G2学习打卡
- 🍨 本文为🔗365天深度学习训练营 中的学习记录博客
- 🍖 原作者:K同学啊
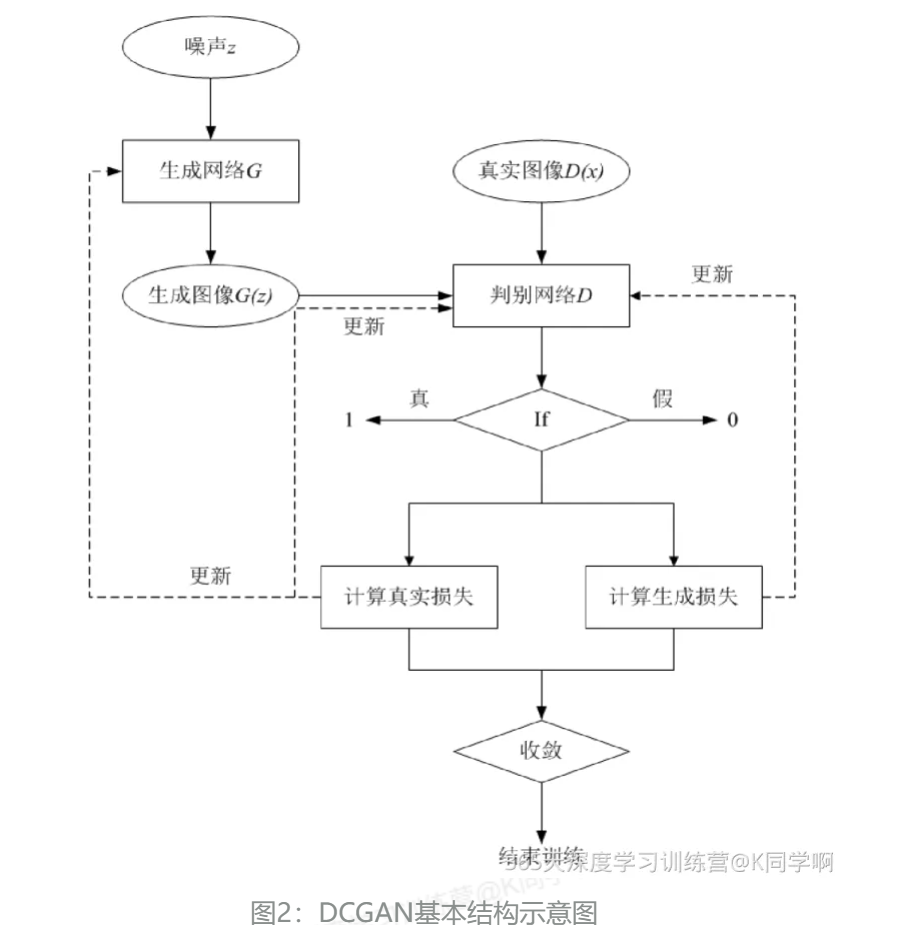
DCGAN实践
import torch, random, random, os
import torch.nn as nn
import torch.nn.parallel
import torch.optim as optim
import torch.utils.data
import torchvision.datasets as dset
import torchvision.transforms as transforms
import torchvision.utils as vutils
import numpy as np
import matplotlib.pyplot as plt
import matplotlib.animation as animation
from IPython.display import HTMLmanualSeed = 999 # 随机种子
print("Random Seed: ", manualSeed)
random.seed(manualSeed)
torch.manual_seed(manualSeed)
torch.use_deterministic_algorithms(True) # Needed for reproducible results
C:\Users\11054\.conda\envs\py311\Lib\site-packages\torch\utils\_pytree.py:185: FutureWarning: optree is installed but the version is too old to support PyTorch Dynamo in C++ pytree. C++ pytree support is disabled. Please consider upgrading optree using `python3 -m pip install --upgrade 'optree>=0.13.0'`.warnings.warn(Random Seed: 999
dataroot = r"C:\Users\11054\Desktop\kLearning\G2" # 数据路径
batch_size = 128 # 训练过程中的批次大小
image_size = 64 # 图像的尺寸(宽度和高度)
nz = 100 # z潜在向量的大小(生成器输入的尺寸)
ngf = 64 # 生成器中的特征图大小
ndf = 64 # 判别器中的特征图大小
num_epochs = 50 # 训练的总轮数,如果你显卡不太行,可调小,但是生成效果会随之降低
lr = 0.0002 # 学习率
beta1 = 0.5 # Adam优化器的Beta1超参数
# 导入数据
# 我们可以按照我们设置的方式使用图像文件夹数据集。# 创建数据集
dataset = dset.ImageFolder(root=dataroot,transform=transforms.Compose([transforms.Resize(image_size), # 调整图像大小transforms.CenterCrop(image_size), # 中心裁剪图像transforms.ToTensor(), # 将图像转换为张量transforms.Normalize((0.5, 0.5, 0.5), # 标准化图像张量(0.5, 0.5, 0.5)),]))# 创建数据加载器
dataloader = torch.utils.data.DataLoader(dataset,batch_size=batch_size, # 批量大小shuffle=True, # 是否打乱数据集num_workers=5 # 使用多个线程加载数据的工作进程数)# 选择要在哪个设备上运行代码
device = torch.device("cuda:0" if (torch.cuda.is_available()) else "cpu")
print("使用的设备是:",device)# 绘制一些训练图像
real_batch = next(iter(dataloader))
plt.figure(figsize=(8,8))
plt.axis("off")
plt.title("Training Images")
plt.imshow(np.transpose(vutils.make_grid(real_batch[0].to(device)[:24],padding=2,normalize=True).cpu(),(1,2,0)))
