MySQL--数据引擎详解
存储引擎
MySQL体系结构
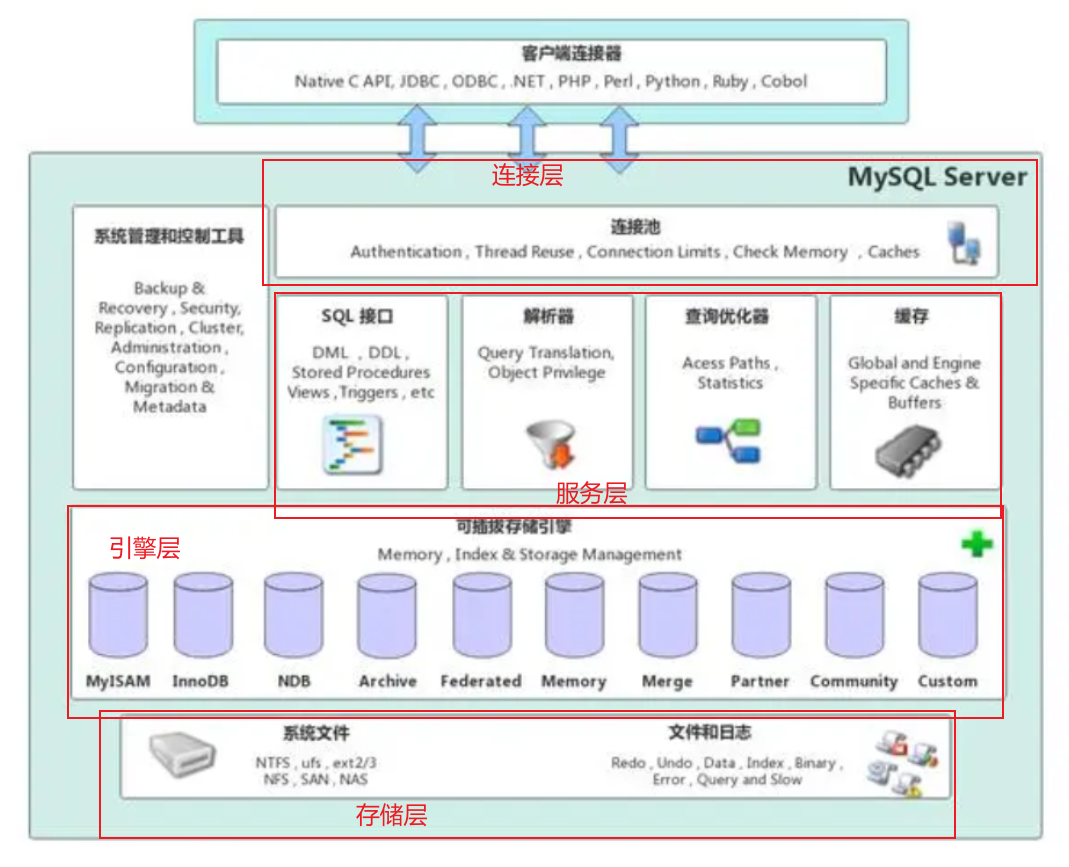
连接层:
-
主要接收客户端的连接,然后完成一些链接的处理,以及认证授权的相关操作和安全方案,还要去检查是否超过最大连接数等等,比如在连接MySQL服务器时需要输入用户名,密码,输入之后,连接层需要校验用户名与密码,授权认证之后还需要校验每一个客户端所具有的权限:例如可以操作哪些数据库,哪些表等等
服务层:
-
绝大部分的核心功能是在服务层完成的,SQL接口,查询解析器,查询优化器,查询缓存,所有跨存储引擎的功能都是在服务层完成的,如 过程,函数,等
引擎层:
-
存储引擎控制的是MySQL中数据的存储和提取的方式,服务器会通过API与存储引擎来进行通信,交互。不同的存储引擎有着不同的功能,用户可以根据自己的需要,来选择合适的存储引擎,索引(index)在存储引擎层,不同的存储引擎 索引结构不同。InnoDB引擎是MySQL5.5之后默认的存储引擎
存储层:
-
主要用来存储数据库的相关数据,并完成与存储引擎的交互,这里包含一系列的日志(redo日志,undo日志等等),存储层的数据是从存储在磁盘中
存储引擎概述
存储引擎就是存储数据、建立索引、更新/查询数据等技术的实现方式,存储引擎是基于表的,而不是基于库的,所以存储引擎也可以被称为表类型。
创建表时,指定存储引擎的语法:
