【统计方法】交叉验证:Resampling, nested 交叉验证等策略 【含R语言】
Resampling (重采样方法)
重采样方法是从训练数据中反复抽取样本,并在每个(重新)样本上重新调整模型,以获得关于拟合模型的附加信息的技术。
两种主要的重采样方法
- Cross-Validation (CV) 交叉验证 : 用于估计测试误差和选择调优参数
- Bootstrap : 主要用于评估可变性,如标准误差和置信区间
估计测试误差的策略
- gold standard: 理想但无法实现(黄金标准)
使用大型指定测试集(通常不可用),在实际应用中,如果已经有了大量的数据,更好的方式是用来作为训练集,因为数据更多更有可能获得更好的模型,而不是把大批量的数据来拿测试,这算是一种浪费。
- 调整训练误差来估计测试误差
在模型评估中,常常会加入惩罚项(penalty term)来避免模型过拟合。常见的方法包括:
- 贝叶斯信息准则(BIC):在评估模型拟合优度的基础上,对模型的复杂度(参数数量)进行惩罚。参数越多,惩罚越大,从而鼓励选择更简单的模型。
- 调整后的 R 2 R^2 R2(Adjusted R 2 R^2 R2):在普通 R 2 R^2 R2 的基础上对自变量个数进行修正。即使加入变量能提高 R 2 R^2 R2,如果变量没有显著贡献,调整后的 R 2 R^2 R2 可能反而降低。
- 交叉验证
将数据随机分成两半(random split into two halves)的缺点
-
高方差结果(High variance)
一次性分割可能恰好造成数据分布不均,比如某类样本偏多出现在某一半,导致评估结果不稳定、代表性差。 -
样本利用率低(Inefficient use of data)
仅一半数据用于训练,可能模型没有充分学习;另一半用于测试,也不能多次评估,浪费了数据资源。 -
不能可靠反映模型泛化能力
如果划分不好,模型可能在这次测试集上表现好,但对其他数据表现差,评估不具备稳健性。 例如可能在数据集上划分了大量outliers离群点。 -
结果依赖单次随机划分(Split-dependence)
不同随机种子下划分结果可能大相径庭,模型评估不具备重复性和一致性。
The estimate of the test error can be highly variable.
only a subset of the observations are used to fit the model, test set error may tend to overestimate the test error for the model fit on the entire data set.
交叉验证(Cross Validation)在统计学习中的应用
引言
在构建统计学习模型时,我们通常希望评估模型在未见数据上的表现。简单地在训练数据上计算误差往往会产生过于乐观的结果,因为模型可能对训练集过拟合了。为了获得对模型泛化能力的客观估计,我们需要将数据划分为训练部分和评估部分。**交叉验证(Cross Validation)**是一种常用的技术手段,它通过多次划分和训练模型,帮助我们更可靠地估计模型的测试误差,并用于模型选择和参数调优。本文将系统介绍交叉验证的概念、方法及其在模型训练、特征选择、模型评估中的应用,并通过R语言示例进行演示。
