过拟合和欠拟合
目录
- 欠拟合和过拟合
- 多种拟合表现
- 回归 (Regression)
- 分类 (Classification)
- 解决过拟合的方法
- 正则化代价函数
- 正则化线性回归 (Regularized linear regression)
- 正则化逻辑回归 (Regularized logistic regression)
欠拟合和过拟合
多种拟合表现
过拟合: Overfitting
欠拟合: Underfitting
泛化: Generalization
回归 (Regression)
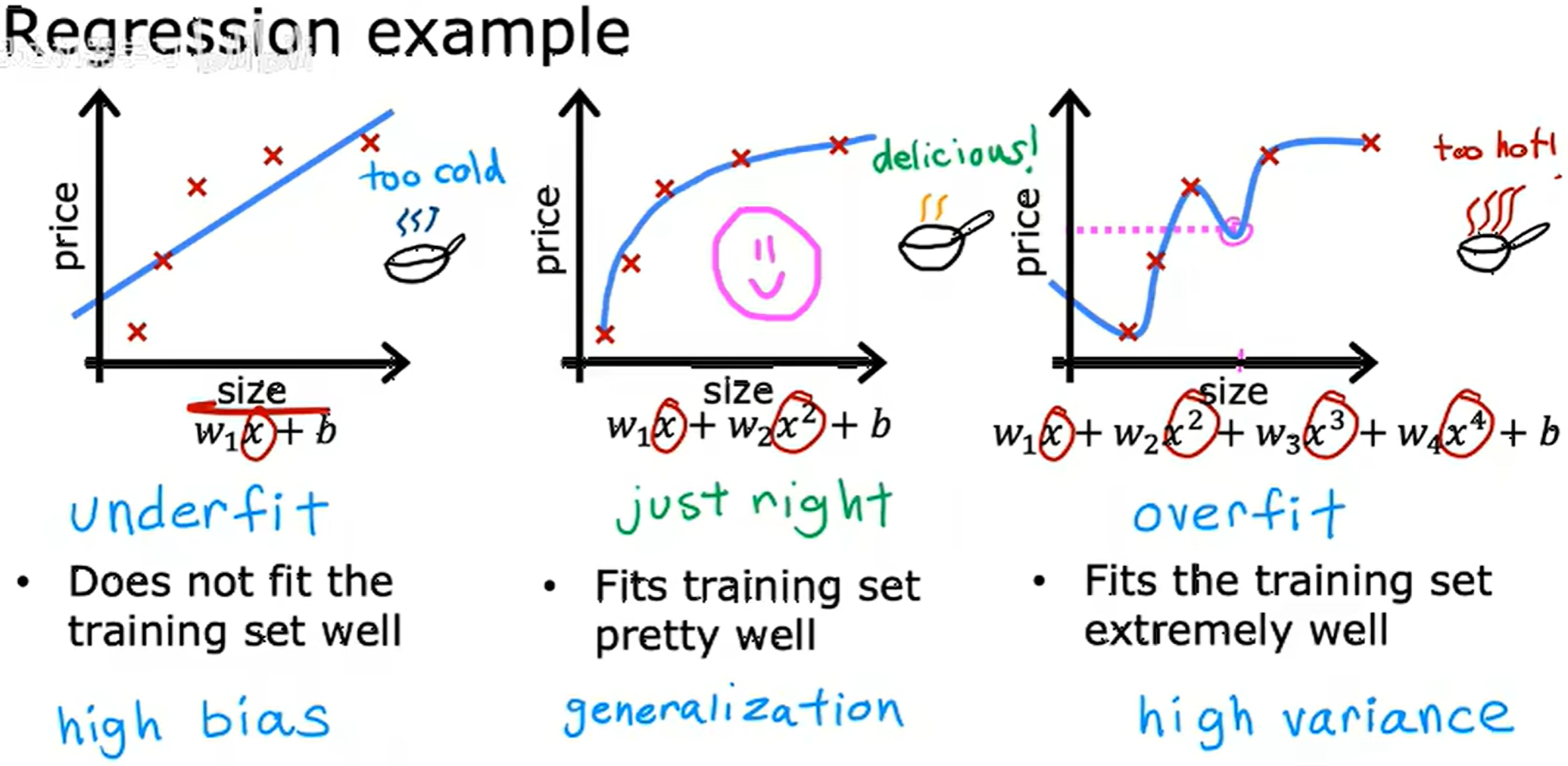
如上第一张图所示,模型拟合效果不好,通常称为欠拟合 (Underfitting),另一种称呼为 高偏差 (High Bias)。通常因为预设偏差,导致认为数据是线性的预设使其拟合了一条与数据不符合的直线。
