MIX-LN: UNLEASHING THE POWER OF DEEP LAYERS BY COMBINING PRE-LN AND POST-LN
TL;DR
- ICLR 2025 大连理工发表的文章,提出了一种新型的归一化技术——Mix-LN,它结合了 Pre-LN 和 Post-LN 的优点,并将它们应用于同一个模型中。Mix-LN 将 Post-LN 应用于浅层,将 Pre-LN 应用于深层,从而确保整个网络的梯度更加均匀。
Paper name
MIX-LN: UNLEASHING THE POWER OF DEEP LAYERS BY COMBINING PRE-LN AND POST-LN
Paper Reading Note
Paper URL:
- https://arxiv.org/pdf/2412.13795
Introduction
背景
- 一些研究发现 LLM 深层往往贡献较小,且在不影响整体性能的情况下可以进行剪枝。本文认为这实际上是由于广泛使用**“预层归一化”(Pre-LN)而导致的训练不足**
- 像 GPT 和 LLaMA 等模型中常用的 Pre-LN 会导致深层的梯度范数较小,从而降低其有效性。相比之下,“后层归一化”(Post-LN)能够在深层保持较大的梯度范数,但会在浅层导致梯度消失。
本文方案
- 提出了一种新型的归一化技术——Mix-LN,它结合了 Pre-LN 和 Post-LN 的优点,并将它们应用于同一个模型中。Mix-LN 将 Post-LN 应用于浅层,将 Pre-LN 应用于深层,从而确保整个网络的梯度更加均匀。