-- 查询建表语句show create table student;/*CREATE TABLE `student` (`id` int NOT NULL AUTO_INCREMENT COMMENT '学号',`name` varchar(30) NOT NULL DEFAULT '匿名' COMMENT '姓名',`pwd` varchar(20) NOT NULL DEFAULT '123456' COMMENT '密码',`sex` varchar(2) NOT NULL DEFAULT '女' COMMENT '性别',`birthday` datetime DEFAULT NULL COMMENT '出生日期',`address` varchar(100) DEFAULT NULL COMMENT '家庭住址',`email` varchar(50) DEFAULT NULL COMMENT '邮箱',PRIMARY KEY (`id`)) ENGINE=InnoDB DEFAULT CHARSET=utf8mb3*/-- 查询当前数据库支持的存储引擎show engines ;
存储引擎特点
-
InnoDB
-
InnoDB是一种兼高可靠性与高性能的通用存储引擎,InnoDB引擎是MySQL5.5之后默认的存储引擎
-
-
特点
-
DML(数据操作语言)遵循ACID模型,支持事务
-
行级锁,提高并发访问性能
-
支持外键foreign key约束,保证数据的完整性与正确性
-
-
文件
-
xxx.bid:xxx代表的是表名,innodb引擎的每张表都会对应这样一个表空间文件,存储该表的表结构(frm,sdi)、数据和索引
-
参数:innodb_file_per_table
-
-
InnoDB
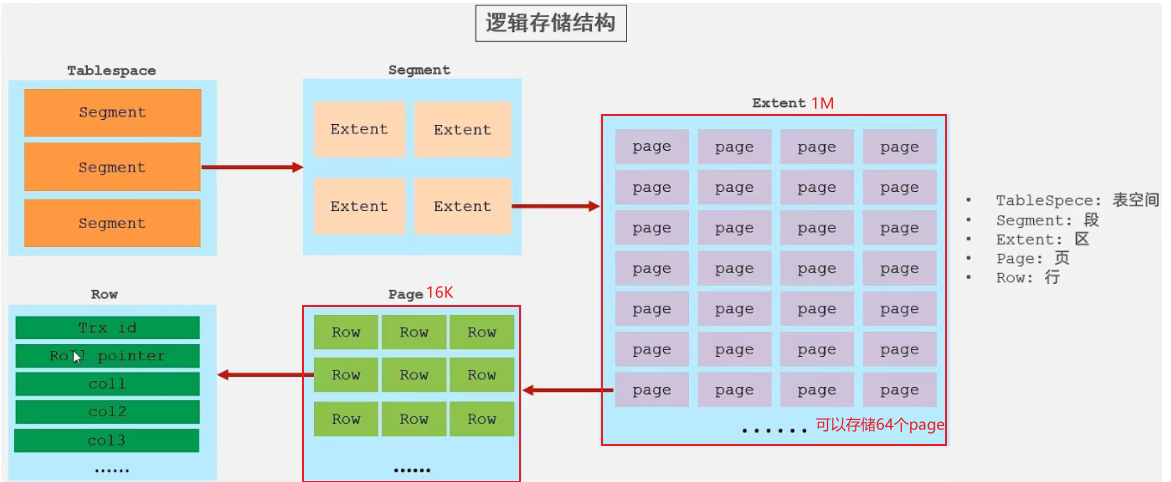