如上第二张图所示,模型拟合效果很好,可以在不属于训练集的例子上也是如此,这种就叫做泛化 (Generalization)。
如上第三张图所示,模型在拟合训练数据上做得非常好,完美通过所有训练数据,使误差为 0 0 0,但是其图像表现的抖动异常,甚至预测出房子更大,其价格甚至更低。这种就叫做过拟合 (Overfitting),也称为高方差 (High variance),完美拟合的是已知的训练数据集,当拿着新的数据过来使用这个模型,可能因为数据随机落在曲里拐弯儿的地方模型造成较大程度的预测错误,不稳定性太高,其泛化能力差,不能推广至不属于训练集的例子上。
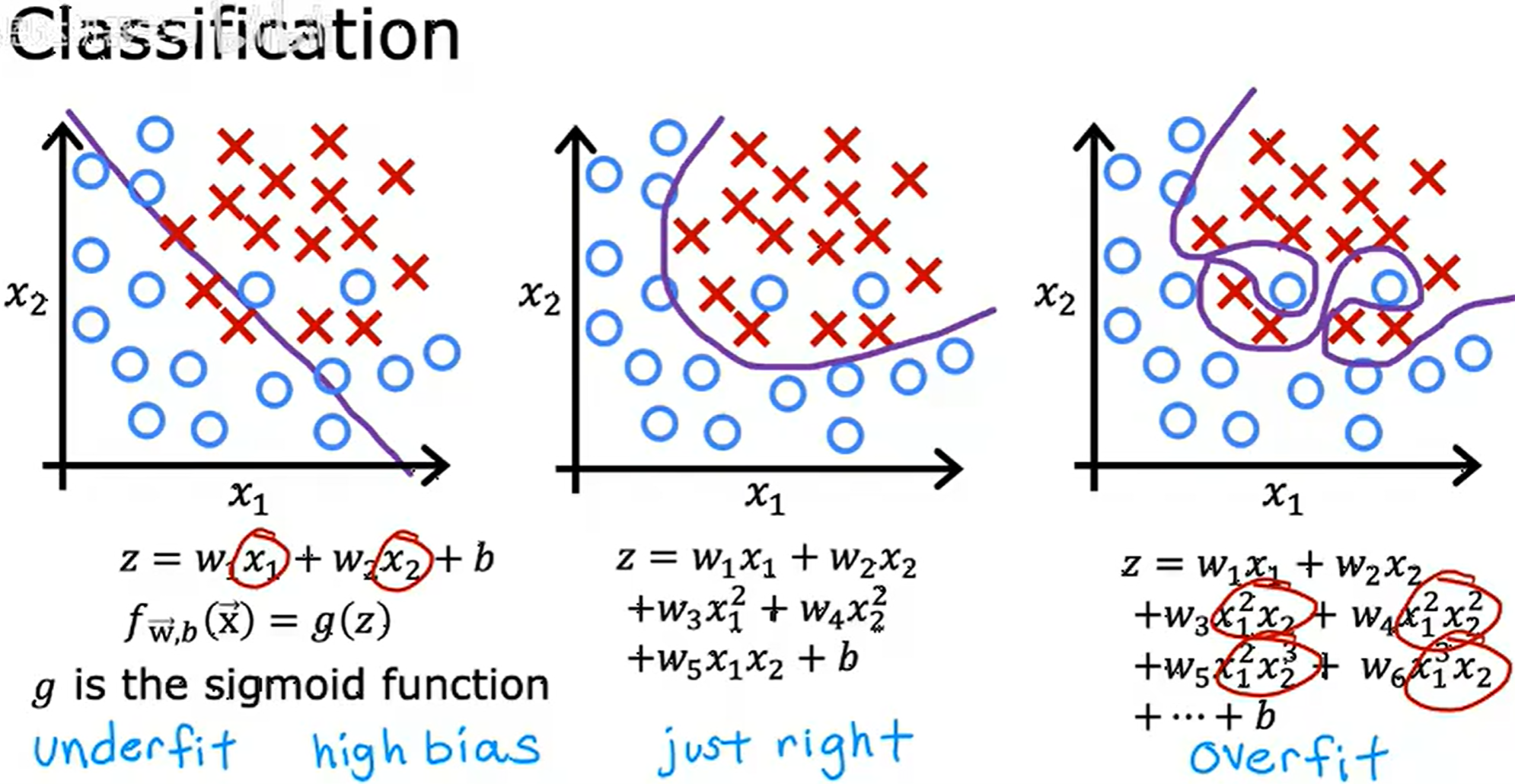
分类 (Classification)
解决过拟合的方法