- 从 70M 到 7B 不同规模的模型进行了大量实验,Mix-LN 始终优于 Pre-LN 和 Post-LN
- 使用 Mix-LN 预训练的模型,在有监督微调(SFT)和基于人类反馈的强化学习(RLHF)中学习效果更好
Methods
评估 LN 位置影响
- 作为 Post-LN 模型,BERT-Large 的早期层的有效性不如深层。作为 Pre-LN模型,LLaMa2-7B 最不有效的层位于深层
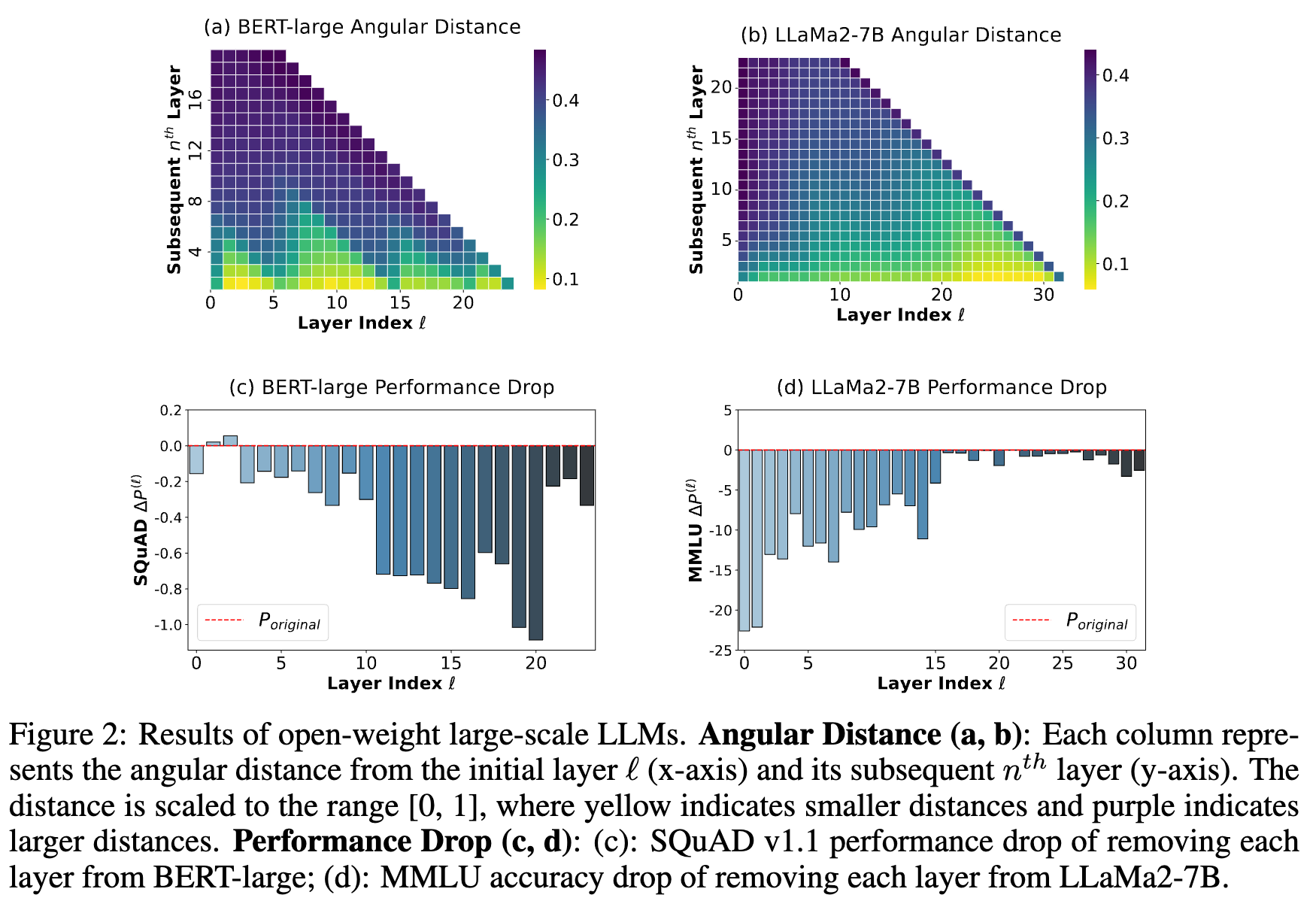
- 基于内部小模型验证。在 Post-LN 模型中,最相似的层集中在早期阶段,前 3 层的距离特别小。随着深度的增加,层之间变得越来越具有区分度。相比之下,Pre-LN LLaMa-130M 随着深度的增加,角度距离逐渐减小,导致深层之间非常相似。