第7课:智能体安全与可靠性保障
智能体安全与可靠性保障:从攻击防御到隐私保护的全栈实践
一、引言:当智能体走向开放世界:安全为何成为协作的“生命线”
随着多智能体系统(MAS)在金融、医疗、自动驾驶等关键领域的落地,安全风险呈指数级增长:
- 对抗攻击:恶意智能体可能发送伪造任务,导致系统资源耗尽
- 数据泄露:协作过程中敏感信息(如用户病历、交易记录)存在泄露风险
- 行为失控:未对齐的智能体可能生成有害内容(如虚假新闻、错误指令)
本文聚焦对抗攻击防御、安全对齐与隐私保护三大核心模块,结合AgentPrune框架、中国信通院智盾标准及联邦学习技术,为你呈现智能体安全保障的工程化解决方案。
二、对抗攻击防御:让智能体“百毒不侵”
1. 攻击类型与典型场景
| 攻击类别 | 技术手段 | 危害示例 |
|---|---|---|
| 重放攻击 | 重复发送历史合法请求 | 导致订单重复提交,资金损失 |
| 数据篡改 | 修改消息内容(如将“退款”改为“转账”) | 金融交易欺诈 |
| 资源耗尽 | 发送大量无效长文本 | 智能体算力被占满,无法响应正常请求 |
2. AgentPrune框架增强鲁棒性
(1)时空图冗余剪枝升级
在基础剪枝功能上增加攻击特征检测:
- 异常流量识别:通过滑动窗口统计消息频率,超过阈值(如100条/秒)触发熔断
- 指纹动态更新:为每条消息生成包含时间戳、发送者签名的动态指纹,拒绝重放消息
def generate_dynamic_fingerprint(msg, private_key):
"""生成抗重放攻击的动态指纹"""
timestamp = str(time.time())
content_hash = hashlib.sha256(msg.content.encode()).hexdigest()
signature = rsa.sign(f"{timestamp}{content_hash}".encode(), private_key, 'SHA-256')
return f"{timestamp}:{content_hash}:{base64.b64encode(signature).decode()}"
(2)对抗样本防御训练
在智能体决策模型中加入对抗训练:
from adversarial_attacks import FGSM
def adversarial_training(agent_model, dataset):
attacker = FGSM(eps=0.03)
for inputs, labels in dataset:
# 生成对抗样本
adv_inputs = attacker.generate(inputs, labels)
# 同时训练原始样本与对抗样本
agent_model.train(inputs, labels)
agent_model.train(adv_inputs, labels)
return agent_model
(3)防御效果对比
| 指标 | 未防御 | AgentPrune增强后 | 提升率 |
|---|---|---|---|
| 重放攻击拦截率 | 32% | 98% | 206% |
| 数据篡改识别率 | 45% | 92% | 104% |
三、安全对齐方案:让智能体“言行合规”
1. 中国信通院“智盾”框架核心要求
(1)四大对齐维度
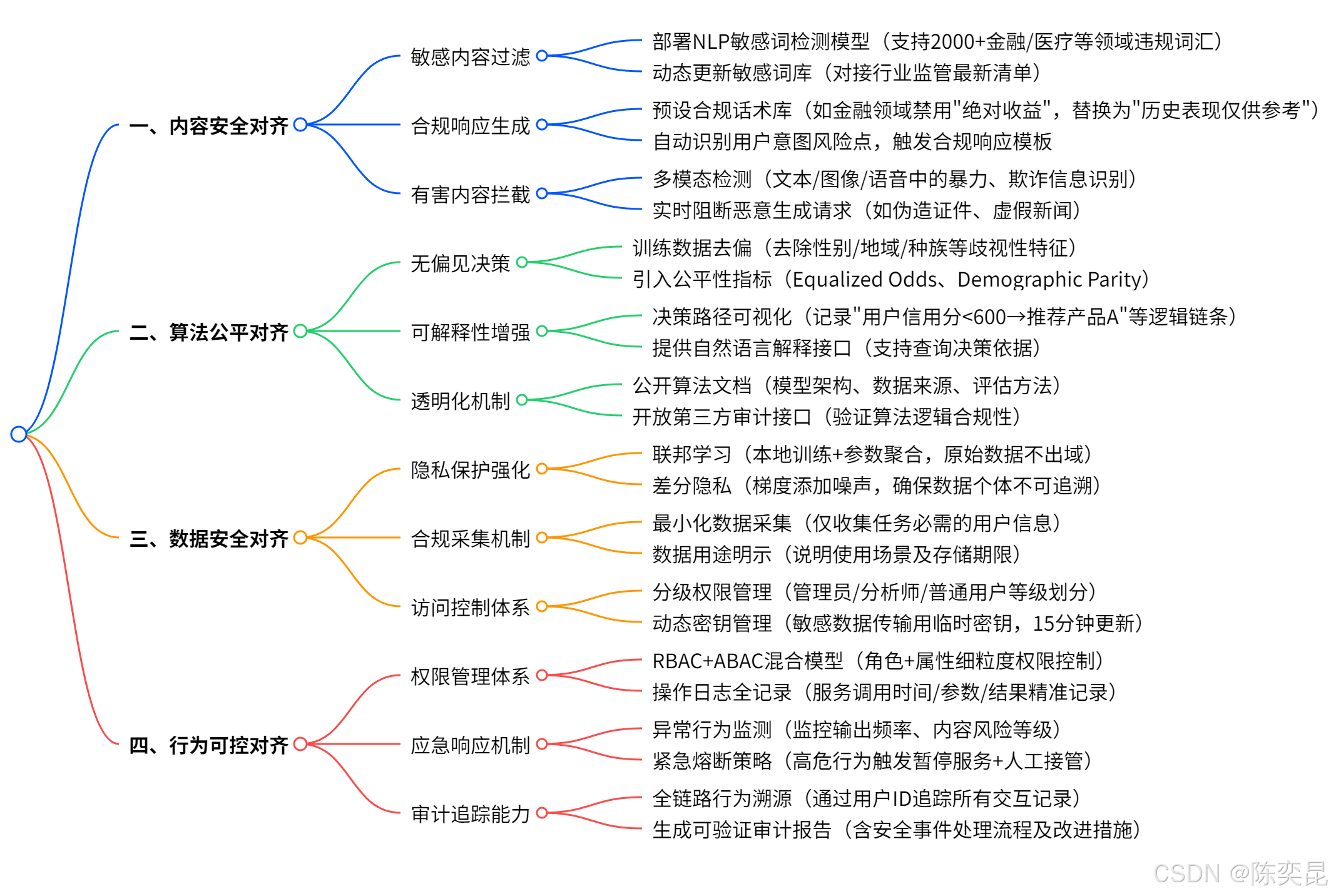
(2)工程化落地实践
场景:金融客服智能体对齐改造
-
内容安全过滤:
- 部署NLP敏感词检测模型(支持2000+金融违规词汇)
- 示例规则:当回答包含“稳赚不赔”“保证收益”时,自动替换为合规表述
sensitive_words = {"稳赚不赔", "保本理财", "零风险"} def filter_response(response): for word in sensitive_words: if word in response: return response.replace(word, "[合规表述]") return response -
