【软件测试】性能测试概念篇
1. 性能测试的定义
性能测试是通过模拟真实用户行为、系统负载或极端条件,评估软件系统在特定场景下的响应能力、稳定性、资源消耗及扩展性的过程。其核心目标是:
- 验证系统容量:确保系统在预期负载下(如双十一秒杀)满足性能指标(如每秒处理5000笔订单)。
- 定位瓶颈:识别代码、中间件或硬件瓶颈(如数据库慢查询、线程池满)。
- 预测风险:评估系统在超负载或长时间运行时的行为(如内存泄漏、服务雪崩)。
典型案例:某社交平台新版本发布后,因未对消息推送接口进行压测,导致晚高峰时消息延迟高达10秒,最终通过优化Redis集群配置解决。
2. 性能测试的常见指标
2.1 吞吐量(Throughput)
- 定义:单位时间内的有效事务处理量,体现系统处理能力。
- 计算方式:
- QPS(查询类接口):
SELECT COUNT(*) FROM logs WHERE time > '2023-01-01'QPS = 总成功请求数 ÷ 测试时间(秒) - TPS(事务类接口):支付接口要求TPS ≥ 2000(每秒处理2000笔交易)。
- QPS(查询类接口):
这里的事务是人为定义的,所以在使用 TPS 来作为指标时,一定要有相同的参照物。
- 行业案例:支付宝2023年双十一峰值TPS达61万,Visa网络全球峰值TPS为6.5万。
2.2 并发数(Concurrency)
- 定义:系统同时处理的活跃请求数,反映实际负载压力。
- 业务模型:
示例:某在线教育平台日活50万,平均课程加载耗时1.2秒,实际并发≈(500000/86400)*1.2 ≈ 7实际并发数 ≈ (日均请求量 / 86400秒) × 平均响应时间(秒) - 配置参考:Tomcat默认线程池200,需根据压测结果调整。
2.3 响应时间(Response Time)
- 分位值意义:
分位点 业务影响 优化优先级 P50 基础体验 中 P90 核心用户 高 P99 极端情况 紧急 - 优化案例:某银行转账接口P99从800ms优化至300ms,通过异步化改造和数据库索引优化实现。
2.4 并发数,吞吐量和响应时间之间的关系
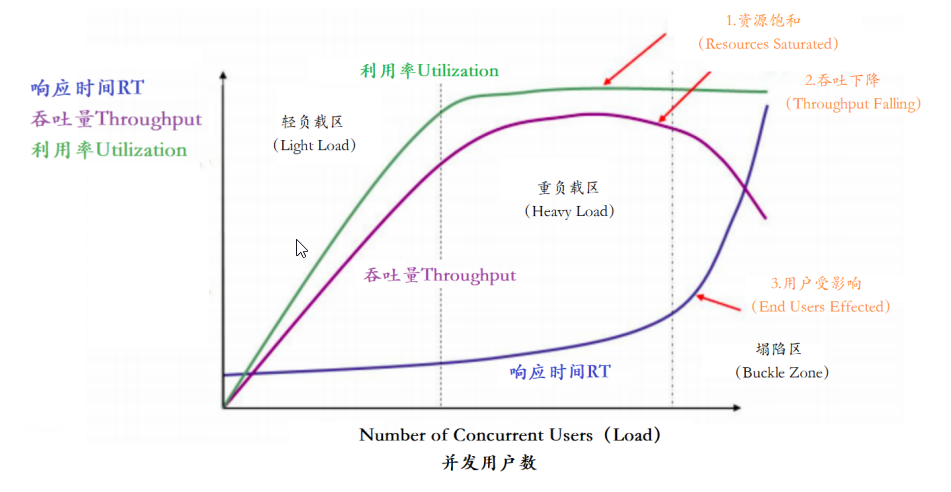
解释一下这张图
一、吞吐量(Throughput)变化规律
1. 轻负载区(Light Load)
- 变化规律:吞吐量 线性快速上升
- 原因:
- 系统资源(CPU、内存、I/O)充足,处理请求无需等待
- 请求处理管道(如Tomcat线程池、数据库连接池)未达到容量上限
- 示例:当并发数从10增至100时,QPS从200升至2000
2. 重负载区(Heavy Load)
- 变化规律:吞吐量 达到峰值后逐渐下降
- 原因:
- 关键资源(如数据库连接、线程池)达到容量限制,新请求开始排队
- 资源竞争导致处理效率降低(如CPU上下文切换频繁)
- 示例:当并发数超过500时,QPS从5000峰值下降至4500
3. 拥堵区(Buckle Zone)
- 变化规律:吞吐量 断崖式下跌
- 原因:
- 系统过载引发雪崩效应(如缓存击穿、服务熔断)
- 错误率飙升(如HTTP 503、数据库死锁)
- 示例:并发数突破1000时,QPS从4500骤降至800
二、响应时间(Response Time, RT)变化规律
1. 轻负载区
- 变化规律:响应时间 基本稳定
- 原因:
- 请求无需排队,资源即时响应
- 无锁竞争或I/O等待延迟
- 示例:并发数100时,RT稳定在50ms
2. 重负载区
- 变化规律:响应时间 显著非线性上升
- 原因:
- 请求排队等待资源(如数据库连接池满)
- 同步阻塞操作增多(如线程等待锁释放)
