【Java集合】LinkedHashSet源码深度分析
参考笔记:java LinkedHashSet 源码分析(深度讲解)-CSDN博客
目录
一、前言
二、LinkedHashSet简介
三、LinkedHashSet底层实现
四、LinkedHashSet的源码解读
0. 准备工作
1. 向集合中添加第一个元素
① 跳入无参构造
② 跳入resize方法
③ 跳出resize方法,回到 putVal 方法
④ 回到演示类
2. 继续向集合添加元素
① 向集合中添加重复元素
② 向集合中添加第二个元素
③ 向集合中添加第三个元素
④ 向集合中添加第四个元素
⑤ 向集合中添加第五个元素(重要)
五、完结
一、前言
本篇博文是对集合篇章——单列集合 Set 的内容补充。 Set 集合常见的实现类有两个——HashSet、TreeSet。在我的另一篇博文中已经分析了 HashSet 的源码,知道了 HashSet 的底层其实就是 HashMap 。链接如下:
【Java集合】HashSet源码深度分析-CSDN博客
https://blog.csdn.net/m0_55908255/article/details/146999979?spm=1011.2415.3001.5331 本文要解读的是 HashSet 的一个子类——LinkedHashSet,非常建议先阅读一下HashSet 源码分析,因为 LinkedHashSet、HashSet 底层调用的方法几乎一致,只是有略微的差别
注意:本文对 HashSet 源码的解读基于主流的 JDK 8.0 的版本

二、LinkedHashSet简介
LinkedHashSet 是 HashSet 的子类,而由于 HashSet 实现了 Set 接口,因此 LinkedHashSet 也间接 implements 了 Set 接口。LinkedHashSet 类位于 java.util.LinkedHashSet 下,其类定义和继承关系图如下:

三、LinkedHashSet底层实现
① LinkedHashSet 在底层会用到一个 HashMap$Node[ ] 类型的 table 表( Node 类是 HashMap 中维护的一个静态内部类),该 table 表即用来存储元素,这一点和 HashSet 是一样的。(实际上在通过 add 方法添加元素时,LinkedHashSet、HashSet 底层都是走的 HashMap 的 put 方法) table 属性的定义如下:

由于 table 属性是由 HashMap 类维护的,所以,无论是 HashSet 还是 LinkedHashSet ,都需要先成功访问到 HashMap 。以 HashSet 为例,HashSet 中维护了一个 HashMap<E,Object> 类型的 map 属性,而 HashSet 的构造器中对该 map 属性进行了初始化。
如此一来,HashSet 可以借助该 map 对象即可访问到 HashMap 中维护的 table 属性。如下图所示:
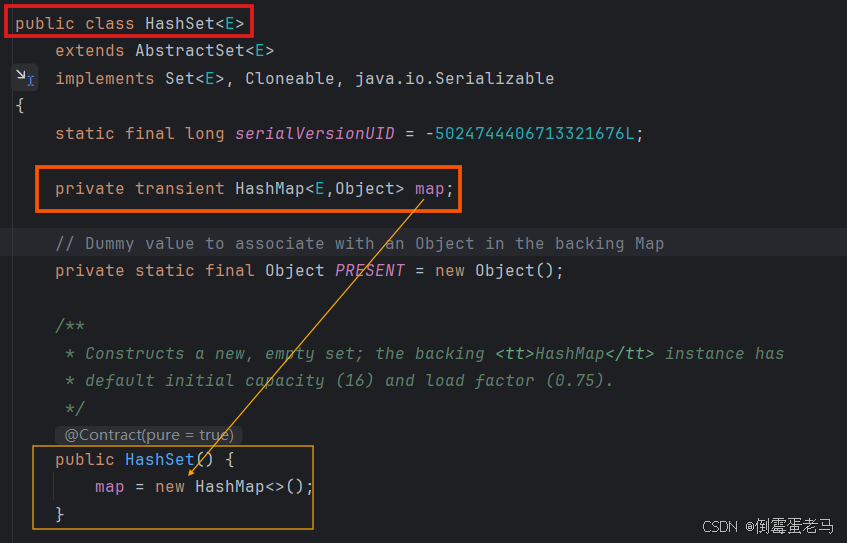
LinkedHashSet 的父类是 HashSet ,因此该 map 属性自然可以继承给 LinkedHashSet ,所以LinkedHashSet、HashSet 都是通过 private transient HashMap<E, Object> map 来间接调用 HashMap 中的内容
只不过 HashSet 的构造器中是直接将 map 置为了一个 HashMap 类型的对象,而在 LinkedHashSet 的构造器中,却是使用多态的方式,将 map 置为了一个 LinkedHashMap 类型的对象( LinkedHashMap 继承自 HashMap ,如此一来,亦可借助 map 对象访问到 HashMap 中维护的 table 数组,因为 table 数组是非私有的),如下图所示 :

