Cython中操作C++字符串
使用Cython开发Python扩展模块-CSDN博客中文末对python代码做了部分C++优化,并提及未对字符串类型做优化,并且提到如果不是真正搞懂了C++字符串的操作和Python的C API中与字符串相关的知识,最好不要动Python中的字符串类型。为了搞明白在Cython中如何进行C++字符串操作,恶补了一番std::string的相关知识,同时,在各大AI(助力最大的是Cursor)的指点下,总算有所收获,为了早日忘却,特记录如下。
还是用昨天的中文数字与阿拉伯数字相互转换的程序为例,先看改造后的代码:
# num_cvt.pyx
# cython: language_level=3
# cython: boundscheck=False
# cython: wraparound=False
# cython: nonecheck=False
# cython: cdivision=Truefrom libc.stdint cimport int64_t
from libcpp.map cimport map
from libcpp.pair cimport pair
from libcpp.vector cimport vector
from libc.stddef cimport size_t
from cpython.unicode cimport PyUnicode_AsUTF8String, PyUnicode_Decodecdef extern from "<string>" namespace "std":cdef cppclass string:string() except + # 默认构造函数string(const char*) except + # C 字符串构造函数string(const char*, size_t) except + # 带长度的构造函数string(const string&) except + # 拷贝构造函数# 声明我们需要使用的 string 方法size_t find(const string&, size_t) conststring& replace(size_t, size_t, const string&)string& erase(size_t, size_t)size_t length() conststring substr(size_t, size_t) constconst char* c_str()bint empty() conststring& append(const string&) # 替代 +=string& append(const char*) # 替代 +=# 添加运算符声明string operator+(const string&) const # 字符串连接运算符bint operator==(const string&) const # 字符串相等运算符bint operator!=(const string&) const # 字符串不相等运算符char operator[](size_t) const # 索引运算符# 声明 npos 常量
cdef extern from "<string>" namespace "std::string":size_t nposcdef extern from "<string>" namespace "std":string to_string(int64_t val) # 数字按字面值转 C++ 字符串, 直接用 C++ 库函数cdef class NumberCvt:# 声明 C++ 成员变量cdef map[string, int] cn2an_nums # 中文到数字的映射cdef map[int, string] an2cn_nums # 数字到中文的映射cdef map[string, int64_t] cn2an_units # 中文单位到数字的映射cdef vector[string] cn_units # 中文单位列表def __cinit__(self):# 初始化数字映射cdef dict num_init = {"零": 0, "〇": 0, "一": 1, "二": 2, "三": 3,"四": 4, "五": 5, "六": 6, "七": 7, "八": 8, "九": 9}# 初始化 cn2an_numsfor cn_char, value in num_init.items():self.cn2an_nums[self._to_cpp_str(cn_char)] = value# 初始化 an2cn_nums(不包含〇字)for num in range(10):for cn_char, val in num_init.items():if val == num and cn_char != "〇":self.an2cn_nums[num] = self._to_cpp_str(cn_char)break# 初始化单位映射cdef dict unit_init = {"十": 10,"百": 100,"千": 1000,"万": 10000,"亿": 100000000,"兆": 1000000000000}# 初始化 cn2an_unitsfor unit_char, value in unit_init.items():self.cn2an_units[self._to_cpp_str(unit_char)] = value# 初始化 cn_unitscdef list units = ["", "十", "百", "千", "万", "十", "百", "千","亿", "十", "百", "千", "兆", "十", "百", "千"]for unit in units:self.cn_units.push_back(self._to_cpp_str(unit))cdef object _to_py_str(self, string cpp_str) except *:"""将 C++ 字符串转换为 Python 字符串""" cdef object py_str = PyUnicode_Decode(cpp_str.c_str(), # 输入的 C++ 字符串len(cpp_str), # 字符串长度"utf-8", # 编码方式"replace" # 错误处理方式) return py_strcdef string _to_cpp_str(self, str py_str) except *:"""将 Python 字符串转换为 C++ 字符串"""cdef bytes py_bytes = PyUnicode_AsUTF8String(py_str)cdef string result = string(<const char*>py_bytes, len(py_bytes))return resultcpdef str an2cn(self, int64_t arabic_num):cdef string arabic_str = to_string(arabic_num)cdef size_t num_len = arabic_str.length()if num_len > self.cn_units.size():raise ValueError(f"超出数据范围,最长支持 {self.cn_units.size()} 位")cdef string output_cncdef int i, dcdef char digitcdef size_t