游戏数据分析,力扣(游戏玩法分析 I~V)mysql+pandas
力扣的游戏玩法分析 I~V,
ps:虽然表结构不变但是力扣输入示例数据有些许变化,所以你使用上一题的数据跑下一题的代码可能产生的结果和示例中的不一样,建议点击连接到力扣中直接运行!
目录
1. 游戏玩法分析 I
mysql
pandas
2.游戏玩法分析 II
mysql
pandas
3.游戏玩法分析III
mysql
pandas
4.游戏数据分析IV
mysql
pandas
5.游戏玩法分析 V (困难题)
pandas
mysql
1. 游戏玩法分析 I
链接:游戏玩法分析 I

思路:根据player_id分组后返回分组内时间最小的那个。
mysql
-- 思路
-- 根据player_id分组后返回分组内时间最小的那个。
select
player_id,min(event_date) as first_login
from activity group by player_id order by event_date ascpandas
import pandas as pddef game_analysis(activity: pd.DataFrame) -> pd.DataFrame:return activity.groupby(by='player_id')['event_date'].min().reset_index(name='first_login')[['player_id','first_login']]2.游戏玩法分析 II
游戏玩法分析II
表结构不变,问题:请编写解决方案,描述每一个玩家首次登陆的设备名称

思路:mysql 可以使用rank()按照player_id分区后按照时间升序排名,然后保留排名列为1的行。
pandas 直接全表按照时间排序,然后直接指定drop_duplicates的subset参数为player_id,keep参数为first,即为每个player_id去重,保留第一行。(当然,选择和mysql一样分组后按照时间排名也可以,但是写起来麻烦一些,不如这个直接)
mysql
# Write your MySQL query statement below-- 思路
-- 按照player_id分区后按照时间排名,保留排名为1的列select player_id,device_id
from
(
select
player_id,device_id,rank() over(partition by player_id order by event_date) as rk
from activity
) t where rk = 1pandas
import pandas as pddef game_analysis(activity: pd.DataFrame) -> pd.DataFrame:activity.sort_values(by='event_date',ascending = True,inplace=True)activity.drop_duplicates(subset='player_id',keep='first',inplace=True)return activity[['player_id','device_id']]3.游戏玩法分析III
游戏玩法分析III
表结构不变,问题:编写一个解决方案,同时报告每组玩家和日期,以及玩家到 目前为止 玩了多少游戏。也就是说,玩家在该日期之前所玩的游戏总数。
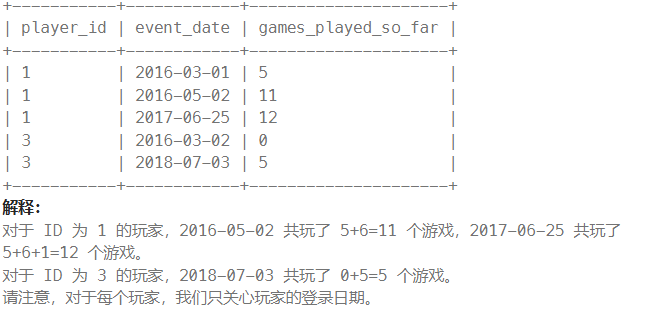
思路:mysql:分区排序后计算从第一行到当前行的累计和,注意不要看串列了(博主当时就犯错误了,错误写法在下方)
pandas,按照时间排序后直接对player_id分组后聚合cumsum求累计和。
mysql
正确写法
# Write your MySQL query statement below-- 思路,分区排序后,计算从第一行到当前行的和。
-- 有毒点
select
player_id,event_date,
sum(games_played)
over(partition by player_id order by event_date asc rows between unbounded preceding and current row ) as games_played_so_far
from activity错误写法
-- 错误写法
SELECT player_id,event_date,SUM(games_played) OVER (PARTITION BY player_id ORDER BY event_date ASC ROWS BETWEEN 2 PRECEDING AND CURRENT ROW) AS games_played_so_far
FROM activity;
错误原因在于累计和结果是作为一个新列的,而博主当时一时糊涂看串了,想成结果记录在当前列了,所以想当然的以为当前行和前一行相加,从头加到尾就和从第一行累加到当前行结果一样,实则不然。
pandas
import pandas as pd# 排序日期,分组计算累计和
def gameplay_analysis(activity: pd.DataFrame) -> pd.DataFrame:activity.sort_values(by='event_date',ascending=True,inplace=True)activity['games_played_so_far'] = activity.groupby(by='player_id')['games_played'].cumsum()return activity[['player_id','event_date','games_played_so_far']]# 题目没有要求输出顺序,如果为了看着顺眼,排序规则改成by = ['player_id','event_date'] 按照player_id 的顺序输出4.游戏数据分析IV
游戏数据分析IV
表结构不变,问题:编写解决方案,报告在首次登录的第二天再次登录的玩家的 比率,四舍五入到小数点后两位。换句话说,你需要计算从首次登录日期开始至少连续两天登录的玩家的数量,然后除以玩家总数。