在Post-LN中,删除早期层(例如0-7层)几乎不会导致性能损失,而删除深层(尤其是9-11层)则对维持原始性能至关重要。Pre-LN LLaMa-130M 展示了相反的趋势,删除大部分层后(除第一层外)几乎不会导致性能损失,说明这些层对模型输出贡献不大
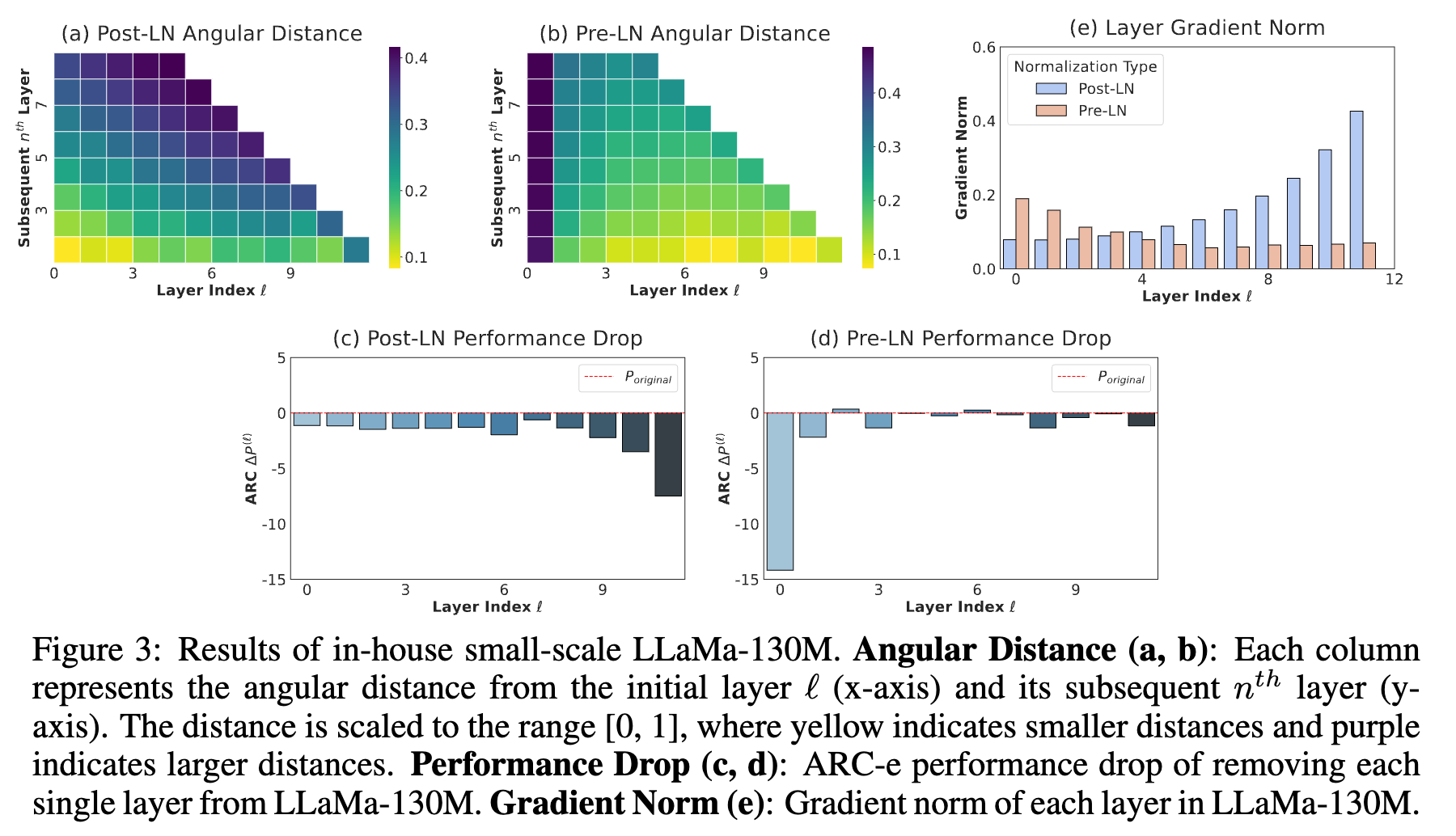
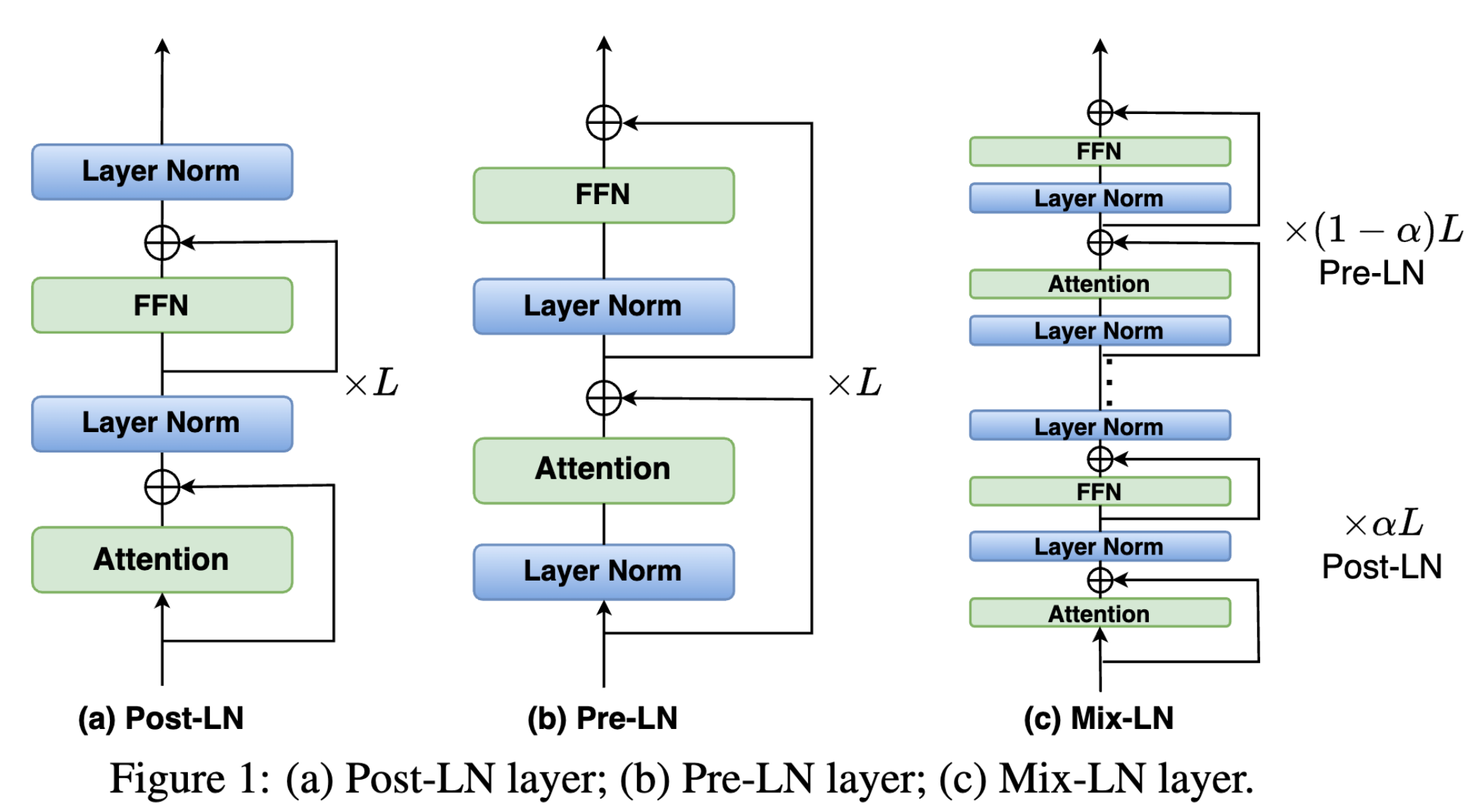
混合层归一化(Mix-LN)
- Post-LN被证明在提升深层的有效性方面具有优势,而Pre-LN对早期层更有效。因此,我们建议在初始层应用Post-LN,而在后续层应用Pre-LN,从而确保中间层和深层都能受益于这两种方法的优势。