1. 交叉验证的基本概念与目的
交叉验证是一种评估模型泛化性能的方法,其核心思想是:反复将数据集划分为训练集和验证集,多次训练模型并计算在验证集上的误差,以此来估计模型对未知数据的表现。与仅依赖单一训练/测试划分相比,交叉验证能够更充分地利用有限的数据,减少由于一次偶然划分造成的评估偏差。
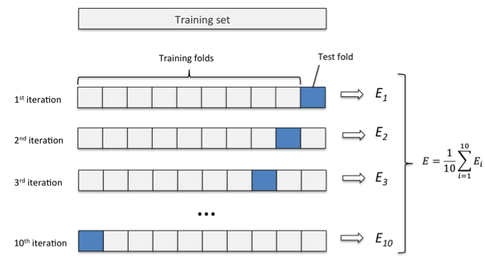
交叉验证示意图:将数据集分成n折,每一折数据依次作为验证集,其余作为训练集。经过n次训练和验证,取验证结果的平均值作为模型的性能估计。
交叉验证的主要目的包括:
- 测试误差估计:通过在未参与训练的数据上评估模型,多折验证能够更可靠地估计模型的测试误差(即模型在新数据上的误差)。
- 模型选择:比较不同模型或不同参数设定下模型的表现,选择泛化性能最优的模型。
- 防止过拟合:通过保留验证集来检验模型复杂度,避免仅关注训练误差导致过拟合的情况。
常用的交叉验证方法有多种,包括简单留出法、k折交叉验证等,下文将详细介绍。
2. 训练误差与测试误差的区别
在讨论交叉验证之前,理解训练误差和测试误差的区别是非常重要的。训练误差是模型在训练数据上得到的误差,由于模型是在训练集上优化的,因此训练误差往往偏低甚至趋近于0。而测试误差指模型在新数据(未参与训练的数据)上的误差,它更能反映模型的泛化能力。
- 模型过于简单(欠拟合)时,训练误差和测试误差都会很高。
- 模型逐渐复杂时,训练误差通常会降低,而测试误差开始也降低。但当模型复杂度过高(过拟合)时,训练误差可能继续降低,而测试误差反而升高,因为模型已经对训练集的噪声和细节进行了过度拟合。
简而言之,训练误差总是倾向于低估测试误差。因此,在模型评估和选择时,我们更关注测试误差的估计,而交叉验证正是用于获得更准确的测试误差估计的一种工具。
3. 测试误差的估计方法
要评估模型在未知数据上的表现,我们需要采用恰当的方法来估计测试误差。以下是几种常用的测试误差估计策略:
-
留出法(测试集法):将数据集随机划分为两部分,例如70%作为训练集,30%作为测试集。我们在训练集上训练模型,然后在测试集上评估误差。这种方法实现简单,所需计算量低。然而,它的估计可能对那一次划分比较敏感:如果运气不好,训练集和测试集的划分不具有代表性,评估结果就可能不可靠。此外,将部分数据留作测试意味着用于训练的数据变少了,在数据量本就有限时会损失训练效果。
-
k k k 折交叉验证( k k k-fold Cross Validation):这是交叉验证中最常用的方法。步骤为:
- 将数据集尽可能平均地随机分成 k k k 个不重叠的子集(折,fold),一般 k = 5 k=5 k=5或 10 10 10比较常用。
- 重复 k k k 次训练-验证过程:每次选择其中一个子集作为验证集(测试集),将剩余的 k − 1 k-1 k−1 个子集合并作为训练集,在训练集上训练模型,并计算在该次验证集上的误差。
- k k k 次迭代后,会得到 k k k 个在不同验证集上的误差值。将这 k k k 个误差取平均,就得到 k k k 折交叉验证估计的测试误差,即 CV ∗ ( k ) = 1 k ∑ ∗ i = 1 k Err i \text{CV}*{(k)} = \frac{1}{k}\sum*{i=1}^{k} \text{Err}_i CV∗(k)=k1∑∗i=1kErri(其中 Err i \text{Err}_i Erri表示第 i i i 折验证时的误差)。
