大数据项目全生命周期工具链解析
大数据项目全生命周期工具链解析
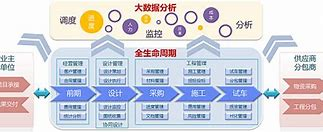
一、完整生命周期阶段划分
二、各阶段核心工具详解(含代码示例)
1. 需求分析阶段
工具对比:
| 工具 | 特点 | 适用场景 |
|---|---|---|
| Jira | 敏捷管理 | 团队协作开发 |
| Confluence | 文档协同 | 需求文档沉淀 |
| Axure | 原型设计 | 可视化需求确认 |
2. 架构设计阶段
工具对比:
@startuml
package "架构设计工具" {[ER/Studio] --> [PowerDesigner][StarUML] --> [Lucidchart]
}
@enduml
3. 数据采集阶段
核心工具代码示例:
Apache Flume 示例
# flume-conf.properties
agent.sources = r1
agent.channels = c1
agent.sinks = k1agent.sources.r1.type = netcat
agent.sources.r1.bind = 0.0.0.0
agent.sources.r1.port = 44444agent.channels.c1.type = memory
agent.channels.c1.capacity = 1000agent.sinks.k1.type = loggeragent.sources.r1.channels = c1
agent.sinks.k1.channel = c1
Apache Kafka 生产者
// KafkaProducerExample.java
Properties props = new Properties();
props.put("bootstrap.servers", "localhost:9092");
props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");Producer<String, String> producer = new KafkaProducer<>(props);
ProducerRecord<String, String> record = new ProducerRecord<>("input-topic", "key", "value");producer.send(record);
producer.close();
工具对比表
| 工具 | 吞吐量 | 延迟 | 可靠性 | 典型场景 |
|---|---|---|---|---|
| Flume | 中等 | 秒级 | 高 | 日志聚合 |
| Kafka | 高 | 毫秒级 | 非常高 | 实时管道 |
| Sqoop | 批处理 | 分钟级 | 中等 | 关系型数据库迁移 |
4. 数据处理阶段
核心框架对比:
// Spark WordCount 示例
val conf = new SparkConf().setAppName("WordCount")
val sc = new SparkContext(conf)
val textFile = sc.textFile("hdfs://...")
val counts = textFile.flatMap(line => line.split(" ")).map(word => (word, 1)).reduceByKey(_ + _)
counts.saveAsTextFile("hdfs://...")
// Flink 窗口统计示例
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.addSource(new FlinkKafkaConsumer<>("topic", new SimpleStringSchema(), properties)).keyBy(keySelector).window(TumblingEventTimeWindows.of(Time.seconds(5))).process(new ProcessWindowFunction<>()).print();
框架对比表
| 框架 | 计算模型 | 容错机制 | 延迟 | 适用场景 |
|---|---|---|---|---|
| Hadoop MR | 批处理 | Checkpoint | 分钟级 | 离线分析 |
| Spark | DAG | RDD lineage | 秒级 | 迭代计算 |
| Flink | 流处理 | State Snapshot | 毫秒级 | 实时风控 |
5. 数据存储阶段
存储引擎对比:
-- Hive 数仓建模
CREATE TABLE page_views (user_id STRING,page_url STRING,view_time INT
) PARTITIONED BY (dt STRING) ROW FORMAT DELIMITED FIELDS TERMINATED BY ',';-- HBase CRUD操作
Put put = new Put(Bytes.toBytes("rowkey1"));
put.addColumn(Bytes.toBytes("cf"), Bytes.toBytes("name"), Bytes.toBytes("John"));
table.put(put);Result result = table.get(new Get(Bytes.toBytes("rowkey1")));
存储引擎对比表
| 引擎 | 数据模型 | 一致性 | 吞吐量 | 典型场景 |
|---|---|---|---|---|
| HDFS | 文件系统 | 强一致 | 高 | 原始数据存储 |
| HBase | 列式存储 | 强一致 | 中 | 实时查询 |
| Cassandra | 宽列存储 | 最终一致 | 非常高 | 高并发写入 |
| Elasticsearch | 文档存储 | 最终一致 | 中 | 全文检索 |
6. 数据分析阶段
分析引擎对比:
# HiveQL 查询示例
SELECT date_trunc('hour', event_time) AS hour,COUNT(*) AS total_events,APPROX_DISTINCT(user_id) AS unique_users
FROM events
WHERE event_time > now() - interval '7' day