使用的设备是: cpu<matplotlib.image.AxesImage at 0x1757db42d90>

# 定义模型
# 自定义权重初始化函数,作用于netG和netD
def weights_init(m):# 获取当前层的类名classname = m.__class__.__name__# 如果类名中包含'Conv',即当前层是卷积层if classname.find('Conv') != -1:# 使用正态分布初始化权重数据,均值为0,标准差为0.02nn.init.normal_(m.weight.data, 0.0, 0.02)# 如果类名中包含'BatchNorm',即当前层是批归一化层elif classname.find('BatchNorm') != -1:# 使用正态分布初始化权重数据,均值为1,标准差为0.02nn.init.normal_(m.weight.data, 1.0, 0.02)# 使用常数初始化偏置项数据,值为0nn.init.constant_(m.bias.data, 0)
# 定义生成器
class Generator(nn.Module):def __init__(self):super(Generator, self).__init__()self.main = nn.Sequential(# 输入为Z,经过一个转置卷积层nn.ConvTranspose2d(nz, ngf * 8, 4, 1, 0, bias=False),nn.BatchNorm2d(ngf * 8), # 批归一化层,用于加速收敛和稳定训练过程nn.ReLU(True), # ReLU激活函数# 输出尺寸:(ngf*8) x 4 x 4nn.ConvTranspose2d(ngf * 8, ngf * 4, 4, 2, 1, bias=False),nn.BatchNorm2d(ngf * 4),nn.ReLU(True),# 输出尺寸:(ngf*4) x 8 x 8nn.ConvTranspose2d(ngf * 4, ngf * 2, 4, 2, 1, bias=False),nn.BatchNorm2d(ngf * 2),nn.ReLU(True),# 输出尺寸:(ngf*2) x 16 x 16nn.ConvTranspose2d(ngf * 2, ngf, 4, 2, 1, bias=False),nn.BatchNorm2d(ngf),nn.ReLU(True),# 输出尺寸:(ngf) x 32 x 32nn.ConvTranspose2d(ngf, 3, 4, 2, 1, bias=False),nn.Tanh() # Tanh激活函数# 输出尺寸:3 x 64 x 64)def forward(self, input):return self.main(input)
# 创建生成器
netG = Generator().to(device)
# 使用 "weights_init" 函数对所有权重进行随机初始化,
# 平均值(mean)设置为0,标准差(stdev)设置为0.02。
netG.apply(weights_init)
# 打印生成器模型
print(netG)
Generator((main): Sequential((0): ConvTranspose2d(100, 512, kernel_size=(4, 4), stride=(1, 1), bias=False)(1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(2): ReLU(inplace=True)(3): ConvTranspose2d(512, 256, kernel_size=(4, 4), stride=(2, 2), padding=(1, 1), bias=False)(4): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(5): ReLU(inplace=True)(6): ConvTranspose2d(256, 128, kernel_size=(4, 4), stride=(2, 2), padding=(1, 1), bias=False)(7): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(8): ReLU(inplace=True)(9): ConvTranspose2d(128, 64, kernel_size=(4, 4), stride=(2, 2), padding=(1, 1), bias=False)(10): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(11): ReLU(inplace=True)(12): ConvTranspose2d(64, 3, kernel_size=(4, 4), stride=(2, 2), padding=(1, 1), bias=False)(13): Tanh())
