开源项目介绍:GroundingDINO-TensorRT-and-ONNX-Inference
项目地址:https://github.com/wingdzero/GroundingDINO-TensorRT-and-ONNX-Inference
开源时间:2024.11.x
项目分享将GroundingDINO中模型导出onnx后python推理、onnx转trt模型、trt模型python推理代码。这里导出的模型与hpc203/GroundingDINO-onnxrun 导出的onnx模型是完全通用的。基于这里提供的trt模型python推理代码,可以实现c++ 下tensorrt推理GroundingDINO模型,基于tensorrt推理fp16模型,预计可以提升2~3倍的推理速度。
使用自己的数据微调,请参考:使用自己的数据对groundingdino进行微调
GroundingDINO模型导出为onnx c++部署,请参考:GroundingDINO导出为onnx模型实现python与c++部署
1、基本使用
1.1 下载groundingdino_swint_ogc
在https://huggingface.co/ShilongLiu/GroundingDINO/tree/main中下载groundingdino_swint_ogc.pth,或者将自己微调好的模型放置到weights目录下
1.2 导出onnx
执行 export_onnx.py
导出的模型为 weights/grounded_opset17_dynamic_4.onnx
执行 onnx_inference.py 验证模型是否成功导出,输出以下信息表示导出成功

代码测试保存的图片如下

1.3 导出tensort模型
参考https://hpg123.blog.csdn.net/article/details/142029669 安装tensorrt环境(c++与python运行环境)
将export_engine.py代码中的关键代码修改为刚刚导出的onnx模型路径
ONNX_SIM_MODEL_PATH = 'weights/grounded_opset17_dynamic_4.onnx'
完整如下所示,以下代码的亮点在于修改profile.set_shape后,可以适用于将任意onnx模型转换为静态的trt模型。同时,代码默认导出的是fp16的模型。
import os
import tensorrt as trt
ONNX_SIM_MODEL_PATH = 'weights/grounded_opset17_dynamic_4.onnx'
TENSORRT_ENGINE_PATH_PY = 'weights/grounded_opset17_fixed_fp16_4.engine'
def build_engine(onnx_file_path, engine_file_path, flop=16):
trt_logger = trt.Logger(trt.Logger.VERBOSE) # 记录详细的模型转换日志(包括每一层的详细信息)
builder = trt.Builder(trt_logger)
network = builder.create_network(
1 << (int)(trt.NetworkDefinitionCreationFlag.EXPLICIT_BATCH)
)
# 解析ONNX模型
parser = trt.OnnxParser(network, trt_logger)
with open(onnx_file_path, 'rb') as model:
if not parser.parse(model.read()):
print('ERROR: Failed to parse the ONNX file.')