② LinkedHashSet 通过 head 和 tail 维护了一个双向链表,head、tail 是 LinkedHashMap 中的两个属性
head:指向双向链表头结点的指针
tail:指向双向链表尾结点的指针
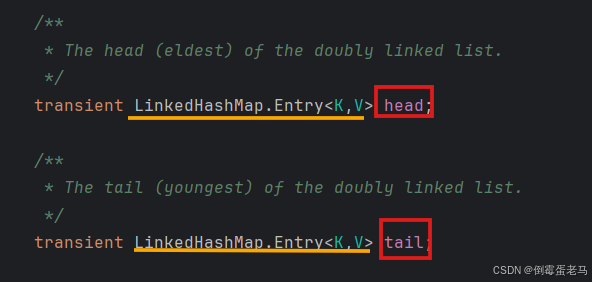
此处的 Entry 是 LinkedHashMap 的一个静态内部类,它继承了 HashMap 的一个静态内部类 Node,Entry、Node 的定义如下:
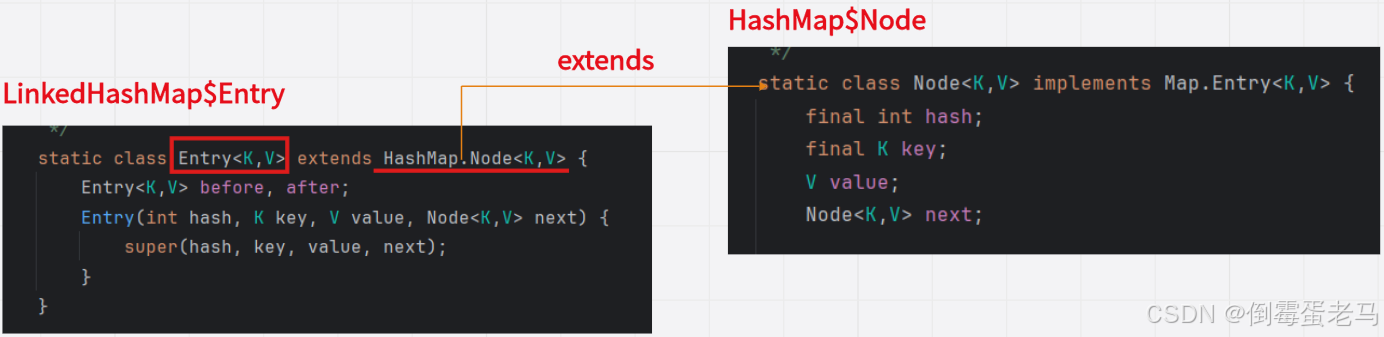
③ 如上图所示,每个 Entry 结点中维护了 before,after 两个属性,其中通过 before 指向前一个结点,通过 after 指向后一个结点
LinkedHashMap$Entry 类又继承自 HashMap$Node 类。在 Entry 类的构造器中,通过super(hash,key,value,next) 调用 Node 类的构造器。由此可知,与 HashSet 集合一致,在使用 LinkedHashSet 集合时:
- key:存放加入到 LinkedHashSet 集合中的元素
- hash:存放元素的哈希值
- next:指向挂载在同一链表下的后面一个结点,如果没有,则 next = null
- value:存储 PRESENT占位符,无实际意义,PRESENT 占位符是 HashSet 类的一个属性,如下:

④ LinkedHashSet 的底层其实就是 LinkedHashMap,关于这一点,可以类比 HashSet 的底层是 HashMap
⑤ LinkedHashSet 在添加元素时的底层规则和 HashSet 高度一致,在后续的源码解读部分可以看到。仍然是先求出添加元素的 hash 值,然后根据特定算法将其转换一个索引值。这个索引值决定该元素在集合中应该存放的位置
⑥ 得到元素 hash 值,将其转换为索引值后,添加元素的规则:
-
当索引值对应的位置没有元素存在时:直接将当前元素加入集合
-
当索引值对应的位置有元素存在时,调用 equals 方法判断当前添加元素与该位置处的元素是否相等
-
相等:放弃添加该元素(因为 LinkedHashSet 不允许重复)
-
不相等:将当前元素添加到(挂到)该位置处对应的链表的最后。这便实现了 "数组+链表" 的结构。如下图所示:
-