)
class Discriminator(nn.Module):def __init__(self):super(Discriminator, self).__init__()# 定义判别器的主要结构,使用Sequential容器将多个层按顺序组合在一起self.main = nn.Sequential(# 输入大小为3 x 64 x 64nn.Conv2d(3, ndf, 4, 2, 1, bias=False),nn.LeakyReLU(0.2, inplace=True),# 输出大小为(ndf) x 32 x 32nn.Conv2d(ndf, ndf * 2, 4, 2, 1, bias=False),nn.BatchNorm2d(ndf * 2),nn.LeakyReLU(0.2, inplace=True),# 输出大小为(ndf*2) x 16 x 16nn.Conv2d(ndf * 2, ndf * 4, 4, 2, 1, bias=False),nn.BatchNorm2d(ndf * 4),nn.LeakyReLU(0.2, inplace=True),# 输出大小为(ndf*4) x 8 x 8nn.Conv2d(ndf * 4, ndf * 8, 4, 2, 1, bias=False),nn.BatchNorm2d(ndf * 8),nn.LeakyReLU(0.2, inplace=True),# 输出大小为(ndf*8) x 4 x 4nn.Conv2d(ndf * 8, 1, 4, 1, 0, bias=False),nn.Sigmoid())def forward(self, input):# 将输入通过判别器的主要结构进行前向传播return self.main(input)
# 创建判别器模型
netD = Discriminator().to(device)# 应用 "weights_init" 函数来随机初始化所有权重
# 使用 mean=0, stdev=0.2 的方式进行初始化
netD.apply(weights_init)# 打印模型
print(netD)
Discriminator((main): Sequential((0): Conv2d(3, 64, kernel_size=(4, 4), stride=(2, 2), padding=(1, 1), bias=False)(1): LeakyReLU(negative_slope=0.2, inplace=True)(2): Conv2d(64, 128, kernel_size=(4, 4), stride=(2, 2), padding=(1, 1), bias=False)(3): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(4): LeakyReLU(negative_slope=0.2, inplace=True)(5): Conv2d(128, 256, kernel_size=(4, 4), stride=(2, 2), padding=(1, 1), bias=False)(6): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(7): LeakyReLU(negative_slope=0.2, inplace=True)(8): Conv2d(256, 512, kernel_size=(4, 4), stride=(2, 2), padding=(1, 1), bias=False)(9): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(10): LeakyReLU(negative_slope=0.2, inplace=True)(11): Conv2d(512, 1, kernel_size=(4, 4), stride=(1, 1), bias=False)(12): Sigmoid())
)
# 初始化“BCELoss”损失函数
criterion = nn.BCELoss()# 创建用于可视化生成器进程的潜在向量批次
fixed_noise = torch.randn(64, nz, 1, 1, device=device)real_label = 1.