Experiments
- perplexity:Post-LN通常表现最差,甚至在较大模型中出现发散。确认了Post-LN的严重训练不稳定性,早期层的梯度消失,导致模型无法正常收敛。Mix-LN在各种模型规模下始终实现了最低的困惑度
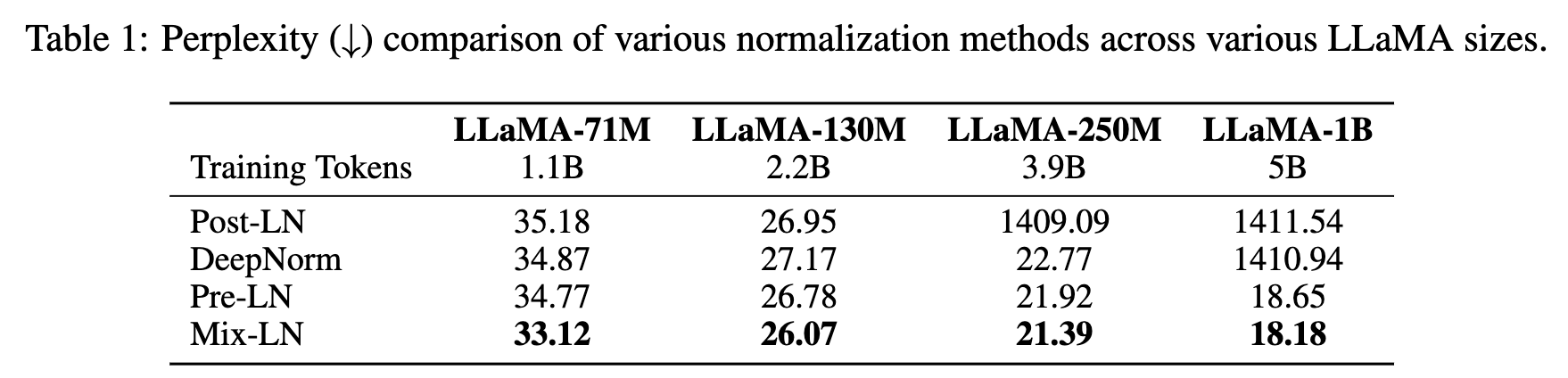
- 7B 规模的验证也是 MixLN 好
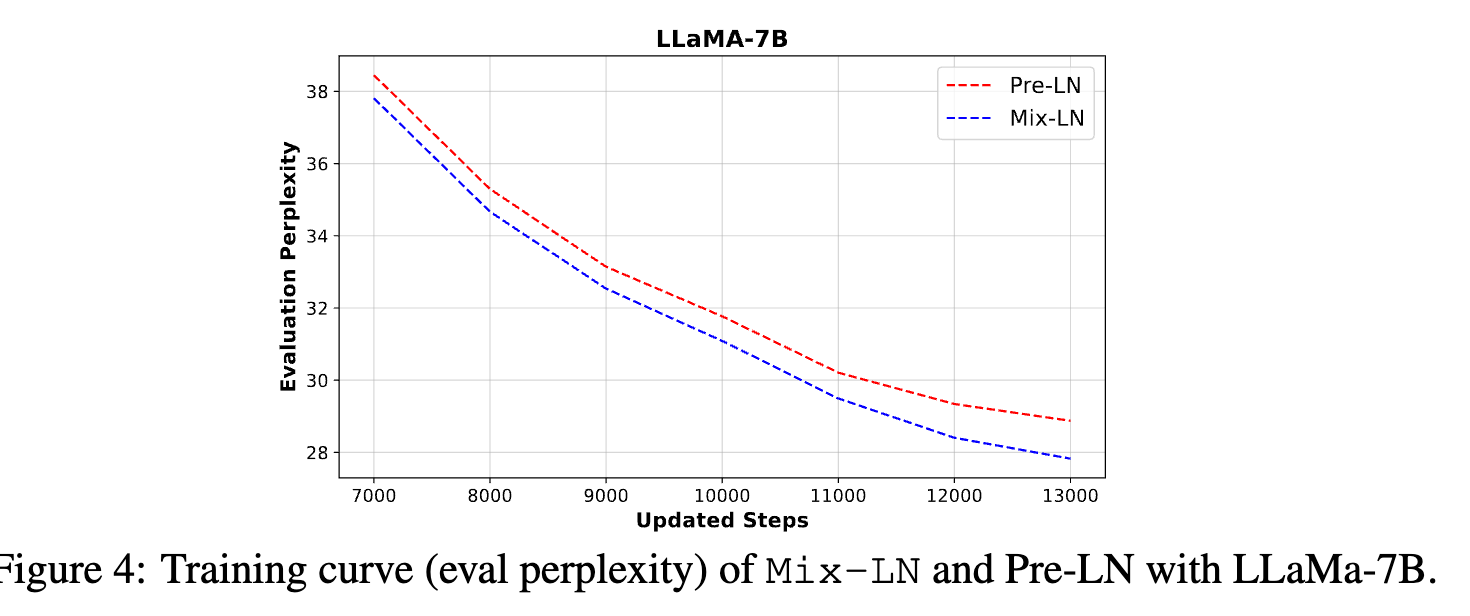
- RLHF 上也能保持优势

- 视觉模型上也能有优势
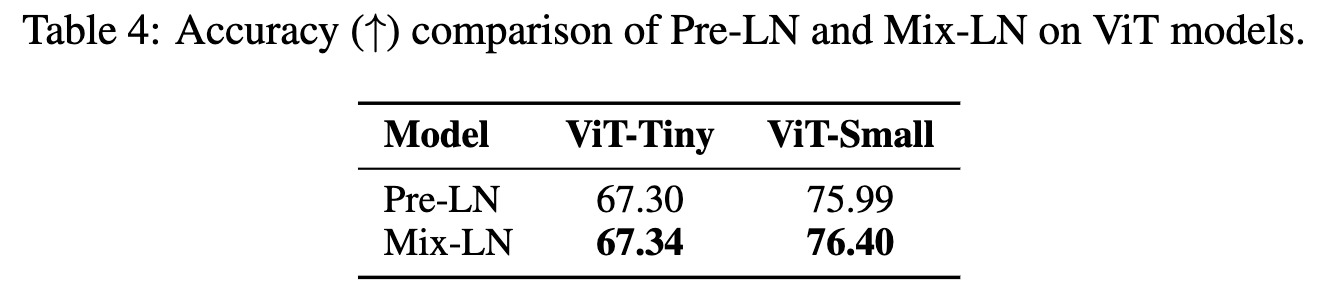
Conclusion
- 比较简单的想法,同时利用 post LN 和 pre LN 的特点,能在不同的网络上取得收敛效果的提升