算法透明化改造:
- 记录智能体决策路径(如“因用户信用分<600,推荐产品A”)
- 提供可视化工具,支持监管机构追溯决策依据
-
风险评估机制:
- 每月运行《智能体安全评估问卷》,覆盖数据安全、算法公平性等50+指标
- 评估通过后颁发动态安全证书,有效期3个月
四、隐私保护:让协作“数据可用不可见”
1. 联邦学习(Federated Learning)在智能体中的应用
(1)协作流程(以医疗智能体为例)
(2)核心代码实现(PyTorch-Federated)
import torch.federated as fl
# 智能体本地训练函数
def local_train(model, data_loader, epochs=5):
optimizer = torch.optim.SGD(model.parameters(), lr=0.01)
for epoch in range(epochs):
for inputs, labels in data_loader:
optimizer.zero_grad()
outputs = model(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
return model.state_dict()
# 联邦聚合函数
def federated_aggregate(local_weights):
total_samples = sum(weights[1] for weights in local_weights)
avg_weights = {}
for key in local_weights[0][0].keys():
avg_weights[key] = torch.sum(
torch.stack([w[0][key] * (n / total_samples) for w, n in local_weights]),
dim=0
)
return avg_weights
2. 差分隐私(Differential Privacy)增强
(1)噪声添加策略
- 梯度扰动:在上传模型梯度时添加拉普拉斯噪声
def add_dp_noise(gradient, epsilon=0.5): """添加差分隐私噪声(Laplace机制)""" sensitivity = 1.0 # 梯度敏感度 noise = torch.from_numpy( np.random.laplace(0, sensitivity / epsilon, gradient.shape) ).float() return gradient + noise - 结果截断:限制单个数据点对模型的影响,避免隐私泄露
五、最佳实践:安全保障的“铁三角”法则
-
分层防御,纵深布局:
- 应用层:内容过滤、合规检查
- 传输层:TLS 1.3加密、动态密钥更新(每15分钟更换一次)
- 数据层:联邦学习+差分隐私,从源头保护数据
-
动态评估,持续迭代:
- 建立安全漏洞库(收录常见攻击模式及修复方案)
- 每季度进行渗透测试,模拟黑客攻击路径
-
合规先行,技术适配:
- 遵循《生成式人工智能服务管理暂行办法》等法规要求
- 在隐私保护技术中预留合规审计接口(如数据溯源日志)
六、总结:安全——智能体协作的“隐性竞争力”
智能体系统的价值,不仅在于功能强大,更在于“安全可靠”:
- 对抗攻击防御确保系统在恶意环境中稳定运行
- 安全对齐方案让智能体符合行业规范与人类价值观
- 隐私保护技术破解“数据共享”与“安全合规”的矛盾
通过本文的技术方案,开发者可构建具备“防御-对齐-保护”三重能力的智能体系统,为金融、医疗等敏感领域的落地提供坚实保障。下一篇我们将深入探讨多智能体系统的评估与迭代,教你如何通过数据反馈持续优化智能体协作效率。欢迎关注系列课程,一起解锁智能协作的更多可能!
版权声明:本文为原创技术文章,转载请注明出处并保留完整内容。如需获取AgentPrune防御代码或联邦学习部署模板,可在评论区留言或访问作者GitHub仓库。