fake_label = 0.# 为生成器(G)和判别器(D)设置Adam优化器
optimizerD = optim.Adam(netD.parameters(), lr=lr, betas=(beta1, 0.999))
optimizerG = optim.Adam(netG.parameters(), lr=lr, betas=(beta1, 0.999))
img_list = [] # 用于存储生成的图像列表
G_losses = [] # 用于存储生成器的损失列表
D_losses = [] # 用于存储判别器的损失列表
iters = 0 # 迭代次数print("Starting Training Loop...") # 输出训练开始的提示信息
# 对于每个epoch(训练周期)
for epoch in range(num_epochs):# 对于dataloader中的每个batchfor i, data in enumerate(dataloader, 0):############################# (1) 更新判别器网络:最大化 log(D(x)) + log(1 - D(G(z)))############################# 使用真实图像样本训练netD.zero_grad() # 清除判别器网络的梯度# 准备真实图像的数据real_cpu = data[0].to(device)b_size = real_cpu.size(0)label = torch.full((b_size,), real_label, dtype=torch.float, device=device) # 创建一个全是真实标签的张量# 将真实图像样本输入判别器,进行前向传播output = netD(real_cpu).view(-1)# 计算真实图像样本的损失errD_real = criterion(output, label)# 通过反向传播计算判别器的梯度errD_real.backward()D_x = output.mean().item() # 计算判别器对真实图像样本的输出的平均值## 使用生成图像样本训练# 生成一批潜在向量noise = torch.randn(b_size, nz, 1, 1, device=device)# 使用生成器生成一批假图像样本fake = netG(noise)label.fill_(fake_label) # 创建一个全是假标签的张量# 将所有生成的图像样本输入判别器,进行前向传播output = netD(fake.detach()).view(-1)# 计算判别器对生成图像样本的损失errD_fake = criterion(output, label)# 通过反向传播计算判别器的梯度errD_fake.backward()D_G_z1 = output.mean().item() # 计算判别器对生成图像样本的输出的平均值# 计算判别器的总损失,包括真实图像样本和生成图像样本的损失之和errD = errD_real + errD_fake# 更新判别器的参数optimizerD.step()############################# (2) 更新生成器网络:最大化 log(D(G(z)))###########################netG.zero_grad() # 清除生成器网络的梯度label.fill_(real_label) # 对于生成器成本而言,将假标签视为真实标签# 由于刚刚更新了判别器,再次将所有生成的图像样本输入判别器,进行前向传播output = netD(fake).view(-1)# 根据判别器的输出计算生成器的损失errG = criterion(output, label)# 通过反向传播计算生成器的梯度errG.backward()D_G_z2 = output.mean().item() # 计算判别器对生成器输出的平均值# 更新生成器的参数optimizerG.step()# 输出训练统计信息if i % 400 == 0:print('[%d/%d][%d/%d]\tLoss_D: %.4f\tLoss_G: %.4f\tD(x): %.4f\tD(G(z)): %.4f / %.4f'% (epoch, num_epochs, i, len(dataloader),errD.item(), errG.item(), D_x, D_G_z1, D_G_z2))# 保存损失值以便后续绘图G_losses.append(errG.item())D_losses.append(errD.item())# 通过保存生成器在固定噪声上的输出来检查生成器的性能if (iters % 500 == 0) or ((epoch == num_epochs-1) and (i == len(dataloader)-1)):with torch.no_grad():fake = netG(fixed_noise).detach().cpu()img_list.append(vutils.make_grid(fake, padding=2, normalize=True))iters += 1
Starting Training Loop...