说明:LinkedHashSet 集合如何添加元素、如何判断重复元素、扩容机制、链表转换为红黑树与 HashSet 是完全一致的
四、LinkedHashSet的源码解读
0. 准备工作
用以下代码作为演示类,一步一步 Debug :
import java.util.LinkedHashSet;
public class demo {
public static void main(String[] args) {
LinkedHashSet linkedHashSet = new LinkedHashSet();
linkedHashSet.add(141);
linkedHashSet.add(141);//重复元素,放弃添加
linkedHashSet.add("CSDN");
linkedHashSet.add(11);
linkedHashSet.add(new Apple("红富士1"));
linkedHashSet.add(new Apple("红富士2"));
}
}
class Apple {
private String name;
public Apple(String name) {
this.name = name;
}
//所有Apple对象实例都返回相同的哈希码值
@Override
public int hashCode() {
return 100;
}
}1. 向集合中添加第一个元素
① 跳入无参构造
首先跳入 LinkedHashSet 的无参构造,由于内部嵌套的构造器比较器多,所以我以流程图展示,如下图所示 :
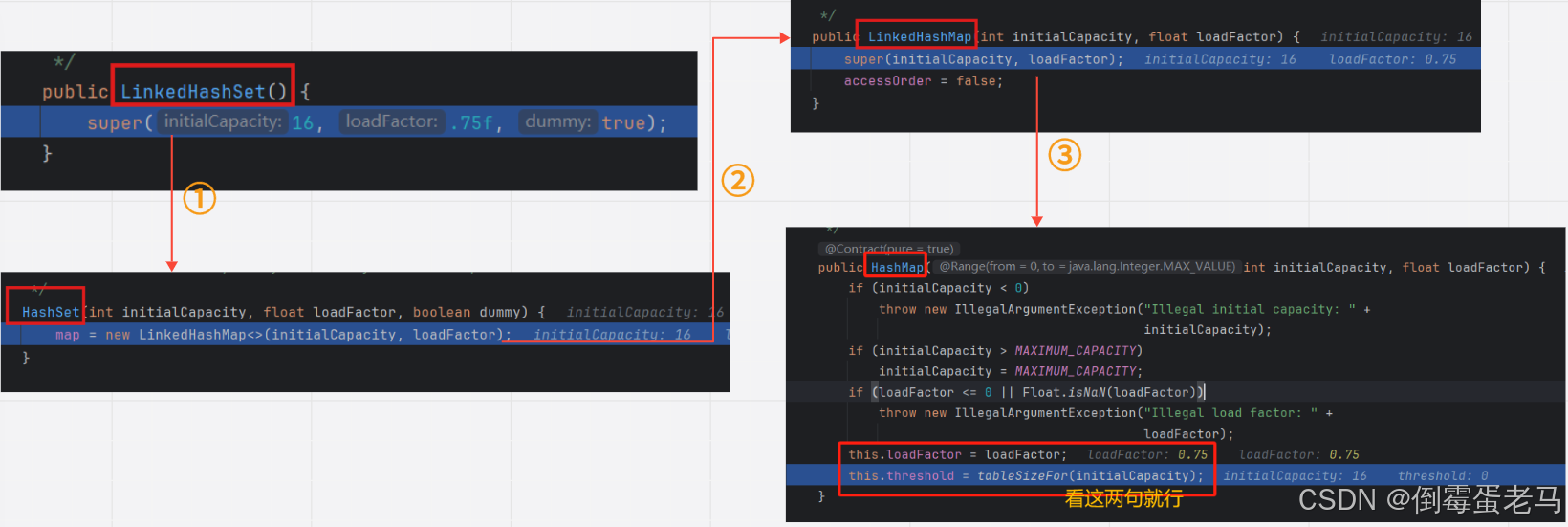
可以看到,调用 LinkedHashSet 的无参构造,最终是走到了 HashMap 的构造器 public HashMap(int initialCapacity,float loadFactor) 中,最后两句赋值语句中的 loadFactor 即默认增长因子、threshold 即临界值,看过 HashSet 集合的源码分析都知道这两个属性,这里就不再赘述了
最后一行给临界值 threshold 赋值是调用了 tableSizeFor(intitialCapacity) 方法,我们追进去看看,其源码如下所示:
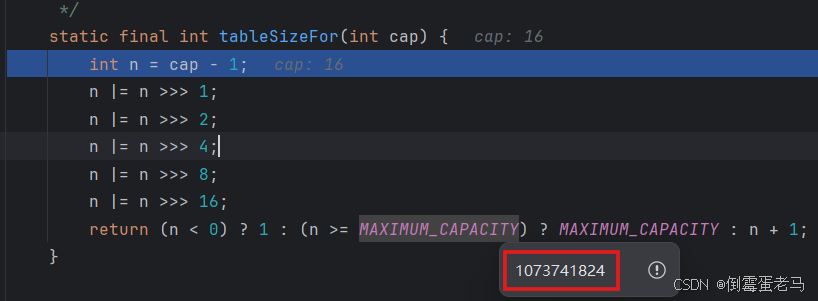
源码中的 n |= n >>> 1 相当于 n = n | ( n >>> 1 ) ,这里大家可以自己计算一下,经过中间这几行 n 还是为 15,没有任何改变。我们只需要关注最后一行的 return 语句即可 。| 和 >>> 不懂的可以看我写的一篇博客的 "5.2位运算符" 部分,链接如下:
【Java SE】基础知识1-CSDN博客![]() https://blog.csdn.net/m0_55908255/article/details/145900460?spm=1011.2415.3001.5331 return 语句的返回值是一个双重复合的三目运算符。什么意思呢?就是如果前面三目运算符的判断条件 (n < 0) 成立,就返回 1 ,否则返回后面三目运算符的结果。显然前面运算符的判断条件 n < 0 显然不成立,所以要返回后面三目运算符的结果;
https://blog.csdn.net/m0_55908255/article/details/145900460?spm=1011.2415.3001.5331 return 语句的返回值是一个双重复合的三目运算符。什么意思呢?就是如果前面三目运算符的判断条件 (n < 0) 成立,就返回 1 ,否则返回后面三目运算符的结果。显然前面运算符的判断条件 n < 0 显然不成立,所以要返回后面三目运算符的结果;
后面的三目运算符的判断条件 n >= MAXIMU_CAPACITY = 1073741824,显然不成立。所以 return 语句最后返回的值就是 n + 1 = 16
跳出 tableSizeFor 方法,如下 :

