深度学习模型
一、深度学习简介
定义与原理
深度学习是一种模仿人脑神经网络结构和功能的机器学习方法,通过构建多层神经网络模型,自动从大规模数据中学习复杂的特征表示。其核心原理包括 层次化特征提取 和 端到端学习 :
层次化特征提取:通过多层非线性变换,逐步提取数据的高级语义特征
端到端学习:直接学习输入与输出间的映射关系,无需人工干预
这种机制使深度学习能有效处理高维、非线性数据,在图像识别、语音识别和自然语言处理等领域展现出卓越性能.
发展历程,三个关键阶段
1、萌芽期(1950-2005)
1980年代:卷积神经网络(CNN)雏形出现
1990年代末:LeNet-5提出,奠定深度学习基础
2、沉淀期(2006-2019)
2012年:AlexNet在ImageNet竞赛中获胜,证明深度卷积神经网络的强大能力
2017年:Transformer模型提出,革新自然语言处理领域
3、爆发期(2020-至今)
2020年:GPT-3发布,开启预训练大模型时代
2023年:GPT-4发布,提升多模态理解和生成能力
以及今年的deepseek,,以上这些里程碑事件推动了深度学习在图像识别、自然语言处理等领域的快速发展和广泛应用。
二、常见深度学习模型
卷积神经网络(CNN):是一种专为处理网格状拓扑数据而设计的深度学习模型,尤其擅长处理图像和视频数据。其独特之处在于利用卷积层和池化层来高效地提取和学习图像特征,同时通过多层非线性变换实现复杂模式的识别。
CNN的核心组件包括:
卷积层 :使用一组可学习的滤波器对输入图像进行卷积运算,生成特征图。这一过程能够捕捉图像中的局部特征,如边缘和纹理。
池化层 :主要用于减小特征图的空间尺寸,同时保留最显著的特征。最常见的池化操作是最大池化,即选择区域中的最大值作为下采样后的特征。
全连接层 :负责将卷积层和池化层提取的特征映射到最终的输出类别。全连接层的每个神经元都与前一层的所有神经元相连,实现了特征的全局整合。
CNN的一个关键特性是 权重共享 。在同一卷积层中,同一卷积核在不同位置使用相同的权重参数,这大大减少了模型的参数量,同时也体现了图像局部特征的重要性。
CNN在计算机视觉领域展现出了卓越的性能,主要应用包括:
图像分类 :目标检测 :人脸识别 :
循环神经网络(RNN):是一种专门设计用于处理序列数据的神经网络架构。与传统前馈神经网络不同,RNN具有循环连接,能够在处理序列数据时保留和利用之前的状态信息。这种独特的结构赋予了RNN强大的序列处理能力,使其成为自然语言处理、语音识别等领域的重要工具。

