《Chronos: Learning the Language of Time Series》
全文摘要
本文提出了Chronos,一个简单而有效的预训练概率时间序列模型框架。Chronos通过缩放和量化将时间序列值标记化为固定词汇,并利用现有的基于变换器的语言模型架构进行训练。我们在多个公开数据集和合成数据集上预训练了Chronos模型,并在42个数据集的基准测试中显示出其在训练数据集上的显著优势,以及在新数据集上的零-shot性能。结果表明,Chronos能够有效利用多领域的时间序列数据,简化预测流程。
研究背景
-
时间序列预测的挑战
- 时间序列预测在多个领域(如零售、能源、金融、医疗等)中至关重要,传统上依赖于统计模型(如ARIMA和ETS),但随着深度学习技术的兴起,预测方法发生了变化。尽管深度学习模型在提取复杂模式方面表现出色,但它们通常需要在相同的数据集上进行训练和预测,限制了其在新数据集上的应用能力。
-
缺乏统一的通用模型
- 尽管已有一些研究致力于迁移学习和领域适应,但时间序列预测领域尚未形成一个统一的、通用的预测模型。这一目标仍然是时间序列研究者追求的方向,表明当前的模型在处理不同类型的时间序列数据时存在局限性。
-
零-shot学习的潜力
- 随着大型语言模型(LLMs)的出现,零-shot学习能力引发了对时间序列“基础模型”的兴趣。现有方法通常需要针对每个新任务进行提示工程或微调,这在计算资源和时间上都存在挑战。因此,如何有效利用预训练模型进行时间序列预测,尤其是在未见过的数据集上,成为一个重要问题。
-
数据稀缺性问题
- 公开可用的时间序列数据集在数量和质量上都相对稀缺,这使得训练通用模型变得困难。缺乏多样化和高质量的数据集限制了模型的泛化能力和鲁棒性,尤其是在面对新任务时。
-
模型架构的适应性
- 现有的时间序列预测模型通常需要特定的架构或设计来处理时间序列数据,而这可能导致模型的复杂性和训练成本增加。因此,如何在不进行大量修改的情况下,利用现有的语言模型架构来处理时间序列预测问题,是一个亟待解决的挑战。
-
简化预测管道的需求
- 当前的预测流程通常涉及为每个任务单独训练模型,这不仅耗时且资源密集。因此,开发一种能够简化预测管道的通用模型,能够在不同的时间序列任务中有效应用,显得尤为重要。
研究方法
-
时间序列标记化
- 论文提出了一种将时间序列值标记化的方法,通过缩放和量化将连续的实值数据转换为离散的标记。这一过程包括两个主要步骤:
- 缩放:对时间序列进行归一化处理,以便于后续的量化。使用均值缩放的方法,将时间序列值映射到适合量化的范围。
- 量化:将缩放后的时间序列值分配到固定数量的离散标记(或“桶”)中。通过选择桶的中心和边界,将实值数据转换为离散的标记ID,使得模型能够处理这些标记。

- 论文提出了一种将时间序列值标记化的方法,通过缩放和量化将连续的实值数据转换为离散的标记。这一过程包括两个主要步骤:
-
模型架构
- 论文采用了现有的语言模型架构,特别是基于Transformer的架构(如T5和GPT-2),并对其进行了最小的修改以适应时间序列预测任务。具体来说:
- 类别分布输出:模型使用类别分布来预测下一个标记,采用交叉熵损失函数进行训练。这种方法允许模型学习到多模态的输出分布,适应不同领域的时间序列数据。
- 论文采用了现有的语言模型架构,特别是基于Transformer的架构(如T5和GPT-2),并对其进行了最小的修改以适应时间序列预测任务。具体来说:
-
数据增强(扩充原有样本数据,增加其多样性)
- 为了提高模型的泛化能力,论文引入了两种数据增强技术:
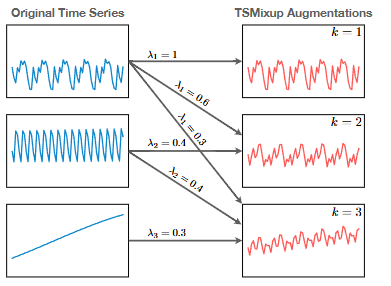
- TSMixup:通过随机组合多个时间序列生成新的时间序列,增强训练数据的多样性。这种方法通过对不同时间序列进行凸组合,帮助模型学习到更丰富的模式。

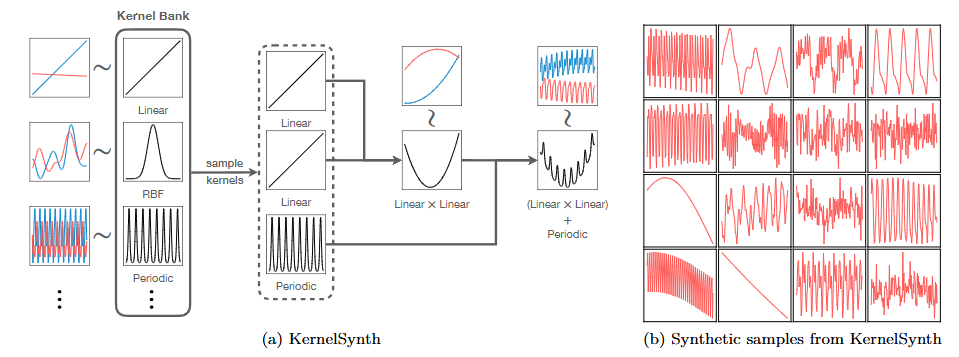