🆗,接下来我们逐层返回,跳出无参构造器,回到演示类中,查看此时集合的状态,如下图所示:
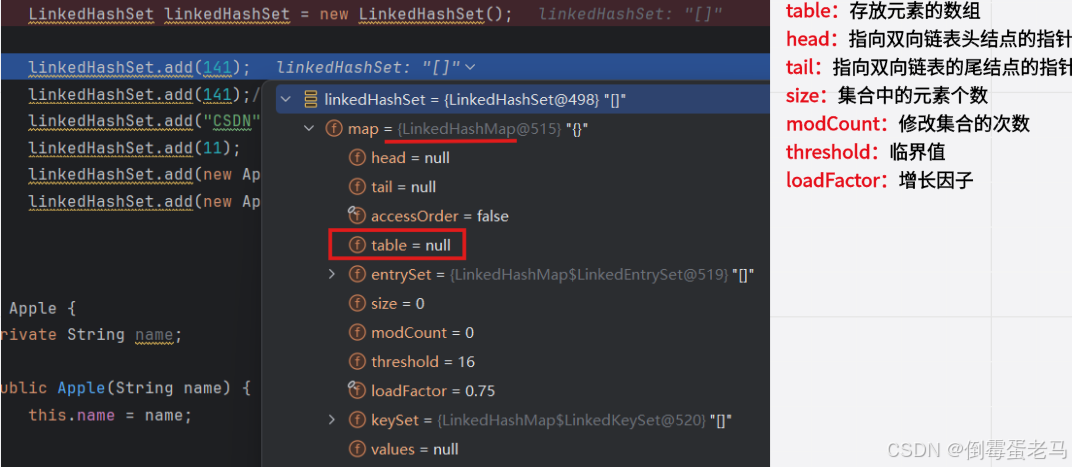
可以看到,此时的 map 对象是 LinkedHashMap 类型,用来存放元素的 table 数组为 null,数组元素个数 size = 0 ,临界值 threshold = 16
② 跳入resize方法
准备向集合中添加第一个元素141 。注意, LinkedHashMap 和 HashMap 在底层添加元素时,几乎完全一样,前面几步跳入 add方法 ——> 跳入put方法 ——> 跳入putVal方法二者是完全一致的。所以这里就不再赘述了。在我的另一篇博客 HashSet 源码深度分析中已经非常详细地 Debug 过了
我们直接跳到比较重要的地方。在 putVal 方法中,第一个 if 语句满足判断,如下 :