思路:mysql与pandas都是先获取每个用户第一天登录日期然后手动加一获得第二天日期,到原表中匹配该用户有没有第二天日期的登陆记录,根据结果计数,再与用户数进行求比率。
mysql
需要注意的是,最后使用两个子查询时,用max()或者 min()去使得tar_num.num成为聚合结果,因为count(distinct second.player_id)是聚合结果,如果直接使用tar_num.num去和它进行除法会报错,需要都是聚合结果才能进行计算。
with second as
(
select player_id,date_add(min(event_date),interval 1 day) as second_login
from activity group by player_id
)
,
tar_num as (
select count(1) as num
from activity a join second s on a.player_id = s.player_id and a.event_date = s.second_login
)select round((max(tar_num.num) / count(distinct second.player_id)),2)as fraction from second,tar_numpandas
连表方式的how参数,不写或者写inner只保留有匹配记录的行了。对其计数就是符合条件的用户数。
def gameplay_analysis(activity: pd.DataFrame) -> pd.DataFrame:# 思路:先找到第一次登录日期,然后得到第二天登录日期,到表中寻找是否有这个日期的登录记录,.df = activity.groupby(by='player_id')['event_date'].min().reset_index(name='first_login')df['second'] = df['first_login'] + pd.DateOffset(days=1)df_2 = pd.merge(left=activity,how='inner',right=df,left_on=['player_id','event_date'],right_on=['player_id','second'])tar = df_2['second'].count()num = activity['player_id'].nunique()return pd.DataFrame({'fraction':[round(tar/num,2)]})5.游戏玩法分析 V (困难题)
游戏玩法分析 V
表结构不变,问题:
玩家的 安装日期 定义为该玩家的第一个登录日。
我们将日期 x 的 第一天留存率 定义为:假定安装日期为 X 的玩家的数量为 N ,其中在 X 之后的一天重新登录的玩家数量为 M,M/N 就是第一天留存率,四舍五入到小数点后两位。
编写解决方案,报告所有安装日期、当天安装游戏的玩家数量和玩家的 第一天留存率。
以 任意顺序 返回结果表。

思路:
博主在这题栽了大跟头,主要在python内置的小数点舍入函数上round()上
本题目没有好好读清楚题目会原地爆炸
博主改了好几版,最终做到每次跑都是超越100%
注意点:
1. 注册日期 下一天登录 也登陆才是题目所需的留存。 连续两天登录,只要前一天不是驻日日期就不算(容易忽略这个条件)
2. 需要的分母是当天的注册数,而不是当天登录数
3. 结果只需要有产生注册的日期。
pandas
1. 先获取用户注册的日期,这也是后续结果中要的日期(产生注册的日期)
2. 使用这份注册日期作为左表与原记录表做左连接,连接键为用户id,那么留下的就只有这些注册用户的记录。这些用户在注册的第二天是否登录视为是否留存。对连接结果判断登录日期是否是隔天的,留下符合的记录,然后按照日期统计包含的用户数,就是留存数。
df_install = activity.groupby(by='player_id')['event_date'].min().reset_index(name='install_dt')
df = pd.merge(left=df_install,right=activity,how='left',on='player_id')
date_vaild = (df['event_date'] - df['install_dt']).dt.days==1
df_stay = df[date_vaild].groupby(by='install_dt')['player_id'].count().reset_index(name='stay_num') 3. 还需要统计产生注册的日期中有多少用户注册了。这一步相比统计留存数,少了一步判断登录日期是否隔天。
df_install_2 = df_install.groupby(by='install_dt')['player_id'].count().reset_index(name='installs')4.接下来就是按照日期连接表格然后对两列做除法了。但是本题的难点在于使用round()去舍入小数点不符合其要求。虽然没有明说哪种方式,但是解决此题时观察输出结果不难意识到是对舍入精度的要求不同。两者的区别可以看这篇文章:round与decimal舍入区别
ps:
# 正确写法
df_res = pd.merge(left=df_install_2,right=df_stay,on='install_dt',how='left').fillna(0)
df_res['Day1_retention'] = df_res['stay_num'] / df_res['installs']
df_res['Day1_retention'] = df_res['Day1_retention'].apply(lambda x: Decimal(x).quantize(Decimal('.00'), rounding=ROUND_HALF_UP))#错误写法
df_res = pd.merge(left=df_install_2,right=df_stay,on='install_dt',how='left').fillna(0)
df_res['Day1_retention'] = round(df_res['stay_num'] / df_res['installs'],2)
完整代码
import pandas as pd
from decimal import Decimal, ROUND_HALF_UP
def gameplay_analysis(activity: pd.DataFrame) -> pd.DataFrame:df_install = activity.groupby(by='player_id')['event_date'].min().reset_index(name='install_dt')df = pd.merge(left=df_install,right=activity,how='left',on='player_id')date_vaild = (df['event_date'] - df['install_dt']).dt.days==1df_stay = df[date_vaild].groupby(by='install_dt')['player_id'].count().reset_index(name='stay_num')df_install_2 = df_install.groupby(by='install_dt')['player_id'].count().reset_index(name='installs')df_res = pd.merge(left=df_install_2,right=df_stay,on='install_dt',how='left').fillna(0)df_res['Day1_retention'] = df_res['stay_num'] / df_res['installs']df_res['Day1_retention'] = df_res['Day1_retention'].apply(lambda x: Decimal(x).quantize(Decimal('.00'), rounding=ROUND_HALF_UP))return df_res[['install_dt','installs','Day1_retention']]mysql
可以照着pandas的思路写,
就是sql写起来麻烦点, mysql 中使用round可以达到题目的精度。
WITH t_install AS ( SELECT player_id, min( event_date ) AS install_dt FROM activity GROUP BY player_id ),
t_stay AS (SELECTinstall_dt,count( player_id ) AS stay_num FROM(SELECTts.player_id,ts.install_dt FROMt_install tsLEFT JOIN activity a ON ts.player_id = a.player_id WHEREDATEDIFF( a.event_date, ts.install_dt ) = 1 ) tem GROUP BYinstall_dt ),t_install_2 AS ( SELECT install_dt, count( player_id ) AS installs FROM t_install GROUP BY install_dt ) SELECTts2.install_dt,installs,IFNULL( ROUND( stay_num / installs, 2 ), 0 ) AS Day1_retention
FROMt_install_2 ts2LEFT JOIN t_stay ty ON ts2.install_dt = ty.install_dt