机器学习的简单应用
什么是机器学习?
定义: 机器学习(Machine Learning, ML) 是人工智能(AI)的一个子领域,其核心是 通过算法让计算机从数据中自动学习规律,并基于这些规律对新数据做出预测或决策。与传统编程不同,机器学习不是通过显式规则(如 if-else 语句)解决问题,而是通过数据驱动的方式,让模型从经验中自我优化。
通俗一点:想象你要教一个孩子识别猫和狗时
- 传统编程:你手动编写规则,比如“有尖耳朵的是猫,有长鼻子的是狗”。但现实中猫狗特征复杂多变(比如折耳猫、短鼻狗),规则很快失效。
- 机器学习:你给孩子看大量猫狗照片,并告诉他哪些是猫、哪些是狗。孩子通过观察总结出规律(如毛发纹理、眼睛形状),最终即使看到没见过的图片也能正确分类。
机器学习中的角色:
- 数据 = 猫狗照片
- 算法 = 孩子的学习方式(比如对比特征、试错)
- 模型 = 孩子脑中形成的识别规则
- 预测 = 孩子对新照片的判断
机器学习的三大范式

好了,了解这么多,那就带你们去看看机器学习的模型是怎么来了
完整流程大纲
加载数据并探索
数据预处理(特征编码、标准化)
划分训练集和测试集
选择并训练模型
评估模型性能
优化模型(可选)
保存模型并预测新数据
1. 加载数据并探索
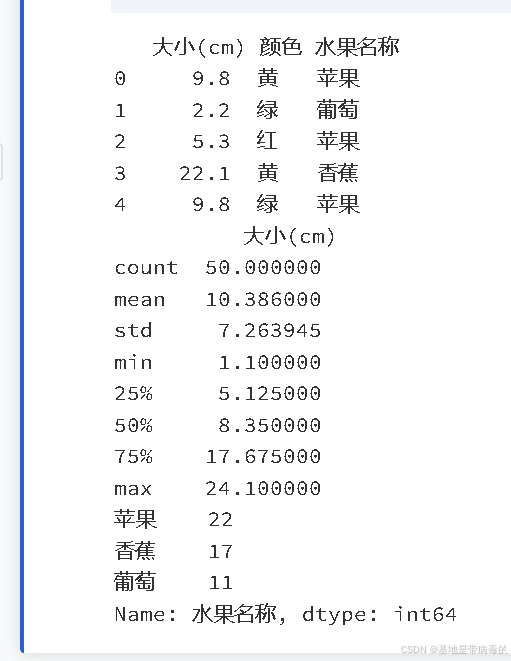
import pandas as pd# 加载数据
df = pd.read_csv('水果数据集.csv')# 查看数据前5行
print(df.head())# 统计信息
print(df.describe())# 类别分布
print(df['水果名称'].value_counts())运行结果
注意:如果没有水果数据集,可以自主生成,用来学习测试,代码如下:
import pandas as pd
import numpy as np# 设定随机种子(保证可重复性)
np.random.seed(42)# 生成50行数据
data = {'大小(cm)': [],'颜色': [],'水果名称': []
}# 定义水果的规则