for error in range(parser.num_errors):
print(parser.get_error(error))
return None
print("Completed parsing ONNX file")
config = builder.create_builder_config()
config.set_memory_pool_limit(trt.MemoryPoolType.WORKSPACE, 2 << 30)
# 如果FP16支持则启用
if builder.platform_has_fast_fp16 and flop == 16:
print("Export FP16 engine")
config.set_flag(trt.BuilderFlag.FP16)
if os.path.isfile(engine_file_path):
try:
os.remove(engine_file_path)
except Exception:
print("Cannot remove existing file: ", engine_file_path)
print("Creating TensorRT Engine")
config.set_tactic_sources(1 << int(trt.TacticSource.CUBLAS))
profile = builder.create_optimization_profile()
# 设置输入维度(固定)
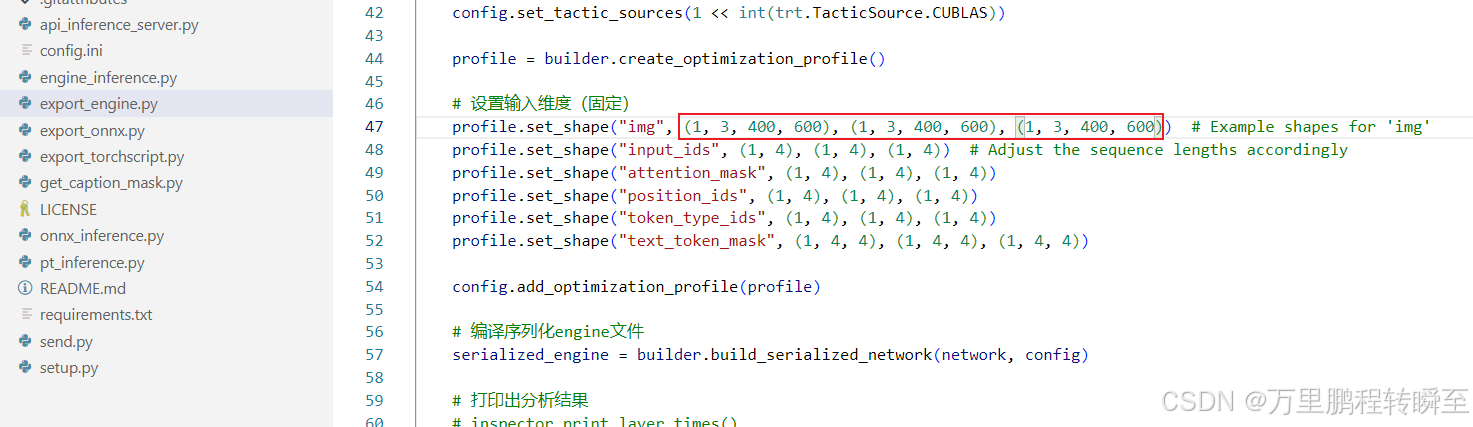
profile.set_shape("img", (1, 3, 800, 1200), (1, 3, 800, 1200), (1, 3, 800, 1200)) # Example shapes for 'img'
profile.set_shape("input_ids", (1, 4), (1, 4), (1, 4)) # Adjust the sequence lengths accordingly
profile.set_shape("attention_mask", (1, 4), (1, 4), (1, 4))
profile.set_shape("position_ids", (1, 4), (1, 4), (1, 4))
profile.set_shape("token_type_ids", (1, 4), (1, 4), (1, 4))
profile.set_shape("text_token_mask", (1, 4, 4), (1, 4, 4), (1, 4, 4))
config.add_optimization_profile(profile)
# 编译序列化engine文件
serialized_engine = builder.build_serialized_network(network, config)
# 打印出分析结果
# inspector.print_layer_times()
# 如果引擎创建失败
if serialized_engine is None:
print("引擎创建失败")
return None
# 将序列化的引擎保存到文件
with open(engine_file_path, "wb") as f:
f.write(serialized_engine)
print("序列化的引擎已保存到: ", engine_file_path)
return serialized_engine
if __name__ == "__main__":
build_engine(ONNX_SIM_MODEL_PATH, TENSORRT_ENGINE_PATH_PY)
代码执行结束后,输出模型保存路径。