可以看到,我们要进入 resize 方法,resize 方法也是 "老演员" 了,它的作用就是对 table 数组进行扩容, resize 方法要返回一个 Node 类型( HashMap$Node )的数组给 tab 数组。我们跳入 resize 方法,其源码如下:
//table数组扩容
final Node<K,V>[] resize() {
//oldTab记录旧数组,此时table = null ,因此 oldTab = null
Node<K,V>[] oldTab = table;
//记录旧数组的长度(注意,不是元素个数),oldCap = 0
int oldCap = (oldTab == null) ? 0 : oldTab.length;
//记录就旧数组的临界值,oldThr = threshold = 16
int oldThr = threshold;
//newCap记录新数组的长度,newThr记录新数组的临界值
int newCap, newThr = 0;
if (oldCap > 0) {//oldCap = 0,不跳入该if语句
if (oldCap >= MAXIMUM_CAPACITY) {
threshold = Integer.MAX_VALUE;
return oldTab;
}
else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY &&
oldCap >= DEFAULT_INITIAL_CAPACITY)
newThr = oldThr << 1; // double threshold
}
//oldThr = 16 > 0,执行该 else if 语句
else if (oldThr > 0) // initial capacity was placed in threshold
//newCap = oldThr = 16
newCap = oldThr;
else { // zero initial threshold signifies using defaults
newCap = DEFAULT_INITIAL_CAPACITY;
newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY);
}
//newThr = 0,跳入该 if 结构
if (newThr == 0) {
//新临界值 = 新数组长度 * 增长因子 = 16 * 0.75 = 12
float ft = (float)newCap * loadFactor;
//这里是作一个健壮性判断,最终newThr = 12
newThr = (newCap < MAXIMUM_CAPACITY && ft < (float)MAXIMUM_CAPACITY ?
(int)ft : Integer.MAX_VALUE);
}
//将新临界值赋值给 threshold 属性,threshold = newThr = 12
threshold = newThr;
@SuppressWarnings({"rawtypes","unchecked"})
//创建一个容量为 newCap = 16 的新数组
Node<K,V>[] newTab = (Node<K,V>[])new Node[newCap];
//将 table 数组赋值为 newTab
table = newTab;
/*
后续就是如果原数组不为空,则将原数组中的内容拷贝到新数组中
由于此时 oldTab = null ,所以不会执行跳入该 if 结构
*/
if (oldTab != null) {
for (int j = 0; j < oldCap; ++j) {
Node<K,V> e;
if ((e = oldTab[j]) != null) {
oldTab[j] = null;
if (e.next == null)
newTab[e.hash & (newCap - 1)] = e;
else if (e instanceof TreeNode)
((TreeNode<K,V>)e).split(this, newTab, j, oldCap);
else { // preserve order
Node<K,V> loHead = null, loTail = null;
Node<K,V> hiHead = null, hiTail = null;
Node<K,V> next;
do {
next = e.next;
if ((e.hash & oldCap) == 0) {
if (loTail == null)
loHead = e;
else
loTail.next = e;
loTail = e;
}
else {
if (hiTail == null)
hiHead = e;
else
hiTail.next = e;
hiTail = e;
}
} while ((e = next) != null);
if (loTail != null) {
loTail.next = null;
newTab[j] = loHead;
}
if (hiTail != null) {
hiTail.next = null;
newTab[j + oldCap] = hiHead;
}
}
}
}
}
return newTab;
}前面几步都还和 HashSet 集合添加第一个元素时一样,如下 :

将 table 数组引用赋值给了一个 Node 类型的数组 oldTab ,即 oldTab 引用现在也是null 了。第二行又用一个三目运算符最终将 0 赋值给了 oldCap 变量
下一步开始就要不一样了,如下:

注意看,不知道大家还记不记得,在 HashSet 的源码分析中,第一次添加元素时,这里的 threshold = 0 。而 LinkedHashSet 第一次添加元素时,threshold = 16,原因我们在 "①跳入无参构造" 已经看到:在调用 LinkedHashSet 的无参构造时,底层会将 threshold 初始化为 16
继续往下执行,如下:

可以看到,首先执行 oldThr = threshold = 16,将 threshold 赋值给 oldThr 变量,然后又定义了 newCap = newCapacity,见名知意,即新数组的长度;newThr = newThreShold,即新数组的临界值。第三行的 if 语句显然判断不成立,不进入它。但后面的 else if 语句的判断是成立的,如下 :

else if 语句中,newCap = oldThr = 16,所以 LinkedHashSet 集合和 HashSet 集合一样,第一次扩容都是将 table 数组的长度扩大至 16
继续,接下来的一个 if 语句如下:

由于 threshold 的改变,我们并没有像 HashSet 那样进入 if --- else if --- else 中的 else 语句,而是进入了 else if 语句,所以此时 newThr 变量还是默认值 0 ,因此跳入上图的 if 语句中,先是计算 ft = 新数组容量 * 增长因子 = 16 * 0.75 = 12,再利用三目运算符作一个健壮性判断,最终新数组的临界值 newThr = 12
继续往下执行,如下图 :