- KernelSynth:使用高斯过程生成合成时间序列,以补充真实数据的不足。通过组合不同的核函数,生成具有多样性和复杂性的合成时间序列,进一步增强训练集。
- TSMixup:通过随机组合多个时间序列生成新的时间序列,增强训练数据的多样性。这种方法通过对不同时间序列进行凸组合,帮助模型学习到更丰富的模式。
- 为了提高模型的泛化能力,论文引入了两种数据增强技术:
-
训练过程
- 论文中使用的训练过程包括:
- 交叉熵损失最小化:模型通过最小化预测分布与真实标签之间的交叉熵损失进行训练。这种方法使得模型能够在训练过程中学习到时间序列数据的潜在结构。
- 自回归采样:在预测阶段,模型通过自回归方式从预测分布中采样,生成未来的时间序列值。这种方法允许模型生成多个可能的未来路径,提供概率预测。
- 论文中使用的训练过程包括:
-
零-shot学习能力
- 论文强调了模型在未见数据集上的零-shot预测能力,表明经过预训练的模型能够在没有特定任务微调的情况下,直接应用于新的时间序列预测任务。这一特性使得Chronos模型在多种领域的时间序列预测中具有广泛的适用性。
实验结果
-
实验概述
- 论文对Chronos模型进行了全面的评估,使用了42个数据集,包括Benchmark I(15个数据集)和Benchmark II(27个数据集)。
- 实验旨在比较Chronos模型与传统统计模型、任务特定深度学习模型以及其他预训练模型的性能。
-
数据集
- 收集了55个公开可用的数据集,涵盖多个应用领域,如能源、交通、医疗、零售、网络、天气和金融。
- 数据集被分为三类:用于训练的专用数据集、用于训练和评估的Benchmark I数据集,以及仅用于评估的Benchmark II数据集。
-
训练配置
- 选择T5模型作为Chronos的主要架构,进行了不同规模(20M到710M参数)的模型训练。
- 使用了10M个TSMixup增强样本和1M个通过高斯过程生成的合成时间序列进行训练。
- 训练过程中采用了AdamW优化器,学习率从0.001线性衰减到0,训练步数为200K。
-
基线模型
- 与多种时间序列预测基线模型进行比较,包括传统的统计模型(如Naive、AutoETS、AutoARIMA等)和深度学习模型(如WaveNet、DeepAR、N-BEATS等)。
- 在Benchmark II中,还评估了零-shot方法,如ForecastPFN和LLMTime。
-
评估指标
- 使用加权分位损失(WQL)评估概率预测的质量,使用平均绝对缩放误差(MASE)评估点预测的性能。
- 采用几何平均法对模型在不同数据集上的相对得分进行汇总。
-
Benchmark I结果
- Chronos模型在Benchmark I中显著优于基线模型,尤其是较大的Chronos-T5模型(Base和Large)在聚合相对得分和平均排名上表现最佳。
- 小型Chronos模型(Mini和Small)也优于大多数基线,显示出Chronos在训练数据中的有效性。
-
Benchmark II结果
- 在Benchmark II中,Chronos模型在未见过的数据集上表现出色,显著优于传统统计模型和其他预训练模型。
- 在概率预测方面,Chronos模型获得了第2到第4名的成绩,点预测性能方面,Chronos-T5(Large)获得第2名,超越了大多数基线模型。
-
微调实验
- 对Chronos-T5(Small)模型进行了微调,结果显示微调显著提高了模型在Benchmark II上的整体性能,使其在该基准上获得了最佳成绩。
-
超参数分析
- 研究了不同模型规模、初始化方式、训练步数、合成数据比例、上下文长度和词汇大小对模型性能的影响。
- 结果表明,模型规模越大,性能越好;合成数据的适当比例(约10%)能提高模型的表现;上下文长度的增加也有助于提高预测准确性。
-
定性分析与局限性
- 对Chronos模型生成的预测进行了定性分析,发现其在识别趋势和季节性模式方面表现良好,但在处理指数趋势时存在困难。
- 论文指出了tokenization方法的局限性,特别是在处理稀疏序列和高方差数据时可能导致精度损失。