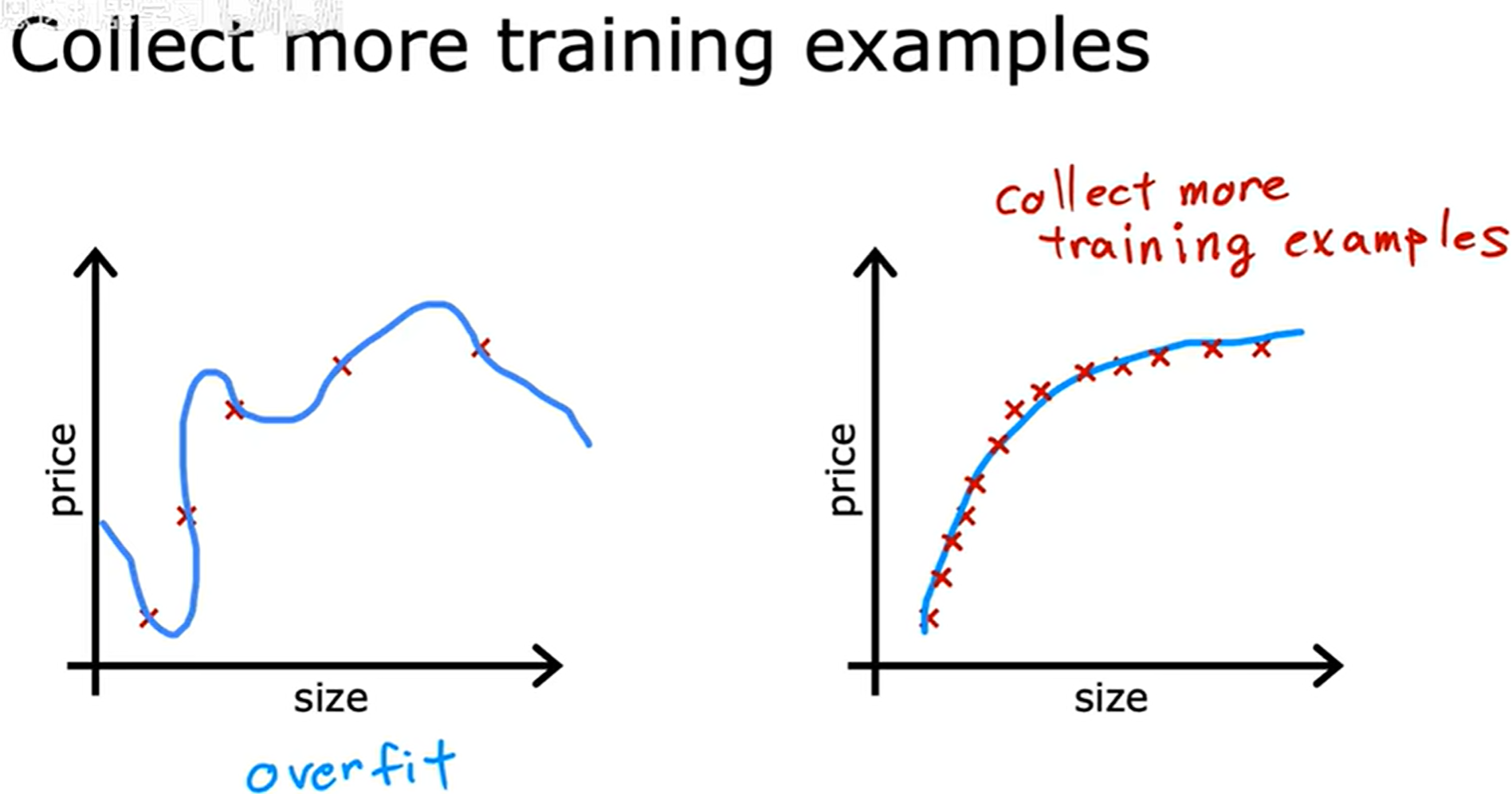
收集更多训练样本
随着样本数量增加,学习算法能够更好地捕捉数据的真实规律,从而学习到一个更加平滑、泛化能力更强的函数。这种情况下,模型可以尝试拟合更复杂的假设空间(如高阶多项式或高维特征空间),而不会产生过度的波动或过拟合现象。这是因为更大的训练集提供了更充分的统计信息,使得算法能够有效区分数据中的真实模式与随机噪声。
特征选择 (Feature Selection)
通过减少特征来降低模型复杂度,以防止过拟合。

正则化 (Regularization)
正则化(Regularization)与特征选择(Feature Selection)在目标上类似,都是通过降低模型复杂度来防止过拟合,但两者的机制不同:
