# 03_Elastic Stack 从入门到实践(三)-- 4
03_Elastic Stack 从入门到实践(三)-- 4
七、Elasticsearch之中文分词器(IK分词器)
1、什么是分词?
分词:就是指将一个文本转化成一系列单词的过程,也叫文本分析,在Elasticsearch中称之为Analysis。
举例:我是中国人–> 我/是/中国人
2、分词 API
1)指定分词器进行分词。
2)示例代码
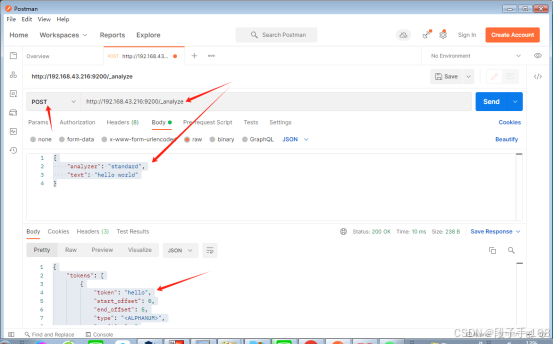
# POST http://192.168.43.216:9200/_analyze{"analyzer": "standard","text": "hello world"
}# 结果:在结果中不仅可以看出分词的结果,还返回该词在文本中的位置。
{"tokens": [{"token": "hello","start_offset": 0,"end_offset": 5,"type": "<ALPHANUM>","position": 0},{"token": "world","start_offset": 6,"end_offset": 11,"type": "<ALPHANUM>","position": 1}]
}3)示例代码2
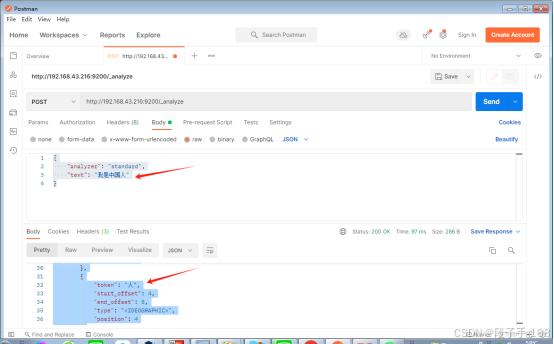
# POST http://192.168.43.216:9200/_analyze{"analyzer": "standard","text": "我是中国人"
}# 结果:在结果中不仅可以看出分词的结果,还返回该词在文本中的位置。
{"tokens": [{"token": "我","start_offset": 0,"end_offset": 1,"type": "<IDEOGRAPHIC>","position": 0},{"token": "是","start_offset": 1,"end_offset": 2,"type": "<IDEOGRAPHIC>","position": 1},{"token": "中","start_offset": 2,"end_offset": 3,"type": "<IDEOGRAPHIC>","position": 2},{"token": "国","start_offset": 3,"end_offset": 4,"type": "<IDEOGRAPHIC>","position": 3},{"token": "人","start_offset": 4,"end_offset": 5,"type": "<IDEOGRAPHIC>","position": 4}]
}4)指定索引分词
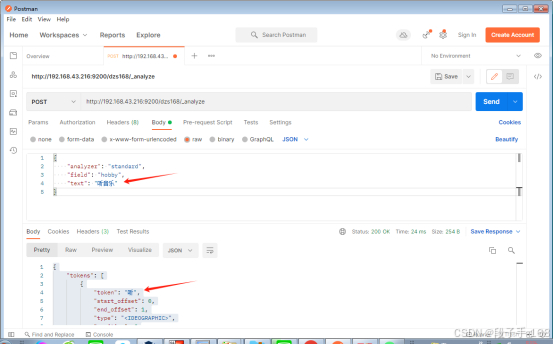
# POST http://192.168.43.216:9200/dzs168/_analyze{"analyzer": "standard","field": "hobby","text": "听音乐"
}# 结果:
{"tokens": [{"token": "听","start_offset": 0,"end_offset": 1,"type": "<IDEOGRAPHIC>","position": 0},{"token": "音","start_offset": 1,"end_offset": 2,"type": "<IDEOGRAPHIC>","position": 1},{"token": "乐","start_offset": 2,"end_offset": 3,"type": "<IDEOGRAPHIC>","position": 2}]
}3、Elasticsearch之中文分词器(IK分词器) 实操示例。
1)启动 centos7系统,关闭防火墙
systemctl stop firewalld
2)切换到 elsearch 用户,启动elasticsearch(如果没有此用户,创建即可,因为elasticsearch 不能在 root 用户下启动)
# 切换用户
su - elsearch# 切换到 elasticsearch 安装目录下
cd /dzs168/es/elasticsearch-6.5.4/# 启动elasticsearch