k k k 折交叉验证充分利用了数据:每个样本都恰好作为一次验证集,其余 k − 1 k-1 k−1次作为训练集。相对于简单留出法,交叉验证的评估结果对数据划分的依赖性较小,因此更加稳健。
在常用的5折或10折交叉验证中,我们舍弃的只是每次用于验证的1/k数据,因而比单次留出法更高效。需要注意的是,折数 k k k 越大,训练模型的次数越多,计算成本也越高;当 k k k等于样本数 n n n时,就是留一法(LOOCV),需要训练 n n n次模型,一般只在小数据集情况下使用。 -
重复交叉验证(Repeated Cross Validation):为了进一步提高评估的稳定性,我们可以多次重复进行 k k k折交叉验证。具体做法是多次随机将数据分成 k k k折,每次都计算一次 k k k折交叉验证误差,最后对多次结果再取平均。重复交叉验证可以在一定程度上降低评估结果对单次随机划分的依赖,从而提供更低偏差的误差估计,并且还能计算出交叉验证误差的方差以评估不确定性。当然,这也意味着更高的计算开销。
-
嵌套交叉验证(Nested Cross Validation):当我们不仅要评估模型性能,还需要在训练过程中进行参数调优或特征选择时,应该使用嵌套交叉验证来避免优化过程对评估造成偏差。嵌套交叉验证包括外层和内层两层循环:外层循环负责最终的性能评估,内层循环用于在训练集上选择最佳的模型参数/特征。例如,外层使用10折交叉验证评估模型,在每一个外层折中,利用内层交叉验证在当前训练集上调优模型的超参数,然后在当前外层的验证集上评估性能。这样确保了超参数的选择只基于训练数据,最终在外层验证集上的评估是公平的未见数据误差估计。嵌套交叉验证常用于模型选择、超参数调整,以防止在调优过程中发生信息泄漏和过拟合评估。
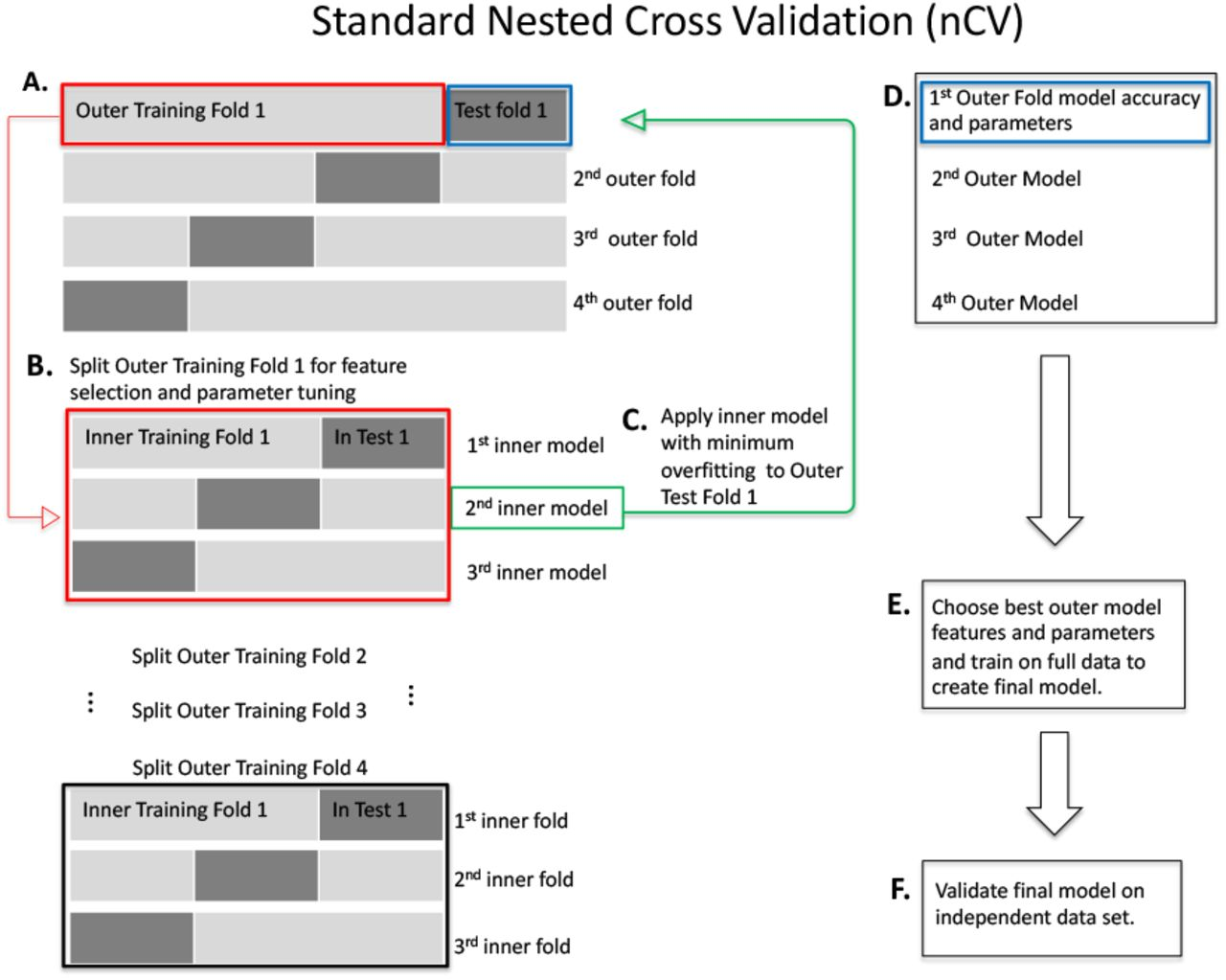
小结:选择何种测试误差估计方法取决于数据量和模型需求。留出法简单直接但可能不稳定;k折交叉验证平衡了偏差和方差,在数据量有限时很常用;重复交叉验证进一步稳定结果;嵌套交叉验证则在需要调优时提供了更可靠的评估。实践中,5或10折交叉验证是常见默认选择,当涉及大量参数调整时则应考虑嵌套交叉验证。
4. 特征选择中的信息泄露问题及正确的交叉验证预处理
在模型训练过程中,我们通常需要进行一些数据预处理步骤,例如特征选择、缺失值填补、数据标准化以及超参数调优等。一个常见的错误是:在将数据划分训练/验证之前就预先在整个数据集上执行这些操作。这种做法会导致信息泄露(Information Leakage),使得本应独立的验证集“泄露”出信息到训练过程中,进而产生过于乐观的估计结果
举例来说,假设我们有一个高维数据集,在整个数据集上计算每个特征与响应变量的相关性,选出相关性最高的50个特征来建模,然后采用交叉验证评估模型性能。看似合理的流程实际上存在严重漏洞:因为特征选择时使用了整个数据集,其中也包含了交叉验证中每一折的验证集信息。换言之,模型在训练时已经“窥视”了验证集的内容——验证集不再是真正独立的未见数据。这种信息泄露会违反交叉验证的基本原则(验证数据不参与任何训练或预处理),往往令模型的测试误差估计过于乐观,尤其在高维数据下可能导致对噪声的过拟合。