- 特征选择 是直接剔除不相关或冗余的特征(如通过统计检验、L1正则化或递归特征消除),从而减少输入维度。
- 正则化 则通过约束模型参数的取值(如L2正则化使权重接近但不等于0,L1正则化使部分权重归零),间接调整特征的影响,而非完全去除它们。
关键区别:
- 特征选择 是“硬性剔除”,可能丢失部分信息,但可提高可解释性。
- 正则化 是“柔性抑制”,保留所有特征但限制其贡献,更适合特征间存在相关性或数据稀缺的场景。
例如:
- L1正则化(Lasso)可视为嵌入式的特征选择(部分权重归零)。
- L2正则化(Ridge)则更温和,仅缩小权重,适合需要保留所有特征的场景(如医学数据分析)。
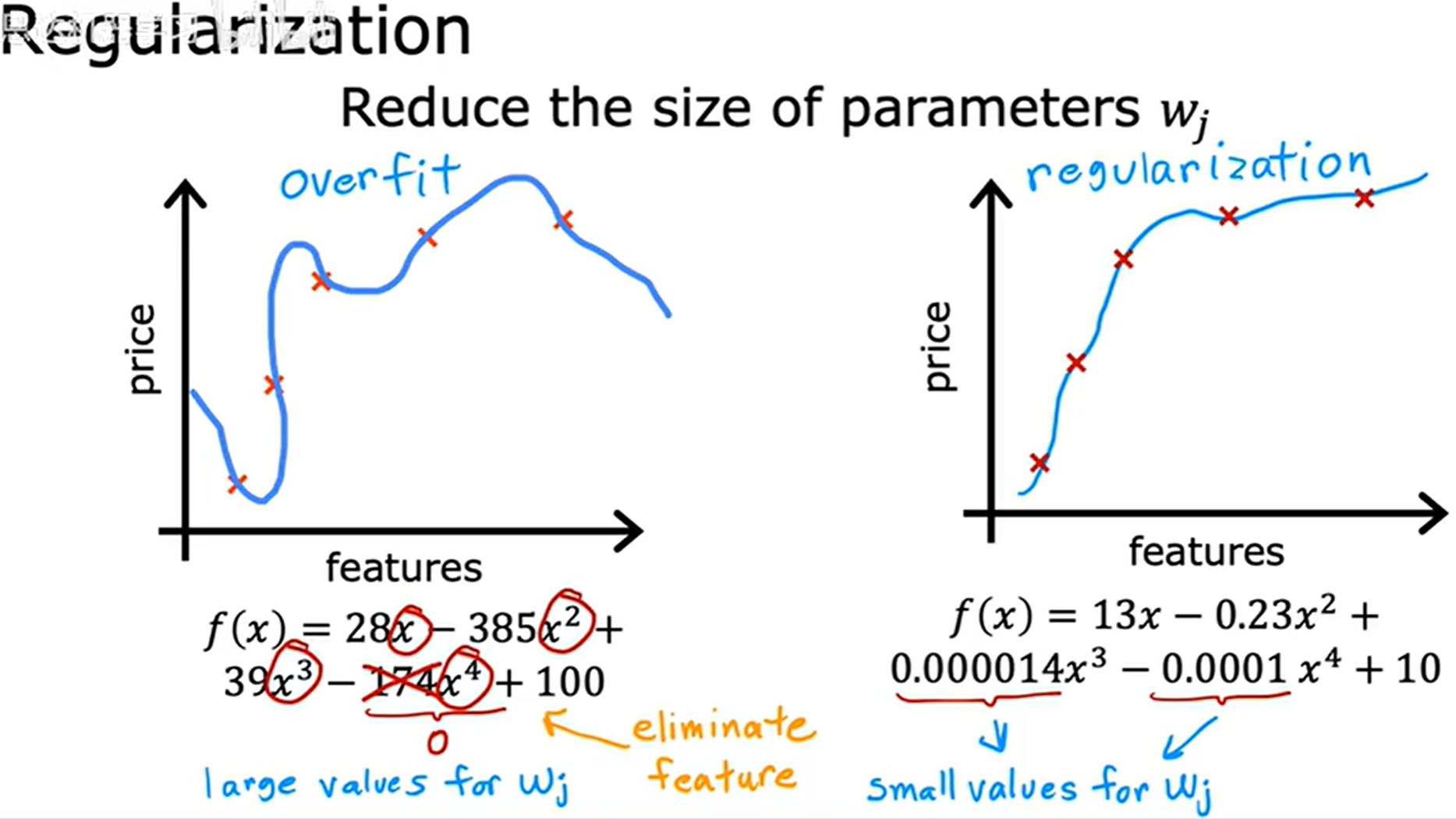
通常只改变参数 w ⃗ \vec{w} w 的值,正则化参数 b b b 的作用并不大,不鼓励将 b b b 变得很小。