RNN的核心特性包括
记忆能力:RNN通过隐藏状态保留序列中的上下文信息,使得网络能够记住之前的状态。这种记忆机制使得RNN能够捕捉序列中的长期依赖关系,这对于理解自然语言等序列数据至关重要。
参数共享:RNN在不同时间步之间共享参数,这不仅降低了模型的复杂度,还提高了模型在处理不同长度序列时的效率。
RNN也面临一些挑战,主要包括:梯度消失和梯度爆炸 :在训练过程中,RNN可能出现梯度消失或梯度爆炸问题,这会导致模型难以训练或收敛缓慢。特别是对于长序列数据,RNN难以有效地捕捉长距离依赖关系。
在自然语言处理领域,RNN展现了广泛的应用前景:
语言模型 :机器翻译 :情感分析 :语音识别 :文本生成 :
Transformer模型是由Vaswani等人在2017年提出的革命性架构,彻底改变了自然语言处理(NLP)领域。其核心创新在于引入了自注意力机制,巧妙地解决了传统循环神经网络(RNN)在处理长距离依赖关系时面临的困境。
Transformer模型的架构由 编码器-解码器 组成,每个部分包含多个相同的层。这种设计允许模型并行处理输入序列,大幅提升了计算效率。具体而言,Transformer的架构特点包括:
自注意力机制 :通过计算输入序列中任意两个位置之间的关联度,捕捉全局依赖关系。这种方法使得模型能够并行处理输入序列中的每个位置,显著提高了计算效率。
多头注意力 :将自注意力机制分解为多个独立的“头”,每个头独立计算注意力权重,然后将结果拼接在一起。这种设计不仅增加了模型的表示能力,还有助于捕捉输入序列中的不同方面信息。
位置编码 :为解决模型缺乏固有位置概念的问题,Transformer引入了位置编码。这是一种特殊的向量,与单词嵌入向量相加,使得模型能够区分输入序列中词的位置。
残差连接和层归一化 :这些技术的引入有效解决了深层网络训练中的梯度消失问题,提高了模型的稳定性和性能。
Transformer的出现推动了预训练语言模型的发展。随后出现的BERT、GPT等模型都是基于Transformer架构的变体,进一步提升了NLP任务的性能水平。这些预训练模型通过在大规模未标注文本上进行无监督学习,获得了强大的语言理解能力,为下游任务提供了优秀的初始化参数。
生成对抗网络(GAN):生成对抗网络(Generative Adversarial Networks, GAN)是一种革命性的深度学习模型,由Ian Goodfellow等人于2014年提出。GAN的独特之处在于其采用了一种新颖的训练方式,通过两个神经网络的对抗来学习数据分布,从而实现高质量的样本生成。
GAN的核心组成部分包括:生成器(Generator) :负责将随机噪声转化为与真实数据相似的样本。
判别器(Discriminator) :用于判断输入样本是真实数据还是生成器生成的假样本。
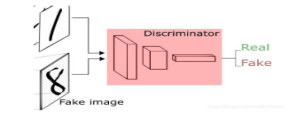
GAN的训练过程可以概括为以下几个关键步骤:
1.生成器接收随机噪声作为输入,生成假样本。
2. 判别器同时接收真实样本和生成样本,输出样本为真实的概率。
3. 根据判别器的输出,计算损失函数并更新生成器和判别器的权重。
在这个过程中,生成器和判别器形成了一个动态的“博弈过程”:
生成器的目标是最大限度地欺骗判别器,使生成的样本尽可能接近真实样本。
判别器的目标是准确地区分真实样本和生成样本。
通过这种对抗训练,GAN能够逐步学习到真实数据的分布特征,并生成高度逼真的样本。
在实际应用中,GAN在图像生成领域展现出了卓越的性能。例如:图像超分辨率 :提升图像质量。图像风格迁移 :GAN能够将一幅图像的风格转移到另一幅图像上,创造出全新的视觉效果。图像修复 :GAN可用于填补图像缺失的部分,重建完整的画面。
三、模型训练与优化
损失函数与优化算法:均方误差MSE,对预测误差平方后求和,能有效抑制模型的过拟合现象。交叉熵损失函数:用于多分类问题,能够同时考虑预测概率的正确性和置信度。
优化算法寻找损失函数最小值的有效方法:随机梯度下降(SGD)

SGD的一个重要特点是其 随机性 。在每一步迭代中,算法只使用一个随机选择的样本(或一个小批量样本)来估算梯度。这种策略大大加快了收敛速度,尤其是在处理大规模数据集时表现突出。
然而,SGD也存在一些局限性,如对学习率的选择敏感,容易陷入局部最优等。为克服这些缺点,研究者们提出了多种改进版本,其中最具代表性的是 Adam优化算法 。
Adam算法巧妙地结合了动量法和RMSprop算法的优点,通过维护梯度的一阶矩估计和二阶矩估计,为每个参数动态调整学习率。其更新规则为:

Adam算法具有以下优势:
收敛速度快:通过自适应学习率,能在不同参数间自动调整更新步长。
计算效率高:仅需维护一阶和二阶矩估计,占用内存少。
适用于非平稳目标函数:能有效应对目标函数随时间变化的情况。
适用于稀疏梯度问题:在处理高维稀疏数据时表现良好。
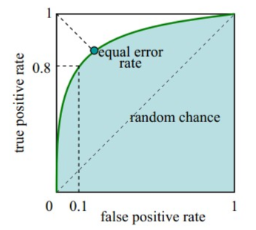
模型评估指标
roc曲线, auc指标判断准确率
深度学习框架::TensorFlow,PyTorch。在实际应用中,PyTorch应用广泛。
深度学习模型具体应用::
图像分类 :ResNet等深度CNN模型通过多层卷积和残差连接,有效解决了深层网络的梯度消失问题,显著提高了分类精度。
目标检测 :Faster R-CNN通过引入区域生成网络(RPN),实现了端到端的目标检测,大幅提升了检测速度和准确性。
语义分割 :U-Net等网络结构通过跳跃连接和上采样操作,实现了多尺度信息融合,提高了分割的精细度。
大语言模型:gpt,deepseek、豆包等
参考来源
https://blog.csdn.net/Java_rich/article/details/143023422