fruit_rules = {'苹果': {'大小范围': (5, 10), '可能颜色': ['红', '绿', '黄']},'香蕉': {'大小范围': (15, 25), '可能颜色': ['黄']},'葡萄': {'大小范围': (1, 3), '可能颜色': ['紫', '绿']}
}# 随机生成数据
for _ in range(50):# 随机选择一个水果fruit = np.random.choice(['苹果', '香蕉', '葡萄'], p=[0.4, 0.3, 0.3])# 生成对应大小和颜色size = np.random.uniform(*fruit_rules[fruit]['大小范围'])color = np.random.choice(fruit_rules[fruit]['可能颜色'])# 添加到数据中data['大小(cm)'].append(round(size, 1))data['颜色'].append(color)data['水果名称'].append(fruit)# 创建DataFrame
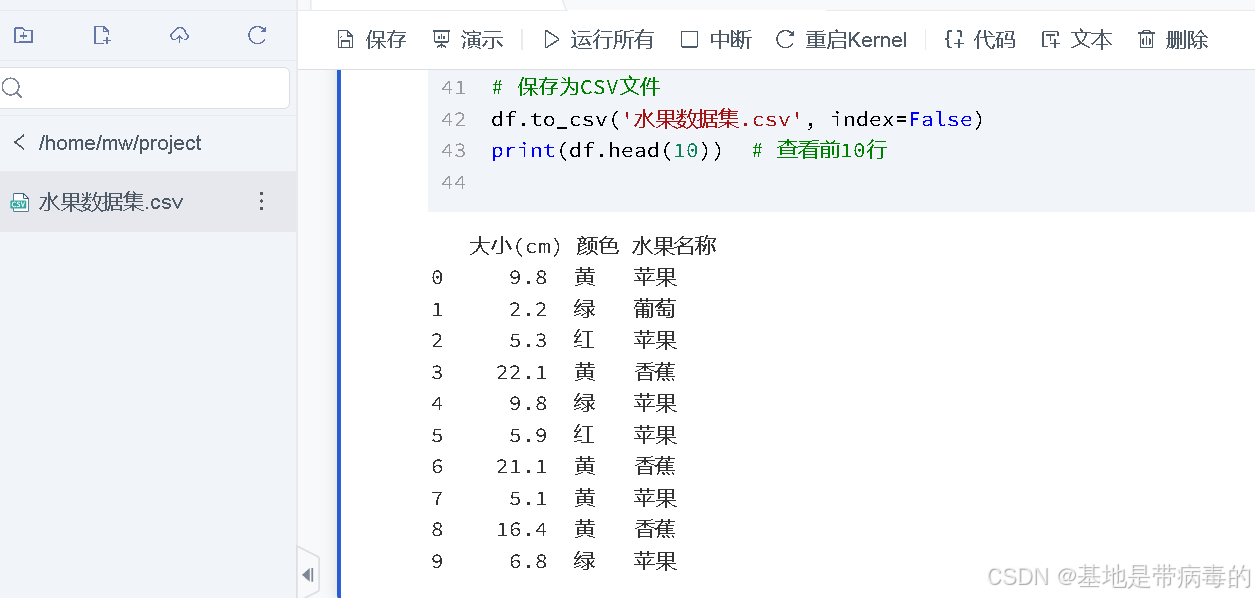
df = pd.DataFrame(data)# 保存为CSV文件
df.to_csv('水果数据集.csv', index=False)
print(df.head(10)) # 查看前10行运行结果
2. 数据预处理
2.1 将颜色(分类特征)转换为数值
from sklearn.preprocessing import LabelEncoder# 对颜色列进行编码
encoder_color = LabelEncoder()
df['颜色编码'] = encoder_color.fit_transform(df['颜色'])# 查看编码映射(可选)
print("颜色编码映射:", dict(zip(encoder_color.classes_, encoder_color.transform(encoder_color.classes_))))运行结果

2.2 特征标准化(可选,根据模型需求)——注意这个是可选
from sklearn.preprocessing import StandardScaler# 标准化大小和颜色编码
scaler = StandardScaler()