./bin/elasticsearch3)打开 Postman 工具,连接你的 elasticsearch 服务器IP,发送POST 请求
(确保你的elasticsearch 服务器,提前创建了如dzs168 索引和数据)
4、中文分词
1)中文分词的难点在于,在汉语中没有明显的词汇分界点,如在英语中,空格可以作为分隔符,如果分隔不正确就会造成歧义。
2)如:
我/爱/炒肉丝
我/爱/炒/肉丝
3)常用中文分词器,IK、jieb2、THAC等,推荐使用IK分词器。
4)IK Analyzer是一个开源的,基丁java语言开发的轻量级的中文分词工具包。从2006年12月推出1.0版开始,IKAnalyzer已经推出了3个大版本。最初,它是以开源项目Luence为应用主体的,结合词典分词和文法分析算法的中文分词组件。新版本的IKAnalyzer 3.0则发展为面向Java的公用分词组件,独立于Lucene项目,同时提
供了对Lucene的默认优化实现。
采用了特有的“正向迭代最细粒度切分算法",具有80万字/秒的高速处理能力采用了多子处理器分析模式,支持:英文字母(IP地址、Email、URL)、数字(日期,常用中文数量词,罗马数字,科学计数法),中文词汇(姓名、地名处理)等分词处理。优化的词典存储,更小的内存占用。
5、ik 分词器Elasticsearch插件下载地址:
https://github.com/medcl/elasticsearch-analysis-ik
https://github.com/infinilabs/analysis-ik
6、分词器安装方法
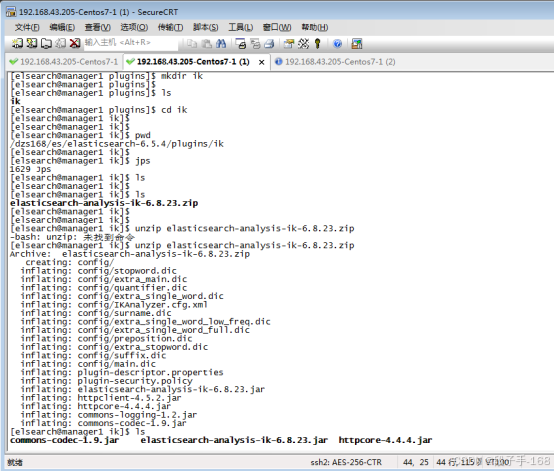
1)将下载的 elasticsearch-analysis-ik-6.8.23.zip 解压到 /elasticsearch/plugins/ik 目录下即可。
2)具体步骤
$ mkdir es/plugins/ik
$ cp elasticsearch-analysis-ik-6.5.4.zip ./es/plugins/ik# 解压
$ unzip elasticsearch-analysis-ik-6.5.4.zip# 重启
./bin/elasticsearch
7、实际操作
1)安装elasticsearch-analysis-ik 分词器
2)示例代码3
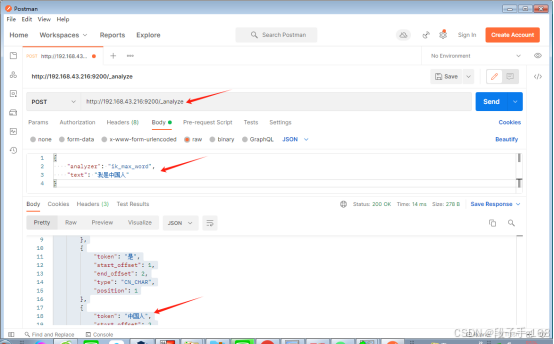
# POST http://192.168.43.216:9200/_analyze{"analyzer": "ik_max_word","text": "我是中国人"
}# 结果:
{"tokens": [{"token": "我","start_offset": 0,"end_offset": 1,"type": "CN_CHAR","position": 0},{"token": "是","start_offset": 1,"end_offset": 2,"type": "CN_CHAR","position": 1},{"token": "中国人","start_offset": 2,"end_offset": 5,"type": "CN_WORD","position": 2},{"token": "中国","start_offset": 2,"end_offset": 4,"type": "CN_WORD","position": 3},{"token": "国人","start_offset": 3,"end_offset": 5,"type": "CN_WORD","position": 4}]
}3)重启 elasticsearch 进行测试
八、Elasticsearch全文搜索之构造数据以及单词搜索
1、全文搜索
全文搜索两个最重要的方面是:
1)相关性(Relevance) :
它是评价查询与其结果间的相关程度,并根据这种相关程度对结果排名的一种能力,这
种计算方式可以是TF/IDF 方法、地理位置邻近、模糊相似,或其他的某些算法。
2)分词(Analysis)
它是将文本块转换为有区别的、规范化的token的一个过程,目的是为了创建倒排索引以及
查询倒排索引。
2、先删除Elasticsearch 原有的索引和数据
3、构造数据:创建索引 dzs168