- 示例:并发数500时,RT从50ms升至300ms
3. 拥堵区
- 变化规律:响应时间 指数级飙升
- 原因:
- 队列深度指数增长(如Tomcat积压请求超过
acceptCount) - 系统频繁触发超时重试(如HTTP重试风暴)
- 示例:并发数1000时,RT从300ms飙升至5s
- 队列深度指数增长(如Tomcat积压请求超过
三、资源利用率(Utilization)变化规律
1. 轻负载区
- 变化规律:利用率 线性增长
- 原因:
- 资源逐步被请求占用(如CPU从20%升至70%)
- 无资源闲置浪费
- 示例:并发数100时,CPU利用率从30%升至65%
2. 重负载区
- 变化规律:利用率 达到阈值后趋于平稳
- 原因:
- 资源容量达到物理极限(如CPU已达90%无法突破)
- 资源调度开销增加(如线程切换消耗CPU)
- 示例:并发数500时,CPU稳定在92%
3. 拥堵区
- 变化规律:利用率 波动或下降
- 原因:
- 错误请求导致资源浪费(如建立TCP连接后立即超时断开)
- 系统过载保护机制生效(如熔断降级丢弃部分请求)
- 示例:并发数1000时,CPU利用率从92%降至85%
关键变化机理与优化策略
| 指标 | 变化驱动因素 | 优化方法 |
|---|---|---|
| 吞吐量 | 资源容量与调度效率 | 水平扩展(Kubernetes自动扩缩容) |
| 响应时间 | 队列深度与处理延迟 | 异步化改造(消息队列削峰填谷) |
| 利用率 | 资源争用与错误处理开销 | 精细化资源分配(CPU绑核、内存分池) |
3. 性能测试关注点
不同角色的核心关注方向
| 角色 | 关注重点 | 典型场景 |
|---|---|---|
| 软件测试人员 | 接口级性能(如 API 吞吐量、错误率) | 使用 JMeter 压测支付接口 |
| 开发人员 | 代码执行效率(如 GC 频率、线程阻塞) | 分析 JVM 内存泄漏 |
| 运维人员 | 基础设施负载(如 CPU 利用率、网络带宽) | 监控 Kubernetes 集群资源水位 |
| 业务方 | 用户体验(如页面加载时间) | 首屏渲染 ≤ 2s |
4. 性能测试分类与实施
4.1 基准测试
- 实施步骤:
- 单用户执行核心功能(如商品搜索)
- 记录无竞争条件下的性能基线
- 输出示例:
接口 P99响应时间 CPU使用率 /api/search 120ms 45% /api/checkout 250ms 60%
4.2 负载测试
- 阶梯增压策略:
阶段 并发数 持续时间 监控重点 预热 100 5分钟 JVM编译状态 爬坡 100→500 10分钟 线性扩展能力 稳态 500 30分钟 资源泄漏迹象
实战案例:某视频平台直播接口在500并发时Nginx返回502错误,原因为Tomcat线程池满(maxThreads从500调整至1000)。
4.3 压力测试
- 破坏性场景:
- 瞬时流量冲击:1秒内并发从100增至5000(模拟微博热搜突发流量)。
- 依赖故障模拟:关闭数据库从节点,验证主节点高可用性。
- 典型问题:某电商系统在300%负载下出现OOM,最终通过堆内存分析定位到缓存未设置TTL。
4.4 稳定性测试
- 实施要点:
- 持续运行12小时,负载为峰值的70%
- 监控内存增长(如JVM老年代内存每小时增长>2%则告警)
- 泄漏案例:某物流系统运行8小时后线程数从200增至2000,原因为HTTP连接未关闭,增加连接池回收策略后解决。
这里画张图来解释一下不同的测试在测试阶段所处的位置
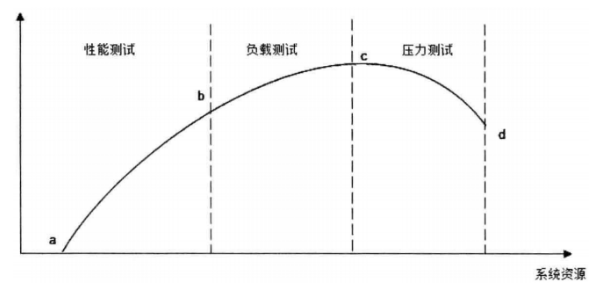
负载测试就是找到资源利用率最大的最大并发数
而压力测试则是寻找使系统崩溃的最大并发数