总结
本质上是数据点数量(样本量)与模型参数数量(复杂度)之间的平衡问题。
- 参数过多 + 样本过少 → 模型容易记住噪声(过拟合)。
- 参数合理 + 样本充足 → 模型能学到真实规律(泛化性好)。
数学体现:
- 模型的自由度(参数数量)决定了其拟合能力,而数据量决定了统计可靠性。
- 例如,用高阶多项式拟合少量数据点,几乎可以完美拟合(过拟合),但泛化性极差。
解决过拟合的两种核心思路
(1) 增加数据量(更根本的解决方案)
- 更多数据提供更强的统计约束,使复杂模型也能学到稳定模式。
- 但现实中数据获取可能成本高(如医学实验)。
(2) 控制参数数量或影响(正则化、特征选择等)
- 减少参数数量:特征选择、降维(PCA)、简化模型结构(如用线性模型代替神经网络)。
- 约束参数取值:正则化(L1/L2)、早停法(Early Stopping)、Dropout(神经网络)。
正则化代价函数
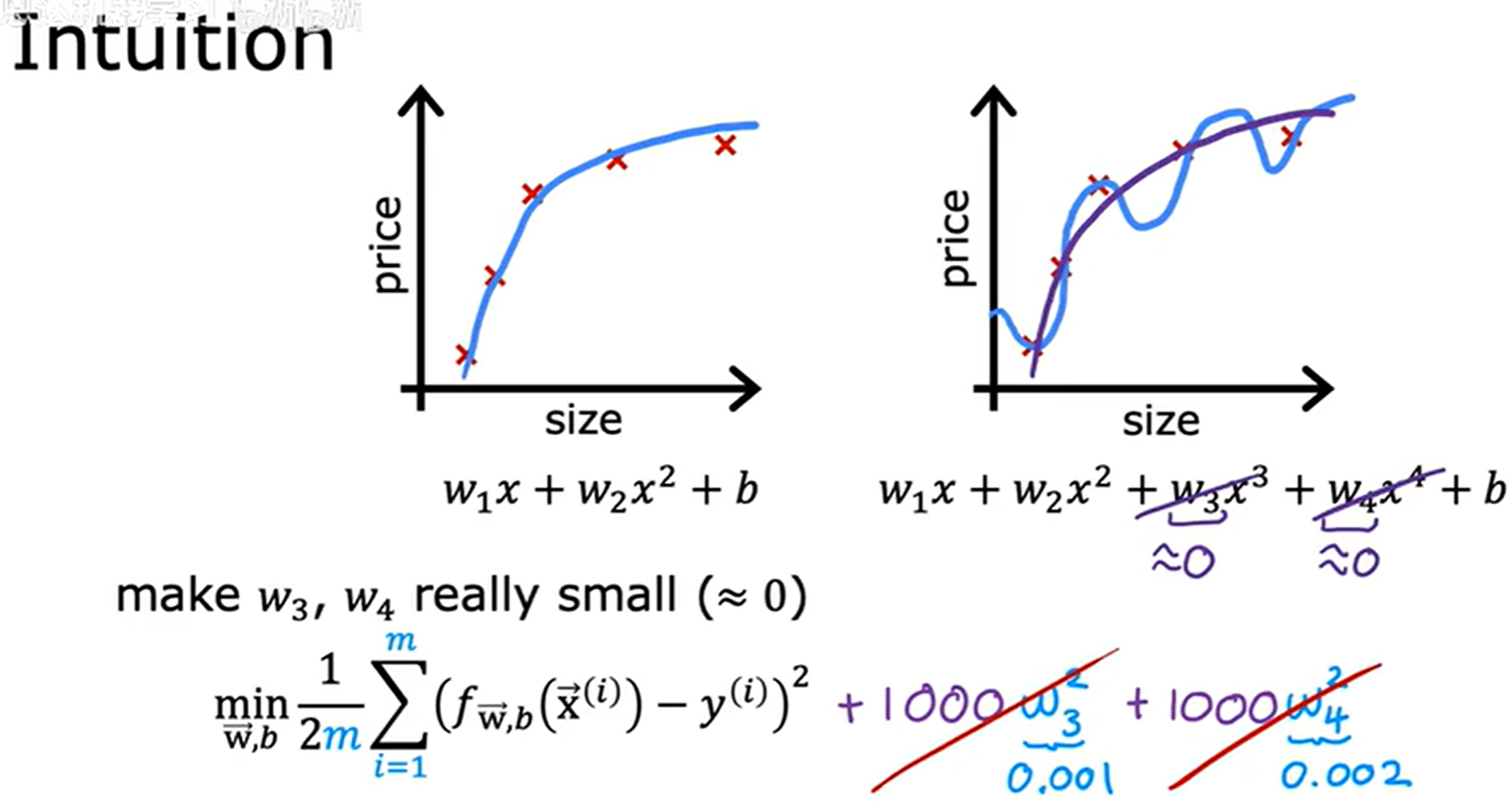
通过修改代价函数,在原代价函数上额外添加惩罚项。
如上图所示,添加的两个惩罚项,使得模型会因为 w 2 、 w 3 w_2、w_3 w2、w3 大小而受到惩罚,模型在优化时会倾向于减小这些权重的绝对值 ,从而几乎消除了对应的 x 3 、 x 4 x^3、x^4 x3、x4 特征值的影响,如图中拟合会更接近于二次函数。
由于不知道哪些是最重要的特征,也不知道该惩罚哪些特征,所以正则化通常是对所有特征进行惩罚,即惩罚所有 w j w_j wj 参数。

J ( w , b ) = 1 2 m ∑ i = 1 m ( y ^ ( i ) − y ( i ) ) 2 + λ 2 m ∑ j = 1 n w j 2 