将engine_inference.py中第286行关于draw_results中的第一个参数修改为修改为 np.copy(image), 完整效果如下所示
draw_results( np.copy(image), boxes, confs, phrases, img_save_path=os.path.join(args.output, save_file_name))
执行engine_inference.py,代码输出如下

识别结果保存为 images\out\car_1_result.jpg

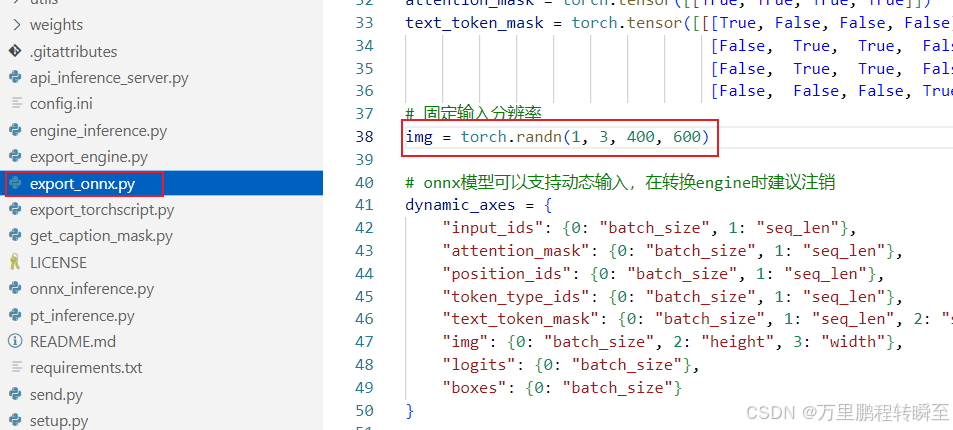
2、导出400x600推理模型
1、将onnx导出尺寸设置为400x600,重新导出模型
2、将onnx转trt中的size设置为400x600,重新导出模型
3、将resize函数里面的设置从800修改为400 (trt推理)
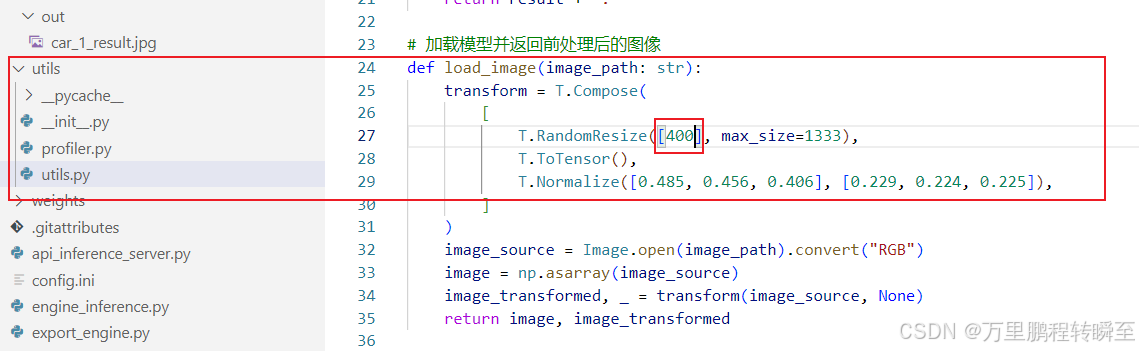
4、将resize函数里面的设置从800修改为400 (torch与onnx推理)
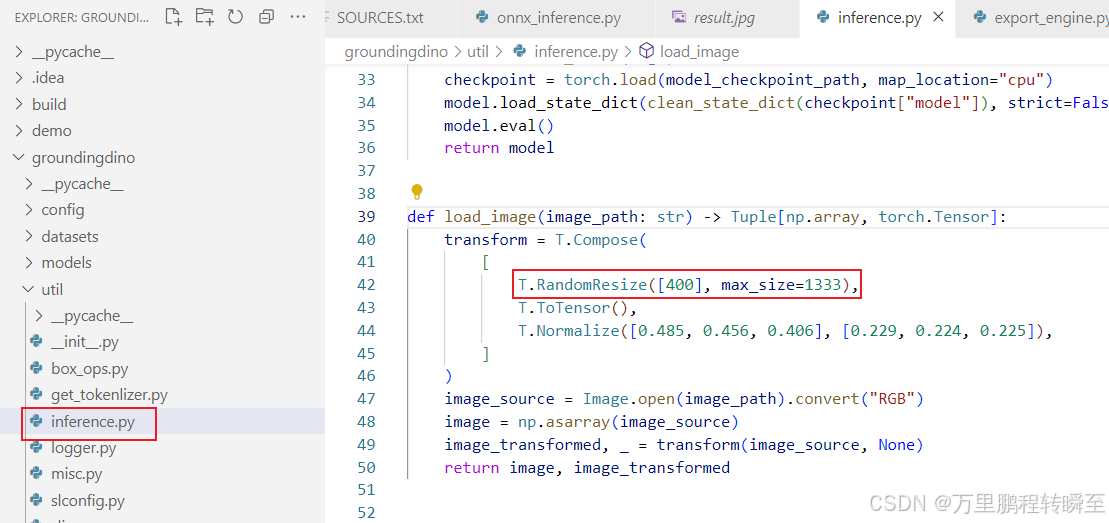
5、执行engine_inference.py 推理tensorrt模型,当前可以发现耗时为57ms。比博主实现的onnx c++推理差不多快了一倍。