[0/50][0/36] Loss_D: 1.7236 Loss_G: 5.1259 D(x): 0.5475 D(G(z)): 0.5840 / 0.0090
[1/50][0/36] Loss_D: 0.1412 Loss_G: 10.1056 D(x): 0.9568 D(G(z)): 0.0001 / 0.0002
[2/50][0/36] Loss_D: 0.0375 Loss_G: 6.2139 D(x): 0.9899 D(G(z)): 0.0230 / 0.0089
[3/50][0/36] Loss_D: 1.0469 Loss_G: 4.9860 D(x): 0.5501 D(G(z)): 0.0018 / 0.0176
[4/50][0/36] Loss_D: 0.2032 Loss_G: 2.6827 D(x): 0.9036 D(G(z)): 0.0498 / 0.1420
[5/50][0/36] Loss_D: 1.3498 Loss_G: 10.0099 D(x): 0.9797 D(G(z)): 0.5853 / 0.0006
[6/50][0/36] Loss_D: 2.4096 Loss_G: 11.6630 D(x): 0.9826 D(G(z)): 0.7797 / 0.0002
[7/50][0/36] Loss_D: 0.3752 Loss_G: 4.3695 D(x): 0.8566 D(G(z)): 0.1551 / 0.0239
[8/50][0/36] Loss_D: 1.0071 Loss_G: 1.9715 D(x): 0.5102 D(G(z)): 0.0207 / 0.2292
[9/50][0/36] Loss_D: 0.3776 Loss_G: 3.8670 D(x): 0.8157 D(G(z)): 0.1036 / 0.0359
[10/50][0/36] Loss_D: 0.4627 Loss_G: 3.9416 D(x): 0.8264 D(G(z)): 0.1705 / 0.0345
[11/50][0/36] Loss_D: 1.1795 Loss_G: 8.4380 D(x): 0.9700 D(G(z)): 0.5774 / 0.0025
[12/50][0/36] Loss_D: 0.2164 Loss_G: 5.4980 D(x): 0.9282 D(G(z)): 0.1098 / 0.0075
[13/50][0/36] Loss_D: 0.6452 Loss_G: 6.5228 D(x): 0.8989 D(G(z)): 0.3764 / 0.0037
[14/50][0/36] Loss_D: 1.1625 Loss_G: 7.6080 D(x): 0.4868 D(G(z)): 0.0019 / 0.0023
[15/50][0/36] Loss_D: 0.6295 Loss_G: 4.1495 D(x): 0.6188 D(G(z)): 0.0147 / 0.0257
[16/50][0/36] Loss_D: 1.0627 Loss_G: 6.4099 D(x): 0.8808 D(G(z)): 0.4819 / 0.0059
[17/50][0/36] Loss_D: 0.6702 Loss_G: 4.0104 D(x): 0.6348 D(G(z)): 0.0207 / 0.0455
[18/50][0/36] Loss_D: 1.0098 Loss_G: 7.5789 D(x): 0.9567 D(G(z)): 0.5313 / 0.0018
[19/50][0/36] Loss_D: 0.6029 Loss_G: 2.4873 D(x): 0.7416 D(G(z)): 0.1687 / 0.1520
[20/50][0/36] Loss_D: 0.3798 Loss_G: 4.0444 D(x): 0.7889 D(G(z)): 0.0474 / 0.0355
[21/50][0/36] Loss_D: 0.7082 Loss_G: 6.9110 D(x): 0.8789 D(G(z)): 0.3441 / 0.0025
[22/50][0/36] Loss_D: 0.4981 Loss_G: 5.1128 D(x): 0.8326 D(G(z)): 0.1891 / 0.0123
[23/50][0/36] Loss_D: 0.4518 Loss_G: 3.5331 D(x): 0.7792 D(G(z)): 0.0679 / 0.0564