J(w, b) = \frac{1}{2m} \sum_{i=1}^m (\hat y^{(i)} - y^{(i)}) ^ 2 + \frac{λ}{2m}\sum_{j=1}^nw_j^2 J(w,b)=2m1i=1∑m(y^(i)−y(i))2+2mλj=1∑nwj2
同时对两项都进行 1 2 m \frac{1}{2m} 2m1 缩放,对选择一个合适的 λ λ λ 值会更容易。例如,训练集增大导致 m m m 增大,由于缩放使得先前的 λ λ λ 更有可能工作。
有些会有 b b b 的惩罚项,但其效果微小,可以不使用。
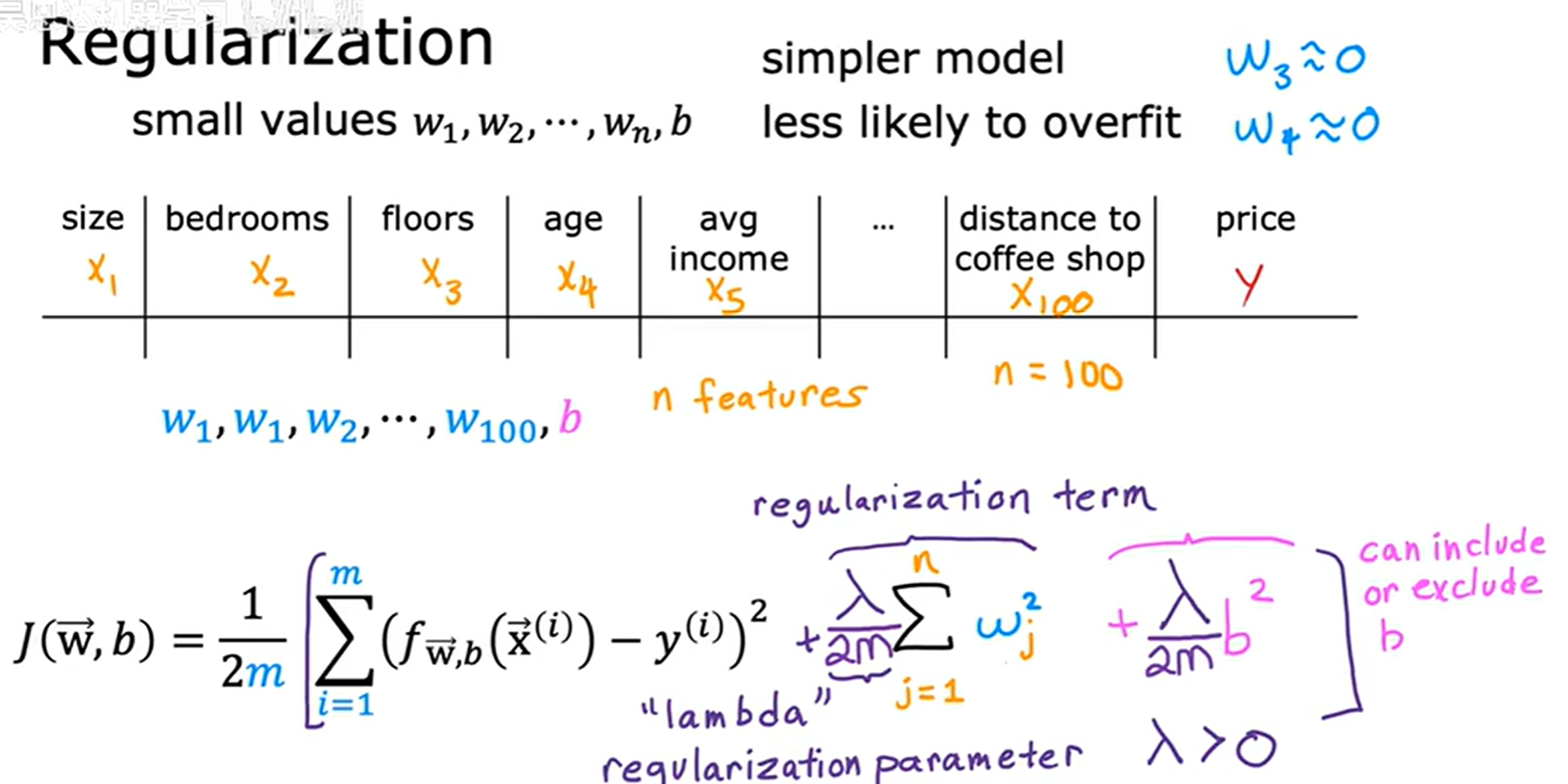
λ λ λ 值指定了相对重要性,权衡两项。
当 λ = 0 λ = 0 λ=0,就会完全没有使用正则化项,最终可能会出现过拟合的情况;