# PUT http://192.168.43.216:9200/dzs168{"settings": {"index": {"number_of_shards": "1","number_of_replicas": "0"}},"mappings": {"person": {"properties": {"name": {"type": "text"},"age": {"type": "integer"},"mail": {"type": "keyword"},"hobby": {"type": "text","analyzer": "ik_max_word"}}}}
}# 响应结果{"acknowledged": true,"shards_acknowledged": true,"index": "dzs168"
}4、Elasticsearch 向新创建的索引 dzs168 插入数据。
# 打开 Postman 软件,选择POST请求,
# 地址栏输入:http://192.168.43.216:9200/dzs168/_bulk
# 请求体为 JSON 数据类型,请求内容为以下:{"index": { "_index": "dzs168", "_type": "person"}}
{"name": "张三", "age": 20, "mail": "111@qq.com", "hobby": "看电影、听音乐"}
{"index": { "_index": "dzs168", "_type": "person"}}
{"name": "李四", "age": 22, "mail": "222@qq.com", "hobby": "篮球、游泳"}
{"index": { "_index": "dzs168", "_type": "person"}}
{"name": "王五", "age": 25, "mail": "333@qq.com", "hobby": "散步、跑步、乒乓球"}
{"index": { "_index": "dzs168", "_type": "person"}}
{"name": "赵六", "age": 26, "mail": "444@qq.com", "hobby": "足球、篮球、听音乐"}
{"index": { "_index": "dzs168", "_type": "person"}}
{"name": "孙七", "age": 30, "mail": "555@qq.com", "hobby": "羽毛球、足球、篮球"}
{"index": { "_index": "dzs168", "_type": "person"}}
{"name": "周八", "age": 38, "mail": "666@qq.com", "hobby": "跑步、游泳、看电影"}# 响应数据
{"took": 853,"errors": false,"items": [{"index": {"_index": "dzs168","_type": "person","_id": "fTFO05UBnk-jzlVbr0SU","_version": 1,"result": "created","_shards": {"total": 1,"successful": 1,"failed": 0},"_seq_no": 0,"_primary_term": 1,"status": 201}},{"index": {"_index": "dzs168","_type": "person","_id": "fjFO05UBnk-jzlVbr0SU","_version": 1,"result": "created","_shards": {"total": 1,"successful": 1,"failed": 0},"_seq_no": 1,"_primary_term": 1,"status": 201}},{"index": {"_index": "dzs168","_type": "person","_id": "fzFO05UBnk-jzlVbr0SU","_version": 1,"result": "created","_shards": {"total": 1,"successful": 1,"failed": 0},"_seq_no": 2,"_primary_term": 1,"status": 