X_scaled = scaler.fit_transform(df[['大小(cm)', '颜色编码']])
print("\n合并后的完整数据:")
print(df.head())运行结果

3. 划分训练集和测试集
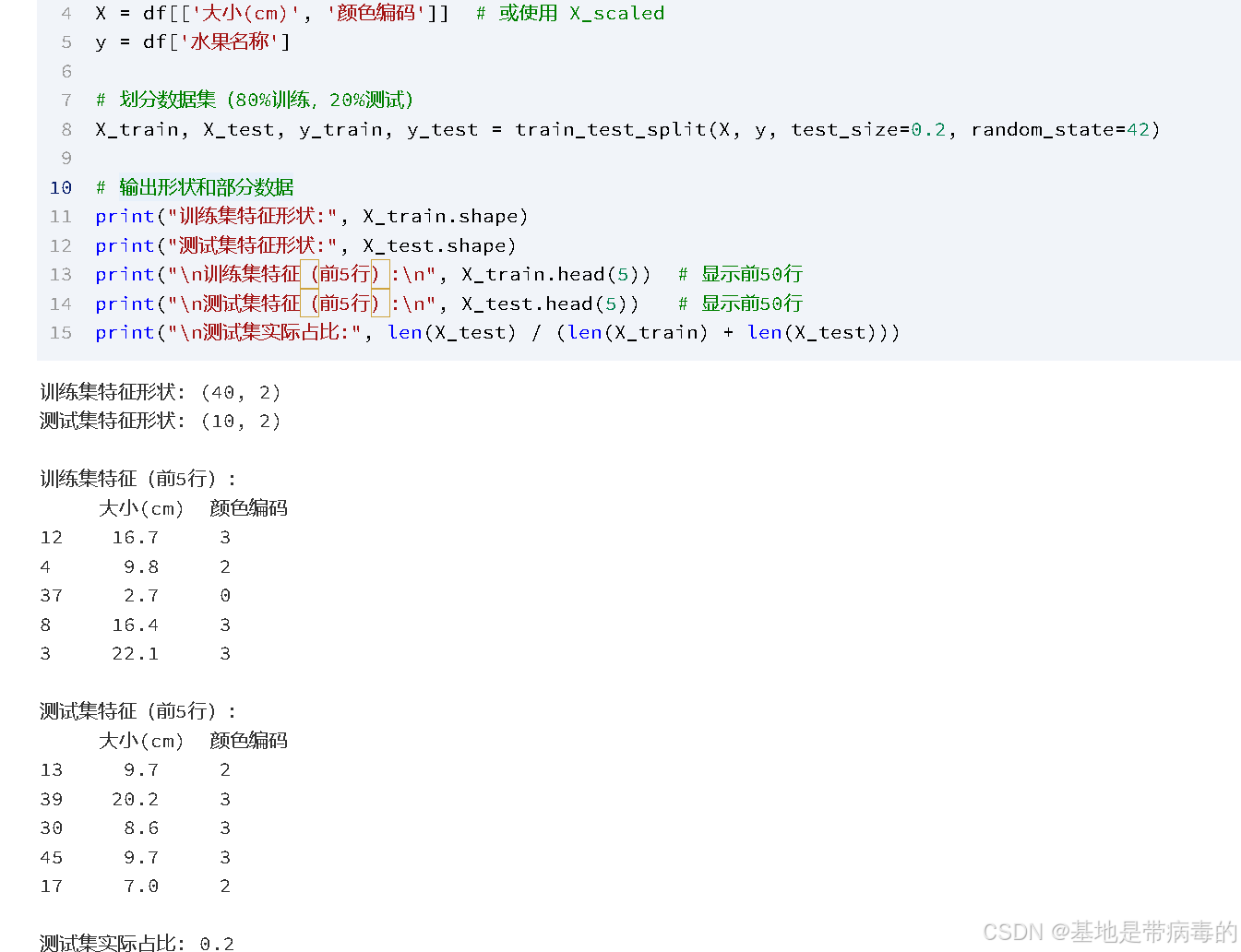
from sklearn.model_selection import train_test_split# 特征和标签
X = df[['大小(cm)', '颜色编码']] # 或使用 X_scaled
y = df['水果名称']# 划分数据集(80%训练,20%测试)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)# 输出形状和部分数据
print("训练集特征形状:", X_train.shape)
print("测试集特征形状:", X_test.shape)
print("\n训练集特征(前5行):\n", X_train.head(5)) # 显示前5行
print("\n测试集特征(前5行):\n", X_test.head(5)) # 显示前5行
print("\n测试集实际占比:", len(X_test) / (len(X_train) + len(X_test)))运行结果
4. 选择并训练模型
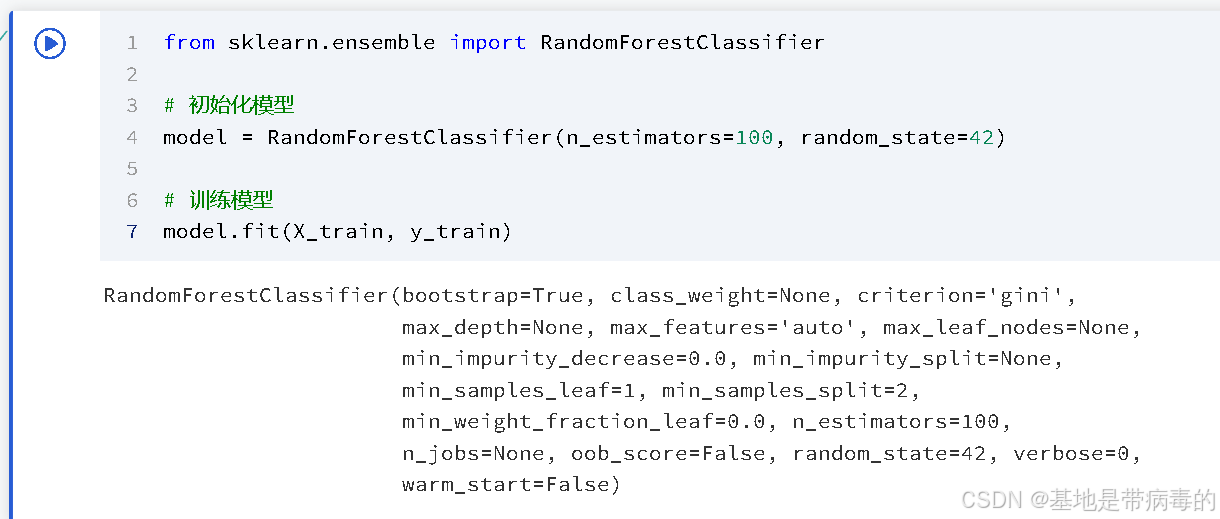
以随机森林(适合分类任务)为例:
from sklearn.ensemble import RandomForestClassifier# 初始化模型
model = RandomForestClassifier(n_estimators=100, random_state=42)# 训练模型
model.fit(X_train, y_train)运行结果
5. 评估模型性能
from sklearn.metrics import accuracy_score, classification_report# 预测测试集
y_pred = model.predict(X_test)# 计算准确率
accuracy = accuracy_score(y_test, y_pred)