unit_indexcdef string last_charfor i in range(num_len):digit = arabic_str[i]d = ord(digit) - ord('0') # 将数字字符转换为数字字面量# 计算当前数字的单位索引,从位数即可查到对应单位,例如第二位,就是“十”,第三位,就是“百”,以此类推unit_index = num_len - i - 1 if d: # 如果当前数字不是0,则直接添加数字和单位output_cn += self.an2cn_nums[d] + self.cn_units[unit_index]else: # 如果当前数字是0,则需要特殊处理if unit_index % 4 == 0: # 如果当前单位是万、亿、兆output_cn.append(self._to_cpp_str("零") + self.cn_units[unit_index])elif i > 0 and output_cn.length() > 0: # 如果当前数字是0,且不是第一个数字,则添加“零”last_char = output_cn.substr(output_cn.length() - 3, 3) # 获取最后一个中文字符if last_char != self._to_cpp_str("零"):output_cn.append(self._to_cpp_str("零"))# 处理多余的零和两个万级单位之间全是零等特殊情况cdef string result = self._process_special_cases(output_cn)return self._to_py_str(result)cdef string _process_special_cases(self, string input_str):"""处理特殊情况的替换,模拟 Python 的 replace 方法"""cdef string result = input_strcdef map[string, string] replacements# 初始化替换规则(使用3字节UTF-8编码的中文字符串)replacements[self._to_cpp_str("零零")] = self._to_cpp_str("零")replacements[self._to_cpp_str("零万")] = self._to_cpp_str("万")replacements[self._to_cpp_str("零亿")] = self._to_cpp_str("亿")replacements[self._to_cpp_str("亿万")] = self._to_cpp_str("亿")replacements[self._to_cpp_str("零兆")] = self._to_cpp_str("兆")replacements[self._to_cpp_str("兆亿")] = self._to_cpp_str("兆")replacements[self._to_cpp_str("兆万")] = self._to_cpp_str("兆")# 应用替换规则cdef size_t poscdef pair[string, string] replacement_pairfor replacement_pair in replacements:pos = 0while True:pos = result.find(replacement_pair.first, pos)if pos == npos:breakresult.replace(pos, replacement_pair.first.length(), replacement_pair.second)pos += replacement_pair.second.length()# 处理首尾的零cdef string zero = self._to_cpp_str("零")while result.length() >= 3 and result.substr(0, 3) == zero:result.erase(0, 3)while result.length() >= 3 and result.substr(result.length() - 3, 3) == zero:result.erase(result.length() - 3, 3)# 处理"一十"开头的情况cdef string yi_shi = self._to_cpp_str("一十")cdef string shi = self._to_cpp_str("十")if result.length() >= 6 and result.substr(0, 6) == yi_shi: # "一十"是6个字节result = shi + result.substr(6, npos)return resultcpdef int64_t cn2an(self, str cn_nums):cdef int64_t result = 0cdef int64_t unit = 1cdef int64_t num = 0cdef int64_t tmp = 0cdef string cpp_cn_nums = self._to_cpp_str(cn_nums)cdef size_t i = 0cdef string curr_charcdef string start_char# 处理十、十几的情况if cpp_cn_nums.length() == 0:raise ValueError(f"没有给出数字。")start_char = cpp_cn_nums.substr(0, 3)if start_char == self._to_cpp_str("十"):if cpp_cn_nums.length() == 3:return 10else:start_char = cpp_cn_nums.substr(3, npos)if self.cn2an_nums.find(start_char) != self.cn2an_nums.end(): # 十 + 数字return 10 + self.cn2an_nums[start_char]elif self.cn2an_units.find(start_char) != self.cn2an_units.end(): # 十 + 单位return 10 * self.cn2an_units[start_char]else:try:curr_char_str = self._to_py_str(start_char)except UnicodeDecodeError:curr_char_str = f"字节值:{curr_char[0]:02x}{curr_char[1]:02x}{curr_char[2]:02x}"raise ValueError(f"'{cn_nums}' 中包含非法字符 '{curr_char_str}'")# 处理其他情况,从第一个字符开始,逐个字符处理while i < cpp_cn_nums.length():# 获取一个完整的UTF-8中文字符(3字节)curr_char = cpp_cn_nums.substr(i, 3)# 处理数字if self.cn2an_nums.find(curr_char) != self.cn2an_nums.end():num = self.cn2an_nums[curr_char] # 记录数字# 处理单位elif