GCoNet+:更强大的团队协作 Co-Salient 目标检测器 2023 GCoNet+(翻译)
摘要
摘要:本文提出了一种新颖的端到端群体协作学习网络,名为GCoNet+,它能够高效(每秒250帧)且有效地识别自然场景中的共同显著目标。所提出的GCoNet+通过基于以下两个关键准则挖掘一致性表示,实现了共同显著目标检测(CoSOD)领域的最新最优性能:1)组内紧凑性,利用我们全新的群体亲和模块(GAM)捕捉共同显著目标内在的共享属性,从而更好地构建这些目标之间的一致性;2)组间可分离性,引入我们新的群体协作模块(GCM),以不一致的一致性特征为条件,有效抑制噪声目标对输出结果的影响。 为了进一步提高检测精度,我们设计了一系列简单但有效的组件,具体如下:其一,循环辅助分类模块(RACM),在语义层面促进模型学习;其二,置信度增强模块(CEM),帮助模型提升最终预测结果的质量;其三,基于群体的对称三元组(GST)损失函数,引导模型学习更具判别性的特征。 在三个具有挑战性的基准数据集,即CoCA、CoSOD3k和CoSal2015上进行的大量实验表明,我们的GCoNet+优于现有的12种前沿模型。代码已在https://github.com/ZhengPeng7/GCoNet plus上发布。
一 介绍
共同显著目标检测(CoSOD)旨在检测一组给定的相关图像中最为常见的显著目标。与标准的显著目标检测(SOD)任务相比,共同显著目标检测更具挑战性,它需要区分不同图像中同时出现的目标,而其中其他目标则充当干扰因素。 为此,类内紧凑性和类间可分离性是两个重要的线索,应当同时进行学习。随着最新的共同显著目标检测方法在准确性和效率方面不断提升,共同显著目标检测不仅被用作其他视觉任务的预处理组件(如文献[2]至[6]所述),而且还被应用于许多实际场景中(如文献[1]、[7]、[8]所提及)。
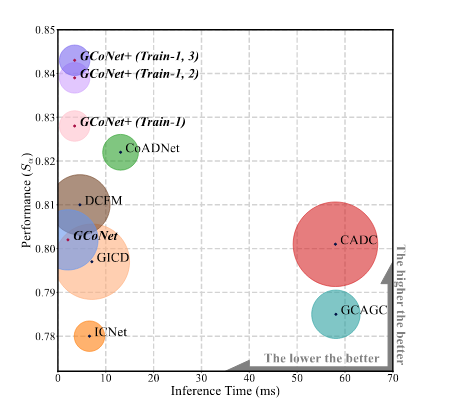
图1. 七种具有代表性的共同显著目标检测(CoSOD)方法与我们的方法在CoSOD3k数据集[9]上的比较。我们从速度(横轴)和准确性(纵轴)两方面对现有的基于深度学习的具有代表性的CoSOD方法进行了比较。气泡越小意味着模型越轻量。我们的GCoNet+在效率和效果两方面均优于这些模型。“训练集1、训练集2和训练集3”分别代表DUTS类别数据集、COCO-9k数据集和COCO-SEG数据集(更多相关细节见表3)。所有模型均在A100-80G上以批量大小为2进行测试。我们的推理速度基准测试结果可在https://github.com/ZhengPeng7/CoSOD fps collection上查看。
现有的研究工作试图通过利用语义连接[10]-[12]或各种不同的共享线索[13]-[15],来增强给定图像之间的一致性,从而解决图像组内的共同显著目标检测(CoSOD)任务。在文献[9]、[16]中,所提出的模型联合优化一个统一的网络,用于生成显著性图和共同显著性信息。 尽管这些方法带来了一定的改进,但大多数现有模型仅依赖于单个图像组内的一致性特征表示[16]-[21],这可能会带来以下局限性。首先,来自同一图像组的图像只能提供不同目标之间的正相关关系,而不能同时提供正相关和负相关关系。仅用来自单个组的正样本训练模型,可能会导致过拟合,并且对于离群图像会产生模糊的结果。此外,通常一个图像组中的图像数量有限(在现有的共同显著目标检测数据集上,大多数组的图像数量在20到40张之间)。因此,从单个组中学习到的信息,通常不足以形成具有判别性的表示。最后,单个图像组可能不容易挖掘语义线索,而这些语义线索在复杂的现实场景测试中,对于区分噪声目标至关重要。由于现实场景中图像上下文的复杂性,非常需要一个专门用于挖掘共同信息的模块。 除此之外,当使用二元交叉熵(BCE)损失函数进行监督训练时,生成的显著性图的像素值往往更接近0.5,而不是0或1。由于存在这种不确定性,这些显著性图很难直接应用于实际应用中。