[24/50][0/36] Loss_D: 0.5193 Loss_G: 3.3536 D(x): 0.7036 D(G(z)): 0.0441 / 0.0670
[25/50][0/36] Loss_D: 0.5017 Loss_G: 3.7515 D(x): 0.6931 D(G(z)): 0.0274 / 0.0506
[26/50][0/36] Loss_D: 0.4616 Loss_G: 5.0216 D(x): 0.8667 D(G(z)): 0.2204 / 0.0140
[27/50][0/36] Loss_D: 1.1406 Loss_G: 6.8489 D(x): 0.9879 D(G(z)): 0.5421 / 0.0040
[28/50][0/36] Loss_D: 0.5495 Loss_G: 6.8649 D(x): 0.9209 D(G(z)): 0.3064 / 0.0030
[29/50][0/36] Loss_D: 0.3342 Loss_G: 3.6146 D(x): 0.8250 D(G(z)): 0.0753 / 0.0584
[30/50][0/36] Loss_D: 0.5480 Loss_G: 4.6875 D(x): 0.8961 D(G(z)): 0.3022 / 0.0158
[31/50][0/36] Loss_D: 0.3652 Loss_G: 3.6861 D(x): 0.8322 D(G(z)): 0.1099 / 0.0475
[32/50][0/36] Loss_D: 0.4753 Loss_G: 6.9197 D(x): 0.9454 D(G(z)): 0.3003 / 0.0018
[33/50][0/36] Loss_D: 0.4624 Loss_G: 3.9544 D(x): 0.8472 D(G(z)): 0.1989 / 0.0327
[34/50][0/36] Loss_D: 0.4181 Loss_G: 4.3179 D(x): 0.8729 D(G(z)): 0.2079 / 0.0220
[35/50][0/36] Loss_D: 0.4715 Loss_G: 6.9001 D(x): 0.9167 D(G(z)): 0.2626 / 0.0028
[36/50][0/36] Loss_D: 0.5345 Loss_G: 3.7951 D(x): 0.6720 D(G(z)): 0.0171 / 0.0596
[37/50][0/36] Loss_D: 0.5962 Loss_G: 5.9941 D(x): 0.9250 D(G(z)): 0.3503 / 0.0054
[38/50][0/36] Loss_D: 0.7117 Loss_G: 5.8364 D(x): 0.8362 D(G(z)): 0.3505 / 0.0063
[39/50][0/36] Loss_D: 0.4237 Loss_G: 3.2940 D(x): 0.7762 D(G(z)): 0.1087 / 0.0614
[40/50][0/36] Loss_D: 0.6665 Loss_G: 2.0936 D(x): 0.7199 D(G(z)): 0.1950 / 0.1817
[41/50][0/36] Loss_D: 0.3606 Loss_G: 5.0105 D(x): 0.9024 D(G(z)): 0.1763 / 0.0175
[42/50][0/36] Loss_D: 0.3204 Loss_G: 4.0670 D(x): 0.9156 D(G(z)): 0.1733 / 0.0292
[43/50][0/36] Loss_D: 0.3777 Loss_G: 4.1411 D(x): 0.8361 D(G(z)): 0.1222 / 0.0314
[44/50][0/36] Loss_D: 0.5570 Loss_G: 4.7399 D(x): 0.9317 D(G(z)): 0.3253 / 0.0196
[45/50][0/36] Loss_D: 0.2781 Loss_G: 4.1938 D(x): 0.8437 D(G(z)): 0.0771 / 0.0286
[46/50][0/36] Loss_D: 1.0330 Loss_G: 1.0081 D(x): 0.4644 D(G(z)): 0.0088 / 0.4986
[47/50][0/36] Loss_D: 0.2690 Loss_G: 3.8095 D(x): 0.8519 D(G(z)): 0.0781 / 0.0372