后面几步就都一样了。threshold = newThr = 12,即将临界值 12 赋值给 threshold 属性,关于为什么要设置临界值 threshold ,这里就不再赘述了
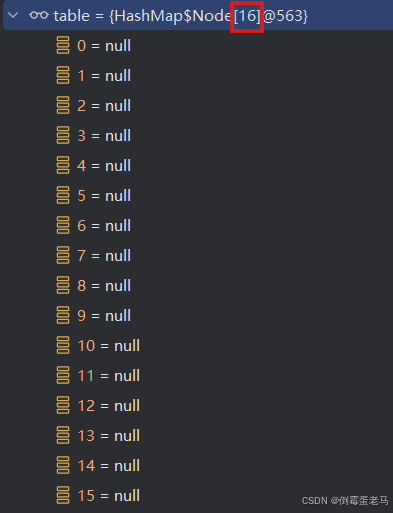
接着,又是 new 一个长度为 16 的 Node (HashMap$Node) 类型数组,然后将新数组的地址赋给了 newTable 引用,并由 newTab 引用传递给 table 。如下:

到此, table 已经由 null 变为了长度为 16 的数组 ,如下图所示:
再往下是一个非常大的 if 条件语句,如下 :

该 if 语句的作用是:如果旧数组不为空,则需要将旧数组中的元素全部拷贝到新数组中。 由于此时旧数组 oldTab = null,因此条件不成立,不执行
OK,这下 resize 方法执行完了,返回 new 出的新数组,如下 :

③ 跳出resize方法,回到 putVal 方法
执行完 resize 函数,我们先回到 putVal 方法,如下 :