当 λ λ λ 取的非常非常大,例如 λ = 1 0 10 λ = 10^{10} λ=1010,会导致权值特别小,最后欠拟合。

正则化线性回归 (Regularized linear regression)
梯度下降公式推导


加入正则化后,让 w j w_j wj 每回先变为原来的 1 − α λ m 1 - α\frac{λ}{m} 1−αmλ 倍后再进行正常的梯度下降更新,这也是正则化能会在每次迭代中稍微缩小参数 w j w_j wj 的工作原理。
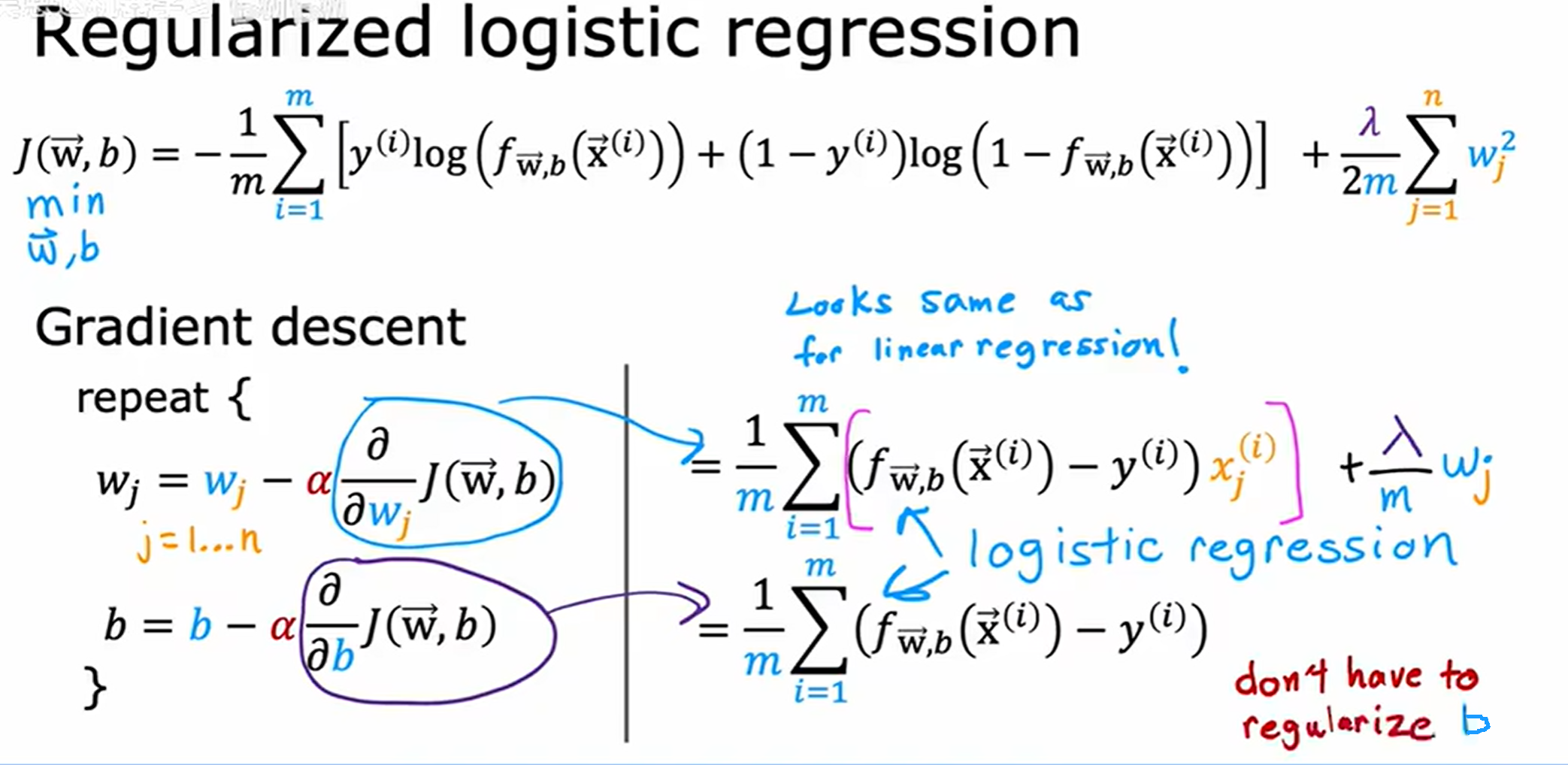
正则化逻辑回归 (Regularized logistic regression)
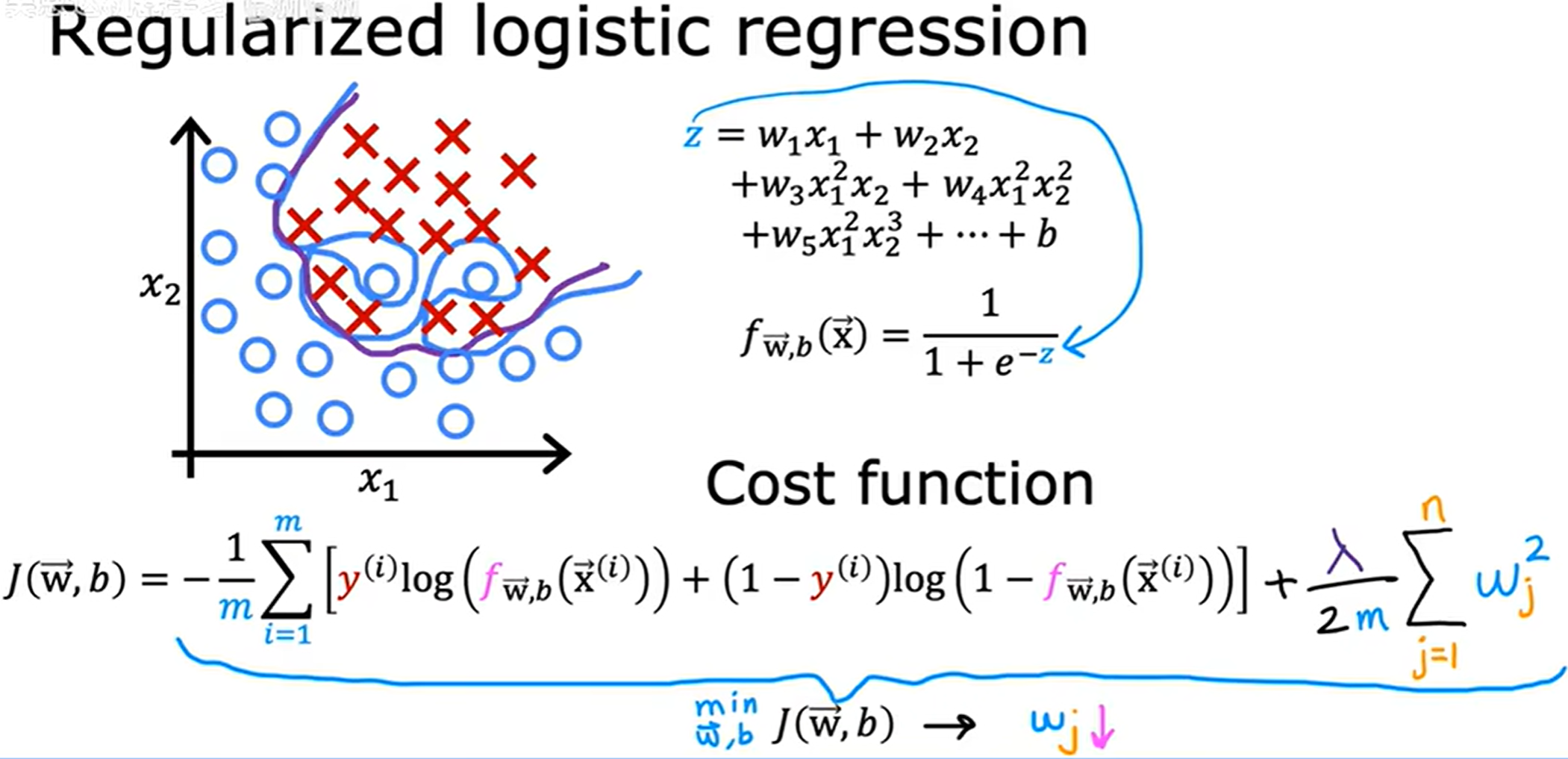
和线性回归相似,加上惩罚项。
计算导数