为了克服上述限制,我们提出了一种新的群体协作学习网络(GCoNet),它能够在同一图像组内建立语义一致性,并区分不同的图像组。 我们的GCoNet包含三个基本模块:群体亲和模块(GAM)、群体协作模块(GCM)和辅助分类模块(ACM),这三个模块同时引导GCoNet以更好的方式学习组间可分离性和组内紧凑性。具体而言,群体亲和模块(GAM)使模型能够学习同一图像组内的一致性特征,而群体协作模块(GCM)则用于判别不同组之间的目标属性,从而使得该网络能够在现有的丰富的显著目标检测(SOD)数据集上进行训练。 为了学习到更好的嵌入空间,我们在每一幅图像上使用辅助分类模块(ACM),以便在全局语义层面上改进特征表示。
我们对原有的GCoNet进行了改进,具体体现在以下方面:对现有成果给出了更精确的阐释,即构建了一个用于共同显著目标检测(CoSOD)的简洁网络;新增了三个组件,这些组件能够提升学习一致性和差异性的能力;同时,我们还对现有训练集的不足展开了探讨,并给出了相应的解决办法。

图2. 特征图可视化。(a) 源图像和真实标注。(b-f) 分别为我们的GCoNet [1]和GCoNet+(对应表3中的训练集1)解码器不同层级的特征图,按从高层到低层的顺序捕捉。(b) 中所示的特征图分辨率最低。如 (b) 所示,我们的GCoNet+ 给出了更具全局性的响应,并且在非常早期的阶段不会做出特定的预测,因为在这个阶段特征图的质量不足以产生精确的结果。(g) 共同显著性图的预测结果。与GCoNet相比,GCoNet+ 在目标及其周围区域获得了更具全局性的响应。
总而言之,我们已将我们的GCoNet大幅扩展为GCoNet+,主要差异如下:
创新方法。我们提出了三个新组件,以提升 GCoNet + 的性能和鲁棒性,分别是置信度增强模块(CEM)、基于群组的对称三元组(GST)损失函数以及循环辅助分类模块(RACM),用以解决我们的 GCoNet 模型现有的不足之处。(1)置信度增强模块(CEM):为了减少输出图的不确定性,我们在置信度增强模块中采用了可微二值化方法和混合显著性损失函数。这能够生成质量更高的图,并进一步提升整体性能。(2)基于群组的对称三元组(GST)损失函数:我们是最早将度量学习应用于基于深度学习的共同显著目标检测(CoSOD)模型的团队之一。通过度量学习的方式,这使得不同群组所学习到的特征更具判别性。(3)循环辅助分类模块(RACM):为了更好地表示辅助分类特征,我们将原始的辅助分类模块扩展为循环版本,它能更精确地聚焦于目标物体的像素。此外,我们对 GCoNet [1] 进行了改进,使其成为一个更轻量且更强大的网络,以此作为我们的基线模型。在实验中,这三个组件与新的基线网络有机结合,在所有现有数据集以及实际应用中都取得了优异的性能表现。
实验。尽管共同显著目标检测领域发展迅速,但目前通常有三个用于训练的数据集,即 DUTS 类别数据集、COCO-9k 数据集和 COCO-SEG 数据集,然而对于这项任务而言,并没有选择训练集的标准。与现有研究中所使用的训练集各不相同的情况不同,为了进行公平的实验对比,我们针对这三个训练集的所有不同组合进行了更全面的实验。如前文 “创新方法” 部分所述,结合本文新提出的组件,与使用相同训练集的 GCoNet [1] 相比,我们在 Eξmax [22] 和 Sα[23] 指标上取得了约 3.2% 的相对提升,在目前所有公开可用的共同显著目标检测(CoSOD)模型 [9] 中达到了当前最先进的性能水平。
新的见解。基于所获得的实验结果,我们发现了现有共同显著目标检测(CoSOD)训练集存在的潜在问题,并针对未来如何改进这些训练集给出了相应的分析。