%。
- 局限性:
- 配置复杂度较高,需专业知识优化检索参数。
- 对 LLM 的支持依赖第三方 API,本地部署需额外配置。
3. DSPy:声明式编程与自动化优化
- 核心优势:
- 声明式架构:通过 Python 代码定义 RAG 逻辑,编译器自动生成提示或微调模型,减少手动调优。
- 自动优化:MIPROv2 优化器通过引导、提案、搜索三阶段提升检索效率,减少 LLM 调用次数。
- 小模型增强:利用小型模型(如 T5-base)实现与 GPT-3.5 相当的性能,降低成本。
- 典型场景:
- 数学推理:在 GSM8K 数据集上,DSPy 生成的提示链性能优于专家设计方案 54%。
- 多模态检索:支持文本、图像、音频混合检索,适合媒体内容管理。
- 局限性:
- 生态相对年轻,社区资源较少。
- 对复杂业务逻辑的支持尚在完善中。
四、技术选型建议
| 场景 | 推荐框架 | 理由 |
|---|---|---|
| 快速原型开发 | LangChain | 高阶 API 和丰富工具链加速开发,适合验证业务逻辑。 |
| 多模态数据处理 | Haystack | 原生支持 PDF、图片解析,医疗、法律等专业场景表现优异。 |
| 自动化优化 | DSPy | 声明式编程和自动调优器减少人工干预,适合数学推理、多模态检索等复杂任务。 |
| 企业级生产部署 | Haystack | K8s 支持、监控模块和缓存机制确保高可用性,适合高并发场景。 |
| 小模型低成本方案 | DSPy | 利用小型模型实现与大模型相当的性能,降低计算资源需求。 |
| 复杂逻辑与工具集成 | LangChain | 灵活的链式结构和 700 + 工具集成,适合电商客服、数据分析等多环节协同场景。 |
五、性能与成本对比
| 指标 | LangChain | Haystack | DSPy |
|---|---|---|---|
| 响应时间 | 中(依赖向量库) | 高(混合检索优化) | 高(自动调优器) |
| 吞吐量 | 中(异步支持) | 高(K8s 部署) | 中(小模型优先) |
| 资源消耗 | 高(大模型依赖) | 中(GPU 加速) | 低(小型模型) |
| 开发成本 | 低(快速上手) | 中(专业配置) | 低(声明式语法) |
六、总结
- LangChain:适合快速迭代和多样化场景,尤其适合需要灵活组合工具链的开发者。
- Haystack:在企业级部署和多模态处理上表现优异,医疗、法律等专业领域首选。
- DSPy:通过声明式编程和自动化优化降低开发门槛,适合数学推理、多模态检索等复杂任务。
建议根据项目需求综合评估:原型开发选 LangChain,生产部署选 Haystack,小模型优化选 DSPy。三者可互补使用,例如用 LangChain 快速搭建原型,再迁移至 Haystack 进行性能优化,或结合 DSPy 提升特定任务的检索效率。