print(f"准确率: {accuracy:.2f}")# 详细分类报告
print(classification_report(y_test, y_pred))运行结果
6. 优化模型(网格搜索调参)
from sklearn.model_selection import GridSearchCV# 定义参数网格
param_grid = {'n_estimators': [50, 100, 200],'max_depth': [None, 5, 10]
}# 网格搜索
grid_search = GridSearchCV(RandomForestClassifier(random_state=42), param_grid, cv=5)
grid_search.fit(X_train, y_train)# 最佳参数和模型
print("最佳参数:", grid_search.best_params_)
best_model = grid_search.best_estimator_运行结果

7. 保存模型并预测新数据
7.1 保存模型
import joblib# 保存模型和编码器
joblib.dump(best_model, '水果分类模型.pkl')
joblib.dump(encoder_color, '颜色编码器.pkl')运行结果

7.2 加载模型并预测
# 加载模型和编码器
loaded_model = joblib.load('水果分类模型.pkl')
loaded_encoder = joblib.load('颜色编码器.pkl')# 新数据示例
new_data = pd.DataFrame({'大小(cm)': [7.5, 20.0, 2.0],'颜色': ['红', '黄', '紫']
})# 预处理新数据
new_data['颜色编码'] = loaded_encoder.transform(new_data['颜色'])
X_new = new_data[['大小(cm)', '颜色编码']]# 预测
predictions = loaded_model.predict(X_new)
print("预测结果:", predictions)运行结果

ok,机器学习的简单应用我们已经初步学会的流程,接下来就可以开始做项目👍