[48/50][0/36] Loss_D: 1.0179 Loss_G: 6.1155 D(x): 0.8852 D(G(z)): 0.4888 / 0.0051
[49/50][0/36] Loss_D: 0.4337 Loss_G: 5.1828 D(x): 0.9389 D(G(z)): 0.2735 / 0.0103
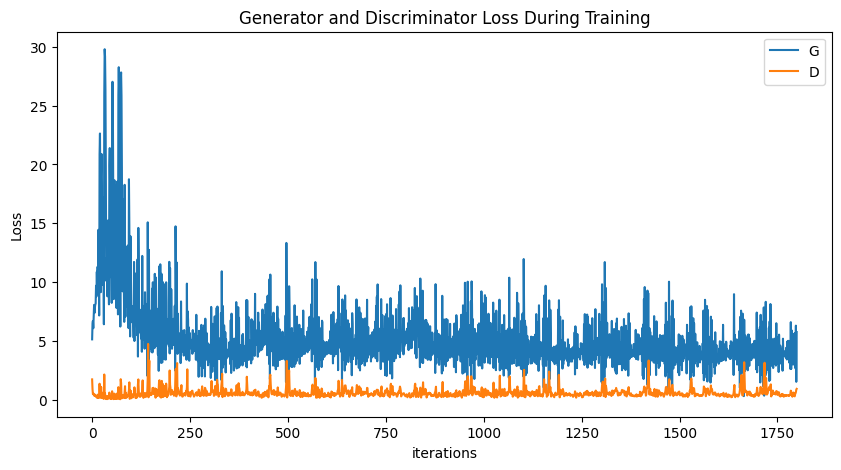
plt.figure(figsize=(10,5))
plt.title("Generator and Discriminator Loss During Training")
plt.plot(G_losses,label="G")
plt.plot(D_losses,label="D")
plt.xlabel("iterations")
plt.ylabel("Loss")
plt.legend()
plt.show()
# 创建一个大小为8x8的图形对象
fig = plt.figure(figsize=(8, 8))# 不显示坐标轴
plt.axis("off")# 将图像列表img_list中的图像转置并创建一个包含每个图像的单个列表ims
ims = [[plt.imshow(np.transpose(i, (1, 2, 0)), animated=True)] for i in img_list]# 使用图形对象、图像列表ims以及其他参数创建一个动画对象ani
ani = animation.ArtistAnimation(fig, ims, interval=1000, repeat_delay=1000, blit=True)# 将动画以HTML形式呈现
HTML(ani.to_jshtml())
/* set a timeout to make sure all the above elements are created beforethe object is initialized. */
setTimeout(function() {anim62af5ba9173646d290425ff25406c403 = new Animation(frames, img_id, slider_id, 1000.0,loop_select_id);
}, 0);
})()

# 从数据加载器中获取一批真实图像
real_batch = next(iter(dataloader))# 绘制真实图像
plt.figure(figsize=(15,15))
plt.subplot(1,2,1)
plt.axis("off")
plt.title("Real Images")
plt.imshow(np.transpose(vutils.make_grid(real_batch[0].to(device)[:64], padding=5, normalize=True).cpu(),(1,2,0)))# 绘制上一个时期生成的假图像
plt.subplot(1,2,2)
plt.axis("off")
plt.title("Fake Images")
plt.imshow(np.transpose(img_list[-1],(1,2,0)))
plt.show()

个人总结
DCGAN(Deep Convolutional Generative Adversarial Network)是生成对抗网络(GAN)的一种改进架构,专门用于图像生成任务。它通过引入卷积神经网络(CNN)来替代传统GAN中的全连接网络,显著提高了生成图像的质量。
核心思想
生成器(Generator):将随机噪声向量转换为逼真图像
判别器(Discriminator):区分真实图像和生成器生成的假图像
两者通过对抗训练共同提升,最终目标是生成器能产生以假乱真的图像
二、DCGAN架构特点
- 生成器架构
-
输入:100维的随机噪声向量(通常服从均匀分布或正态分布)
-
结构:
全连接层将噪声向量映射到初始特征图
一系列转置卷积层(Transposed Convolution)逐步上采样
最终输出64×64或128×128的RGB图像 -
关键技术:
使用ReLU激活(输出层用Tanh)
批归一化(Batch Normalization)
不使用池化层,完全依靠转置卷积进行上采样
- 判别器架构
-
输入:真实图像或生成图像
-
结构:
一系列卷积层逐步下采样,最终通过全连接层输出一个概率值(真/假) -
关键技术:
使用LeakyReLU激活
批归一化(除输入层外)
不使用池化层,依靠带步长的卷积进行下采样