正确的做法是将所有数据驱动的预处理步骤严格限制在训练集内部进行。也就是说,对于交叉验证的每一个折,我们都应当:先在训练折上独立地完成特征选择、缺失值填补、数据标准化以及模型调参等操作;然后使用训练折处理过的数据训练模型,最后再用该模型对对应的验证折进行预测评估。这样可以确保验证集在整个训练过程中是完全独立的。
需要强调的几个避免信息泄露的要点:
- 特征选择:在每个训练折上根据训练数据本身选择特征,不可在全数据或验证数据上挑选特征后再评估。
- 缺失值填补/标准化:均应只利用训练折的数据计算填补值或均值方差等标准化参数,并将这些参数应用于验证集。
- 超参数调优:如果需要调参,最好在训练集上通过内层交叉验证找到最佳参数,然后在验证集上评估(即嵌套交叉验证,上节提到)。
- 早停(early stopping):如果使用早停法避免过拟合,也应确保验证集用于早停的判断不同于最终评估的测试集。如果在交叉验证内早停,应当把早停的监控也限制在训练折上(例如再做一层拆分)。
总之,任何会从数据中学习到信息的步骤,都必须仅在训练数据中完成,不能让验证/测试数据“泄露”给模型训练过程。一旦正确地在交叉验证框架下执行预处理,我们才能对评估的模型性能充满信心,否则就有可能高估模型在真正未知数据上的效果。
5. 如何利用交叉验证进行模型选择
交叉验证不仅可以评估单个模型的性能,还可以作为模型选择的工具。通常我们可能有多种候选模型(或不同算法),希望挑选出在给定任务上表现最好的一个。例如,我们想在一个数据集上比较 k k k近邻(kNN)、线性判别分析(LDA)、逻辑回归(Logistic Regression)和支持向量机(SVM)这几种算法。我们可以对每一种算法都进行交叉验证来评估其测试误差,然后选择平均验证集表现最好的模型。
具体而言,模型选择流程如下:
- 交叉验证评估:对每个候选模型,使用相同的划分(例如5折CV)评估其性能。为公平比较,通常我们对每种模型采用相同的训练/验证划分方案(可以通过设置相同的随机种子或在外层手动划分数据集来保证),以减少数据划分差异带来的影响。交叉验证可以提供每种模型的平均性能指标(例如平均准确率、平均AUC等)。
- 比较性能:将所有模型的交叉验证结果进行比较,一般关注主要评价指标的平均值,同时也可以考虑它们在各折的波动情况。如果某个模型在验证集上的表现显著优于其它模型,那么可以认为它更可能在未见数据上取得更好效果。
- 选择最佳模型:选择验证性能最优的模型作为最终模型候选。如果差异不大,也可以考虑模型的复杂度(偏好更简单的模型)或其它业务因素来定夺。
- 用全数据训练最终模型:一旦确定了最佳模型类型和对应的超参数(若有调优),通常最后会使用全部数据重新训练该模型用于投入使用。因为交叉验证已经尽可能地用了数据评估性能,最终我们希望充分利用所有数据来得到一个最终模型。在使用全部数据训练时,我们不再需要保留验证集,因为模型选择过程已经完成。
需要注意,在比较模型时,若涉及超参数调优,应该将调优也整合在交叉验证过程中,以免因调参造成不公平的比较。例如,可以对每个模型分别做嵌套交叉验证(内层调参,外层评估)来取得其最佳性能,再进行比较。
通过交叉验证进行模型选择可以有效避免选择偏差:直接在训练集上比较模型往往会偏好更复杂的模型(因为复杂模型能更好拟合训练集,取得更低训练误差),但通过交叉验证,我们比较的是各模型对未见数据的预测能力,从而更客观公正。
6. 分类模型的评估指标