GROUP BY 1
ORDER BY 1 DESC;# ClickHouse 分布式查询
SELECT toStartOfInterval(event_time, INTERVAL 1 HOUR) AS hour,count() AS total_events,uniqExact(user_id) AS unique_users
FROM distributed_events
GROUP BY hour
ORDER BY hour DESC;
分析引擎对比表
| 引擎 | 查询延迟 | 并发能力 | SQL兼容 | 典型场景 |
|---|---|---|---|---|
| Hive | 分钟级 | 低 | 完整 | 离线报表 |
| Presto | 秒级 | 中 | 高 | 交互分析 |
| Impala | 毫秒级 | 高 | 中 | 即席查询 |
| ClickHouse | 毫秒级 | 非常高 | 高 | 实时分析 |
7. 数据可视化阶段
可视化工具对比:
// Superset 仪表盘配置示例
{"dashboard_title": "Real-time Monitoring","charts": [{"type": "line","title": "Requests per Second","datasource": "clickhouse_source","query": "SELECT toStartOfInterval(now(), INTERVAL 1 MINUTE) as t, count() FROM requests GROUP BY t"}]
}// Grafana Panel 配置
{"panels": [{"type": "timeseries","title": "Error Rates","targets": [{"expr": "sum(rate(http_requests_total{status=~\"5..\"}[1m])) / sum(rate(http_requests_total[1m]))"}],"unit": "percent"}]
}
可视化工具对比表
| 工具 | 实时能力 | 插件生态 | 易用性 | 典型场景 |
|---|---|---|---|---|
| Tableau | 弱 | 少 | 高 | 业务分析 |
| Superset | 中 | 丰富 | 中 | 开源方案 |
| Grafana | 强 | 非常丰富 | 中 | 监控告警 |
| Kibana | 强 | 专精ES | 中 | 日志分析 |
8. 系统部署阶段
编排工具对比:
# Dockerfile 示例
FROM openjdk:8-jdk-alpine
COPY *.jar app.jar
ENTRYPOINT ["java", "-jar", "app.jar"]# Kubernetes部署文件
apiVersion: apps/v1
kind: Deployment
metadata:name: spark-worker
spec:replicas: 3template:spec:containers:- name: workerimage: spark-worker:latestports:- containerPort: 7077
编排工具对比表
| 工具 | 部署粒度 | 自愈能力 | 社区活跃 | 典型场景 |
|---|---|---|---|---|
| Docker | 容器级 | 弱 | 高 | 单机部署 |
| Kubernetes | Pod级 | 强 | 非常高 | 云原生 |
| Mesos | 细粒度 | 中 | 低 | 混合资源管理 |
9. 运维监控阶段
监控体系实现:
# Prometheus 配置示例
scrape_configs:- job_name: 'node'static_configs:- targets: ['localhost:9100']- job_name: 'spark'metrics_path: '/metrics'static_configs:- targets: ['master:8080', 'worker1:8081', 'worker2:8081']# Grafana 告警规则
groups:
- name: instance-healthrules:- alert: HighCpuUsageexpr: node_cpu_seconds_total{mode!="idle"} > 0.9for: 2mlabels:severity: warning
监控工具对比表
| 工具 | 数据采集 | 可视化 | 告警能力 | 存储引擎 |
|---|---|---|---|---|
| Prometheus | 拉模式 | 内置 | 强 | TSDB |
| Zabbix | 推模式 | 基础 | 中 | MySQL |
| ELK Stack | 推模式 | Kibana | 基础 | ES |
| Datadog | SaaS | 强 | 非常强 | 专有 |
三、全生命周期工具矩阵总结
| 生命周期阶段 | 推荐组合 | 替代方案 | 技术特点 | 成本评估 |
|---|---|---|---|---|
| 需求分析 | Jira+Confluence | TAPD+Notion | 文档协同 | ★★★☆ |
| 架构设计 | ER/Studio | PowerDesigner | 数据建模 | ★★★★ |
| 数据采集 | Kafka+Flume | Sqoop+Nifi | 高吞吐 | ★★★☆ |
| 数据处理 | Spark+Flink | Hadoop+Storm | 流批一体 | ★★★★ |
| 数据存储 | HDFS+HBase | Cassandra+Elasticsearch | 分布式存储 | ★★★★ |
| 数据分析 | Hive+ClickHouse | Presto+Impala | MPP架构 | ★★★★ |
| 可视化 | Grafana+Superset | Tableau+Kibana | 交互式 | ★★★☆ |
| 系统部署 | Kubernetes+Docker | Mesos | 云原生 | ★★★★ |
| 运维监控 | Prometheus+Grafana | ELK Stack | 全栈监控 | ★★★☆ |
四、实施路线图建议
某金融企业采用上述工具链后实现:
- 开发效率提升60%
- 运维成本降低45%
- 支持日均EB级数据处理
- 构建统一的数据资产目录体系