可以看到, n = 16 ,即新数组的长度
与 HashSet 一样,仍然是根据当前元素的 hash 值:141,通过算法 [ i = (n-1) & hash ] 获得当前欲添加元素在 table 数组中应该存放的索引位置。然后判断,如果 table 数组该索引处为空,就直接放进去;不为空的话就去下面的 else 语句,去链表中一一进行判断,如果不与链表中的元素重复,则挂载到链表尾部;如果与链表中的某个元素重复,则放弃添加
当前欲添加元素 141 计算得到的索引位置为 i = (n-1) & hash = 13,如下图所示:
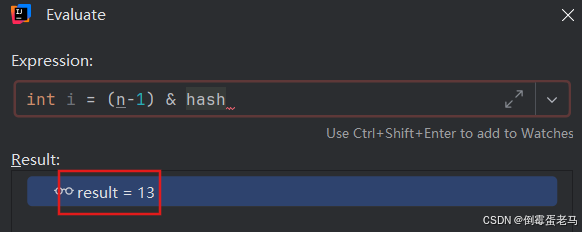
因为 141 是集合添加的第一个元素,所以集合的对应索引处肯定为 null ,条件满足,继续执行 if 中的语句,"tab[i] = tab[13] = newNode(hash,key,value,null)",直接将该元素加入 table 数组中索引为 13 的位置
这里需要注意,由于 LinkedHashSet 的底层实现是 LinkedHashMap,所以这里调用的 "newNode(hash,key,value,null)" 方法是 LinkedHashMap 中的 newNode ,其源码如下:
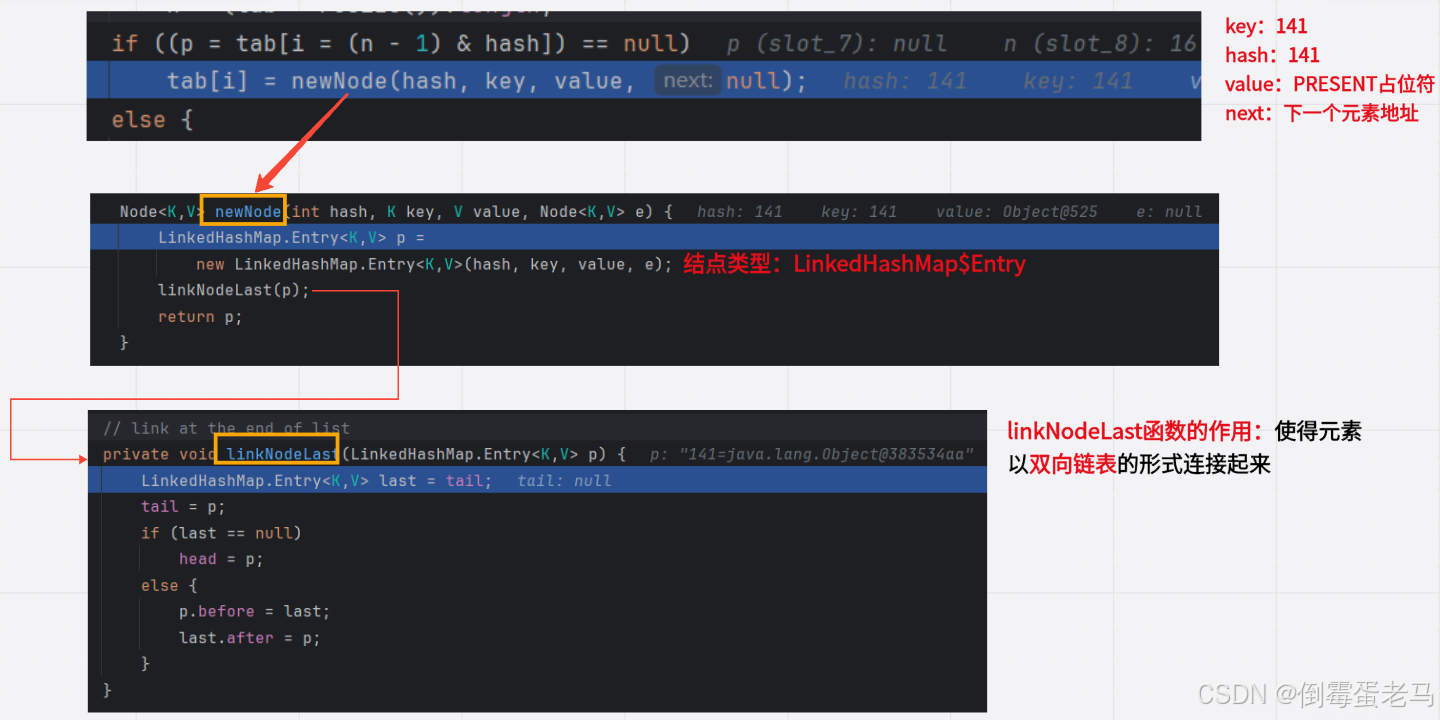
由于 LinkedHashSet 的 table 数组中每个结点类型是 LinkedHashMap$Entry ,所以在上图中可以看到,newNode 方法中先创建一个 LinkedHashMap$Entry 类型结点,并存储 hash 属性:141, key 属性:141, value 属性:PRESENT占位符, next 属性:null。这里我们再看一下 Entry、Node 的定义,如下:
接着 newNode 方法中调用 linkNodeLast 方法处理 Entry 的 before、after 属性,使得结点以双向链表的形式连接起来
OK,逐层返回到 putVal 方法, tab[i] = tab[13] = newNode (hash,key,value,null) 语句执行完毕
继续往下执行,如下图所示:
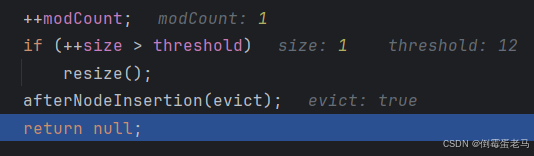