201}},{"index": {"_index": "dzs168","_type": "person","_id": "gDFO05UBnk-jzlVbr0SU","_version": 1,"result": "created","_shards": {"total": 1,"successful": 1,"failed": 0},"_seq_no": 3,"_primary_term": 1,"status": 201}},{"index": {"_index": "dzs168","_type": "person","_id": "gTFO05UBnk-jzlVbr0SU","_version": 1,"result": "created","_shards": {"total": 1,"successful": 1,"failed": 0},"_seq_no": 4,"_primary_term": 1,"status": 201}},{"index": {"_index": "dzs168","_type": "person","_id": "gjFO05UBnk-jzlVbr0SU","_version": 1,"result": "created","_shards": {"total": 1,"successful": 1,"failed": 0},"_seq_no": 5,"_primary_term": 1,"status": 201}}]
}5、Elasticsearch 搜索查询数据:单词搜索
# 打开 Postman 软件,选择POST请求,
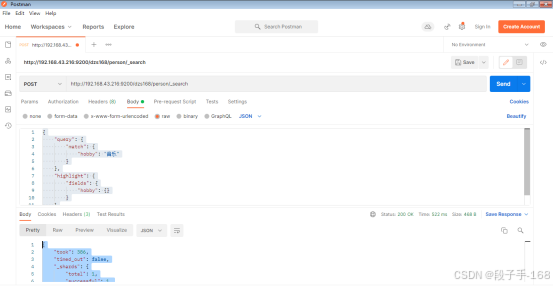
# 地址栏输入:http://192.168.43.216:9200/dzs168/person/_search
# 请求体为 JSON 数据类型,请求内容为以下:{"query": {"match": {"hobby": "音乐"}},"highlight": {"fields": {"hobby": {}}}
}# 响应数据
{"took": 386,"timed_out": false,"_shards": {"total": 1,"successful": 1,"skipped": 0,"failed": 0},"hits": {"total": 2,"max_score": 0.9686553,"hits": [{"_index": "dzs168","_type": "person","_id": "fTFO05UBnk-jzlVbr0SU","_score": 0.9686553,"_source": {"name": "张三","age": 20,"mail": "111@qq.com","hobby": "看电影、听音乐"},"highlight": {"hobby": ["看电影、听<em>音乐</em>"]}},{"_index": "dzs168","_type": "person","_id": "gDFO05UBnk-jzlVbr0SU","_score": 0.9686553,"_source": {"name": "赵六","age": 26,"mail": "444@qq.com","hobby": "足球、篮球、听音乐"},"highlight": {"hobby": ["足球、篮球、听<em>音乐</em>"]}}]}
}
6、过程说明:
1)检查字段类型
爱好 hobby 字段是一个 text 类型(指定了IK分词器),这意味着查询字符串本身也应该被分词。
2)分析查询字符串。
将查询的字符串“音乐”传入IK分词器中,输出的结果是单个项音乐。因为只有一个单词项,所以match查询执行的是单个底层term查询。
3)查找匹配文档。
用 term 查询在倒排索引中查找“音乐”然后获取一组包含该项的文档,本例的结果是文档:3、5。
4)为每个文档评分。
用term 查询计算每个文档相关度评分[score,这是种将词频( term frequency,即词“音乐"在相关文档的hobby 字段中出现的频率)和反向文档频率(inverse document frequency ,即词“音乐”在所有文档的hobby字段中出现的频率),以及字段的长度(即字段越短相关度越高)相结合的计算方式。
上一节关联链接请点击:
03_Elastic Stack 从入门到实践(三)-- 3