self.cn2an_units.find(curr_char) != self.cn2an_units.end():unit = self.cn2an_units[curr_char] # 记录单位if unit % 10000: # 单位不是万、亿、兆num *= unit # 将万以内数值累加到临时结果中tmp += num num = 0 else: # 单位是万、亿、兆 result += (tmp + num) * unit # 临时结果乘上单位暂时保存,注意加上最后读到的数字tmp = 0 # 重置临时变量else: # 字符既不在数字列表又不在单位列表中,则是非法字符try:curr_char_str = self._to_py_str(curr_char)except UnicodeDecodeError:curr_char_str = f"字节值:{curr_char[0]:02x}{curr_char[1]:02x}{curr_char[2]:02x}"raise ValueError(f"'{cn_nums}' 中包含非法字符 '{curr_char_str}'")i += 3 # 移动到下一个中文字符return result + tmp + num # 返回最终结果,注意加上万以内的数字下面是对代码的总结:
1、所有用到C++标准库中std::string类型的操作,用到的方法要全部通过cimport导入。一开始因为不知道这一点,明明string可以==,也可以[]取字符,但就是不能通过编译,让我十分疑惑,豆包kimi、copilot一开始都没有提到这一点,直到cursor指出这点,才总算可以继续学习下去了。
2、C++的string转换成Python的str,似乎是简单的事,结果各大AI都没搞出可用的方法,网上也没有找到可行的方法,最后是综合编译器的报错和各大AI给的示例与错误分析,总算猜到了正确的方法:
cdef object _to_py_str(self, string cpp_str) except *:
"""将 C++ 字符串转换为 Python 字符串"""
cdef object py_str = PyUnicode_Decode(cpp_str.c_str(), # 输入的 C++ 字符串
len(cpp_str), # 字符串长度
"utf-8", # 编码方式
"replace" # 错误处理方式
)
return py_str
3、将Python的str转换为C++的string,各大AI也绕了很多弯子。给出的代码倒都是正确的,但是编译总是出错,问了很久没有一个AI解决了编译错误,最后我问cursor是不是要导入string的构造方法,cursor恍然大悟说您说的对。下面的代码请记住要导入string的构造函数:
cdef string _to_cpp_str(self, str py_str) except *:
"""将 Python 字符串转换为 C++ 字符串"""
cdef bytes py_bytes = PyUnicode_AsUTF8String(py_str)
cdef string result = string(<const char*>py_bytes, len(py_bytes))
return result
4、int64_t转换为string,其实不需要自己编C++代码,直接导入string to_string(int64_t val)方法即可。需要注意的是,参数数据类型不同的重载方法,只要用到的都要导入。例如,如果还要将int转换为string,就还要导入string to_string(int val)。所以,通过cimport导入方法和类算是Cython编码的一个重要步骤。这个程序光是导入就用了三十多行:
from libc.stdint cimport int64_t
from libcpp.map cimport map
from libcpp.pair cimport pair
from libcpp.vector cimport vector
from libc.stddef cimport size_t
from cpython.unicode cimport PyUnicode_AsUTF8String, PyUnicode_Decode
cdef extern from "<string>" namespace "std":
cdef cppclass string:
string() except + # 默认构造函数
string(const char*) except + # C 字符串构造函数
string(const char*, size_t) except + # 带长度的构造函数
string(const string&) except + # 拷贝构造函数
# 声明我们需要使用的 string 方法
size_t find(const string&, size_t) const
string& replace(size_t, size_t, const string&)
string& erase(size_t, size_t)
size_t length() const
string substr(size_t, size_t) const
const char* c_str()
bint empty() const
string& append(const string&) # 替代 +=
string& append(const char*) # 替代 +=
# 添加运算符声明
string operator+(const string&) const # 字符串连接运算符
bint operator==(const string&) const # 字符串相等运算符
bint operator!=(const string&) const # 字符串不相等运算符
char operator[](size_t) const # 索引运算符
# 声明 npos 常量
cdef extern from "<string>" namespace "std::string":
size_t npos
cdef extern from "<string>" namespace "std":
string to_string(int64_t val) # 数字按字面值转 C++ 字符串, 直接用 C++ 库函数
5、这次我用了另一种算法来实现中文数字转换为阿拉伯数字,不倒转原始字符串,直接从最高位开始读,似乎跟人读数字的方式更相似,也更自然。UTF-8字节字符串的遍历方式也很奇葩的,不能将索引每次前进1,要前进3,因为每个UTF-8字符占3字节:
while i < cpp_cn_nums.length():
# 获取一个完整的UTF-8中文字符(3字节)
curr_char = cpp_cn_nums.substr(i, 3)
# 省略部分代码
i += 3 # 移动到下一个UTF-8字符,这里是中文
6、std::string具体的方法和属性,可以查文档,这里就不搬运文档了。构建脚本及方法请参阅本文开头提到的博文,完全可以通用,这里就不粘贴了。
7、经过改造,Cython输出的编译注释中黄色底纹已经很少了,而且大多集中在函数定义和异常处理方面:

8、然并卵,改造后程序运行效率还不如没改造字符串类型的版本,比用没改造的原始Python代码构建的框架快不了多少:
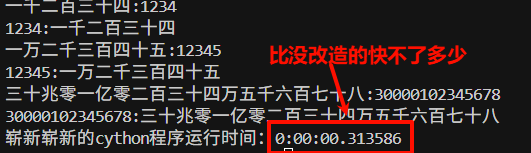
可见如果不是频繁进行字符串读写复制,真的没必要修改str数据类型,增加的麻烦太多而取得的效益太少。