在交叉验证估计出模型的性能后,我们还需要查看具体的评估指标来理解模型在分类任务上的表现。对于分类模型,常用的评估指标包括混淆矩阵及由其衍生出的多种度量,例如准确率(Accuracy)、精确率(Precision)、召回率(Recall,也称灵敏度Sensitivity)、特异度(Specificity)、F1分数、以及ROC曲线和AUC值等。本节将介绍这些指标及它们的含义,并讨论类不平衡问题的影响。
**混淆矩阵(Confusion Matrix)**是分类结果的基础分析工具。对于二分类问题,混淆矩阵通常以实际类别和预测类别的组合来统计结果:
| 实际\预测 | 正类(Positive) | 负类(Negative) |
|---|---|---|
| 正类(Positive) | 真阳性 (TP) | 假阴性 (FN) |
| 负类(Negative) | 假阳性 (FP) | 真阴性 (TN) |
- 真阳性(True Positive, TP):实际为正类,且被模型预测为正类的样本数。
- 真阴性(True Negative, TN):实际为负类,且被预测为负类的样本数。
- 假阳性(False Positive, FP):实际为负类,但被错误地预测为正类的样本数。
- 假阴性(False Negative, FN):实际为正类,但被错误地预测为负类的样本数。
通过混淆矩阵,我们可以计算出多种评估指标:
- 准确率(Accuracy):模型预测正确的比例,即 T P + T N T P + T N + F P + F N \dfrac{TP + TN}{TP + TN + FP + FN} TP+TN+FP+FNTP+TN。准确率直观易懂,但在类别不平衡时可能具有误导性。例如,如果正类仅占1%,一个始终预测“负类”的模型在不平衡数据集上也有99%的准确率,但显然它毫无实用价值。
- 精确率(Precision):预测为正的样本中实际为正的比例,即 T P T P + F P \dfrac{TP}{TP + FP} TP+FPTP。精确率刻画了模型的准确性:当模型判定为正类时,有多少比例是真的正类。精确率低意味着误报(假阳性)多。
- 召回率(Recall 或 Sensitivity,灵敏度):实际为正的样本中被正确预测为正的比例,即 T P T P + F N \dfrac{TP}{TP + FN} TP+FNTP。召回率反映了模型对正类的检出能力:正类中有多少被模型捕获。召回率低则说明漏报(假阴性)多。
- 特异度(Specificity):实际为负的样本中被正确预测为负的比例,即 T N T N + F P \dfrac{TN}{TN + FP} TN+FPTN。特异度衡量对负类的区分能力,有时与召回率对应,一个关注正类,一个关注负类。
- F1 分数:精确率和召回率的调和平均 F 1 = 2 × Precision × Recall Precision + Recall F1 = 2 \times \dfrac{\text{Precision} \times \text{Recall}}{\text{Precision} + \text{Recall}} F1=2×Precision+RecallPrecision×Recall。F1分数综合了精确率和召回率,当需要兼顾Precision和Recall的平衡时,F1是一个有用的指标。