-
MyISAM
-
MyISAM是早期MySQL的默认存储引擎
-
-
特点
-
不支持外键,不支持事务
-
支持表锁,不支持行锁
-
访问速度快
-
-
文件
-
xxx.sdi:存储表结构信息
-
xxx.MYD:存储数据
-
xxx.MYI:存储索引
-
-
Memory
-
Memory引擎的表数据是存储在内存中的,由于受到硬件问题、或断电问题的影响,只能将这些表作为临时表或缓存使用
-
-
特点
-
内存存放
-
hash索引
-
访问速度快
-
-
文件
-
xxx.sdi:存储表结构信息
-
三种存储引擎的区别
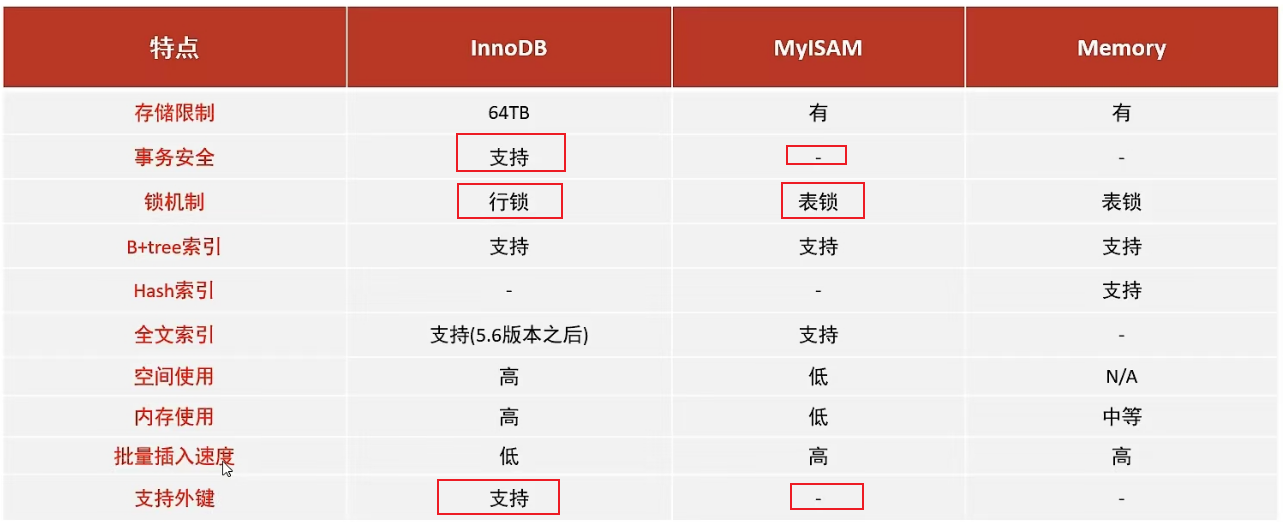
重点记忆:InnoDB与MyISAM的三大区别:事务安全,锁机制,是否支持外键
存储引擎选择
在选择存储引擎时,应该根据应用系统的特点选择合适的存储引擎。对于复杂的应用系统,还可以根据实际情况选择多种存储引擎进行组合。
-
InnoDB:是Mysql的默认存储引擎,支持事务、外键。如果应用对事务的完整性有比较高的要求,在并发条件下要求数据的一致往,数据操作除了播入和查询之外,还包含很多的更新、删除操作,那么noDB存储引擎是比较合适的选择。
-
MyISAM:如果应用是以读操作和插入操作为主,只有很少的更新和删除操作,并且对事务的完整性、并发性要求不是很高,那么选择这个存储引擎是非常合适的。
-
MEMORY:将所有数据保存在内存中,访问速度快,通常用于临时表及缓存。MEMORY的缺陷就是对表的大小有限制,太大的表无法缓存在内存中,而且无法保障数据的安全性
希望对大家有所帮助!