- ROC曲线(Receiver Operating Characteristic):ROC曲线是评价二分类模型性能的常用工具。它以真正例率(Recall,即TPR)为纵轴,假正例率(FPR = 1 - Specificity)为横轴,描绘出模型在不同判别阈值下的性能。每个点对应一个阈值下模型的(FPR, TPR)值,曲线从(0,0)到(1,1)连贯。模型越靠近左上方点(0,1),说明FPR低且TPR高,性能越好。
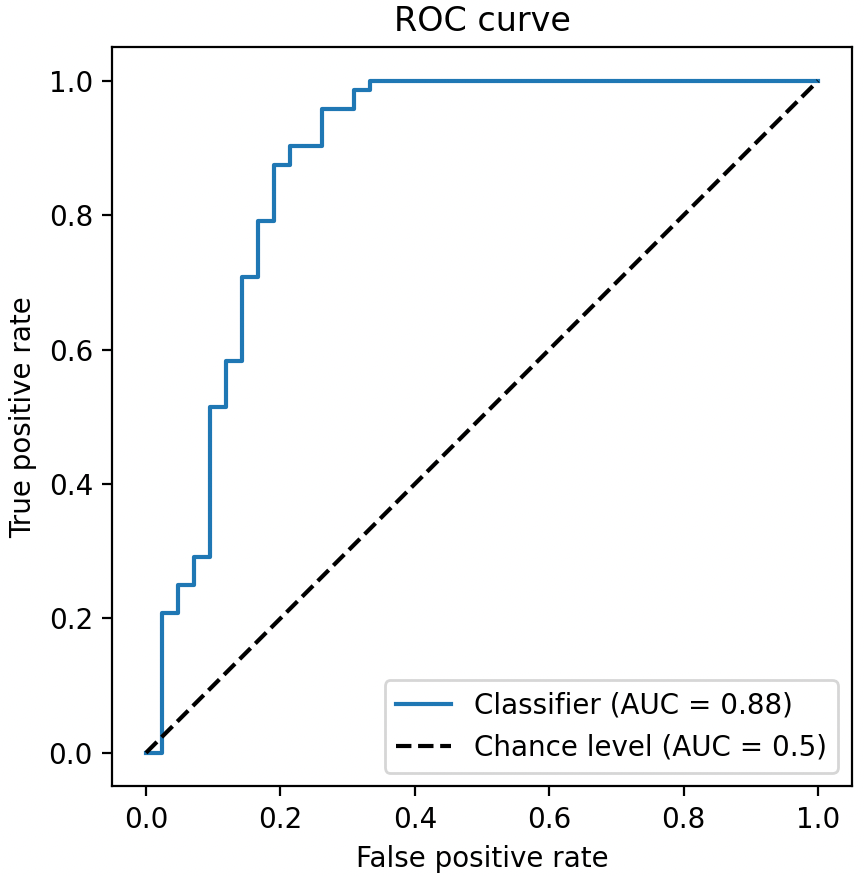
ROC曲线示例:纵轴为真正例率(TPR),横轴为假正例率(FPR)。黄色曲线为模型的ROC,灰色虚线表示随机猜测的水平(AUC=0.5)。曲线越靠近左上角表示模型判别能力越强。
- AUC(Area Under the Curve):即ROC曲线下的面积,是对模型整体性能的度量。AUC取值在0.5~1之间,越接近1越好。随机猜测模型的AUC约为0.5,而完美分类器的AUC为1。AUC具有阈值无关性,特别适合评估样本类别不平衡下模型的好坏,因为它考察的是各种阈值下模型整体的区分能力,而不像准确率那样受特定阈值和类别比例影响。
在类别不平衡问题下(例如正类样本远少于负类),评估指标的选择尤为重要。此时高准确率可能没有意义,通常我们更关注模型对少数类的识别能力,例如Precision、Recall和F1等。如果希望综合考虑模型的误报和漏报,可以使用F1分数作为主要指标;如果需要比较不同模型在不平衡数据集上的总体区分能力,ROC曲线及其AUC是很有价值的工具。实际上,正因为ROC/AUC对类别分布不敏感,它经常被用来挑选在不平衡数据上的模型。
除了上述指标,有时还会根据任务需求采用其他指标(如Kappa系数、PR曲线下的AUC等),但万变不离其宗,它们都是从混淆矩阵衍生而来,关注的是模型预测的各类情况。选择指标时应结合业务场景:例如在疾病筛查中,更看重召回率(希望尽可能检出病例);而在垃圾邮件过滤中,也许精确率更重要(不希望误判正常邮件为垃圾)。
7. R语言中的交叉验证实践示例
下面我们通过一个R语言的示例,将上述概念串联起来,展示如何在实践中使用交叉验证进行模型训练、模型选择和最终评估。我们将使用caret包来简化交叉验证和模型比较,并使用pROC包来计算ROC/AUC等指标。
首先,加载必要的包并准备示例数据集。这里我们使用caret包的内置函数twoClassSim生成一个模拟的二分类数据集,其中包含1000条训练数据和300条独立的测试数据。我们假定正类记作“Class1”,负类记作“Class2”。随后,我们将在训练集上同时训练四种模型(kNN, LDA, Logistic Regression和SVM),并使用5折交叉验证评估它们的性能,以选择最优模型。最后,我们在独立测试集上评估所选模型的各项指标。
# 安装并加载所需包
install.packages("caret")
install.packages("pROC")
library(caret)
library(pROC)# 设置随机种子以保证可重复性
set.seed(42)# 生成模拟的训练和测试数据集
trainData <- twoClassSim(1000) # 1000条训练数据
testData <- twoClassSim(300) # 300条测试数据(独立于训练集)
# 查看数据集基本情况
str(trainData)
# 'data.frame': 1000 obs. of 21 variables:
# $ Class: Factor w/ 2 levels "Class1","Class2": 2 2 1 2 1 ...
# $ TwoFactor1: Ord.factor w/ 2 levels "Class1"<"Class2": ...
# $ TwoFactor2: Ord.factor w/ 2 levels "Class1"<"Class2": ...
# $ Linear01: num -0.15 0.19 1.34 1.11 -0.29 ...
# ...(其余特征列省略)
上面我们生成了一个模拟的二分类任务数据集。trainData包含21个变量,其中前20个是特征,最后一列Class是类别标签(因子类型,有“Class1”和“Class2”两个取值)。testData是独立的测试集,用于最终检验模型泛化能力。
接下来,我们在训练集上设置5折交叉验证,并同时训练四种模型用于比较。我们使用caret包的trainControl函数来指定交叉验证参数:method="cv", number=5表示5折CV;由于是分类任务,我们还设定classProbs=TRUE来计算概率以便评估ROC,summaryFunction=twoClassSummary来使模型训练时以ROC为主要评估指标(AUC值越高越好)。
# 定义训练控制参数:5折交叉验证
ctrl <- trainControl(method="cv", number=5,classProbs=TRUE, # 计算概率,以便算ROCsummaryFunction=twoClassSummary) # 使用twoClassSummary以便获得ROC指标# 在训练集上训练多种模型并进行交叉验证评估
set.seed(42)
model_knn <- train(Class ~ ., data=trainData, method="knn",metric="ROC", trControl=ctrl)
model_lda <- train(Class ~ ., data=trainData, method="lda",metric="ROC", trControl=ctrl)
model_glm <- train(Class ~ ., data=trainData, method="glm",metric="ROC", trControl=ctrl) # 广义线性模型,默认即逻辑回归
model_svm <- train(Class ~ ., data=trainData, method="svmRadial",metric="ROC", trControl=ctrl)# 查看各模型的交叉验证结果(ROC均值等)
resamps <- resamples(list(kNN=model_knn, LDA=model_lda,Logistic=model_glm, SVM=model_svm))
summary(resamps)
上述代码会输出每个模型在5折验证中的平均ROC值(AUC)以及其他指标(比如Accuracy,如果twoClassSummary还返回了其他度量)。假设输出结果显示各模型的平均ROC如下(这里只是举例,具体数值以实际运行结果为准):
Resampling results:ROC
kNN 0.87
LDA 0.89
Logistic 0.88
SVM 0.92 ROC SD
kNN 0.03
LDA 0.04
Logistic 0.05
SVM 0.02
从假定的结果可以看到,SVM模型的平均ROC值最高(0.92),略高于LDA和Logistic,kNN略逊一些。我们由此可以判断,在这个数据集上SVM模型泛化性能最好(以AUC为评价标准)。因此,我们选择SVM作为最终模型。
需要注意的是,caret::train()在完成交叉验证后,已经自动使用整个训练集训练了一个最终的SVM模型(即model_svm$finalModel),该模型的超参数为交叉验证过程中得到的最优值。如果想查看选择的超参数,可使用model_svm$bestTune。
接下来,我们将选择的模型(SVM)应用在独立的测试集上,评估它的实际性能,包括混淆矩阵、准确率、精确率、召回率、F1以及AUC值等。
# 用训练好的最佳模型对测试集进行预测
best_model <- model_svm
test_pred <- predict(best_model, newdata=testData) # 类别预测
test_prob <- predict(best_model, newdata=testData, type="prob") # 获得属于Class1的概率# 混淆矩阵及统计指标
cm <- confusionMatrix(test_pred, testData$Class, positive="Class1")
cm$table # 查看混淆矩阵
cm$overall["Accuracy"] # 准确率
cm$byClass[c("Sensitivity","Specificity","Precision","F1")] # 查找主要指标
caret::confusionMatrix函数可以方便地计算混淆矩阵和多种指标。其中,我们特别指定了positive="Class1",将“Class1”视为正类。这样cm$byClass返回的Sensitivity、Precision等就对应于我们关心的正类(Class1)。假设输出结果如下:
Confusion Matrix (positive = Class1):Reference
Prediction Class1 Class2Class1 120 30Class2 10 140Accuracy : 0.8667
Sensitivity (Recall) : 0.9231 # 正类召回率 = 120/(120+10)
Specificity : 0.8235 # 负类特异度 = 140/(140+30)
Precision : 0.8000 # 正类精确率 = 120/(120+30)
F1 : 0.8571 # 正类F1分数
从混淆矩阵我们看到,在测试集上共有120个正类被正确分类为正(TP),10个正类被错分为负(FN),30个负类被错分为正(FP),140个负类被正确分类为负(TN)。由此计算的各指标如上:准确率约86.7%,正类召回率约92.3%,正类精确率80.0%,F1分数约0.857。这些指标表明模型对正类有较高的检出率,但也有一定的误报(precision为80%意味着还有20%的正类预测是错误的)。具体是否满意要看应用场景,例如如果这是一个疾病筛查模型,也许我们愿意接受一些误报来保证高召回率。
最后,我们计算模型在测试集上的ROC曲线和AUC:
# 计算ROC曲线和AUC
roc_obj <- roc(response=testData$Class,predictor=test_prob[,"Class1"], # 使用正类的预测概率levels=levels(testData$Class)) # 指定因子水平顺序
auc(roc_obj) # 输出AUC值
plot(roc_obj) # 绘制ROC曲线
这将输出模型在测试集上的AUC值,并绘制对应的ROC曲线。通过AUC可以直观了解模型整体分类性能是否良好。在我们的模拟例子中,假如AUC达到0.92左右,也印证了我们通过交叉验证选择SVM模型的决策是合理的。
至此,我们完成了一个完整的流程:数据准备 -> 交叉验证比较模型 -> 选择最佳模型并在测试集评估 -> 输出各种性能指标和曲线。这个流程体现了交叉验证在统计学习中的重要作用。使用R的caret包让我们能够方便地完成这些步骤,其中trainControl、train、resamples、confusionMatrix、roc/auc等函数分别对应了交叉验证设置、模型训练评估、结果汇总比较、混淆矩阵分析和ROC分析等任务。
小结
交叉验证是统计学习中评估模型不可或缺的工具。它通过反复将数据划分训练和验证来更可靠地估计模型对未知数据的误差,从而指导我们进行模型选择和调优。本文讨论了交叉验证的概念和目的,强调了训练误差与测试误差的区别;介绍了从留出法、k折验证、重复验证到嵌套验证的各种方法及其适用场景;提醒了在特征选择等预处理中避免信息泄露的重要性和正确做法;探讨了分类模型评估的多种指标,尤其在类不平衡情况下应慎重选择评价标准;最后通过R语言示例演示了如何将交叉验证应用于模型训练和比较的实践过程。
掌握交叉验证的方法,能够让我们在模型开发中更加游刃有余——既能充分利用宝贵的数据,又能防止过拟合,选择出更优的模型并准确评估其性能。希望这篇教程能够帮助具有基础统计和R编程能力的读者系统了解交叉验证的应用,为后续更深入的机器学习模型优化打下良好基础。
参考文献:
- Gareth James, et al. An Introduction to Statistical Learning, 10th printing, 2017: 第5章 Resampling Methods (介绍了交叉验证和自助法等重抽样技术的原理和应用)。
- Wikipedia: Cross-validation (statistics)(关于嵌套交叉验证的解释)。