1° modCount 老演员了,表示修改集合的次数
2° if 语句,判断当前集合中元素的个数 size 是否超过了临界值 threshold ,如果超过临界值就调用 resize 方法对 table 数组进行扩容
3° afterNodeInsertion (true) ,调用的是 LinkedHashMap 中的 afterNodeInsertion 方法,该方法在插入新结点后触发,用于移除最老结点(eldest entry,即双向链表的第一个结点)。但是在默认情况下,afterNodeInsertion 内部调用的 removeEldestEntry 方法的返回值是 false ,不执行移除,所以此处的 afterNodeInsertion 方法相当于什么都没做
到这, putVal 方法也结束,并最终返回了 null ,代表添加元素成功
④ 回到演示类
从 putVal 方法逐层返回到演示类中,此时的 LinkedHashSet 集合状态如下:
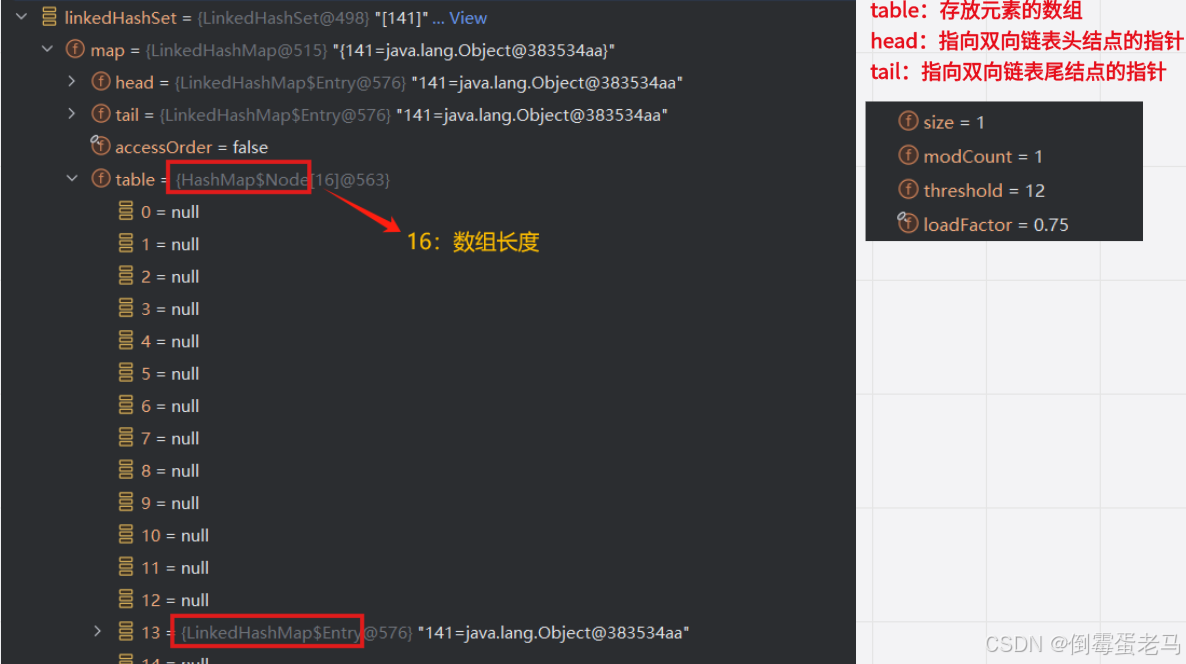
可以看到,table 数组成功初始化为长度 = 16 的数组, 141 元素也成功添加到了集合索引为 13 的位置
另外很重要的是,可以看到 table 数组是 Node(HashMap$Node) 类型,但是里面保存的元素却是 Entry(LinkedHashMap$Entry) 类型。一个类型的数组里面存放了另一类型的元素,请问,你想到了什么?😎!没错,多态数组!!!这里我们再看一下这两个类的定义:
因为 Entry 继承了 Node ,所以一个父类的引用可以指向子类的对象
🆗,向 LinkedHashSet 集合添加第一个元素完毕
2. 继续向集合添加元素
① 向集合中添加重复元素
当我们重复添加 141 元素时,肯定无法加入。判断重复元素的底层逻辑 和 HashSet 是完全一样的,这里就不再演示了。大家可以 Debug 一下看看
这里看一下执行该行代码之后的集合状态,如下:
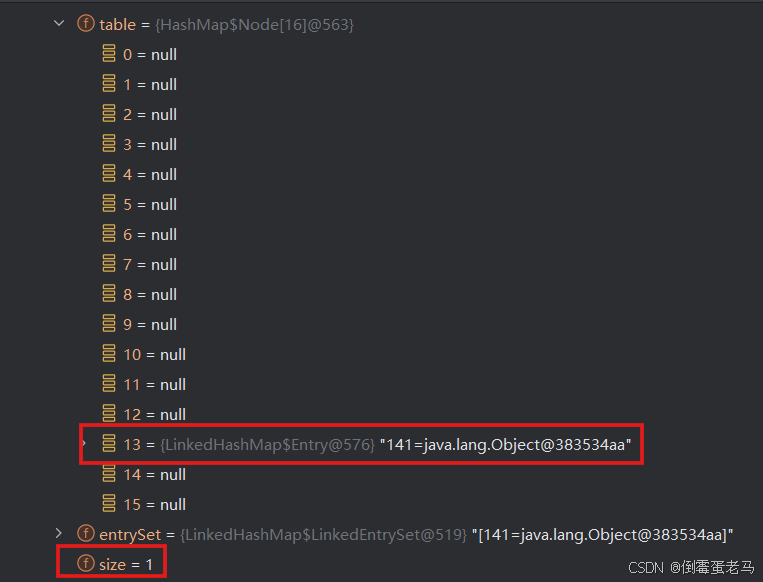
可以看到,此时集合中仍然只有一个元素 141,size = 1
② 向集合中添加第二个元素
继续向下执行,将 "CSDN" 元素加入集合中。此时集合的状态如下所示:
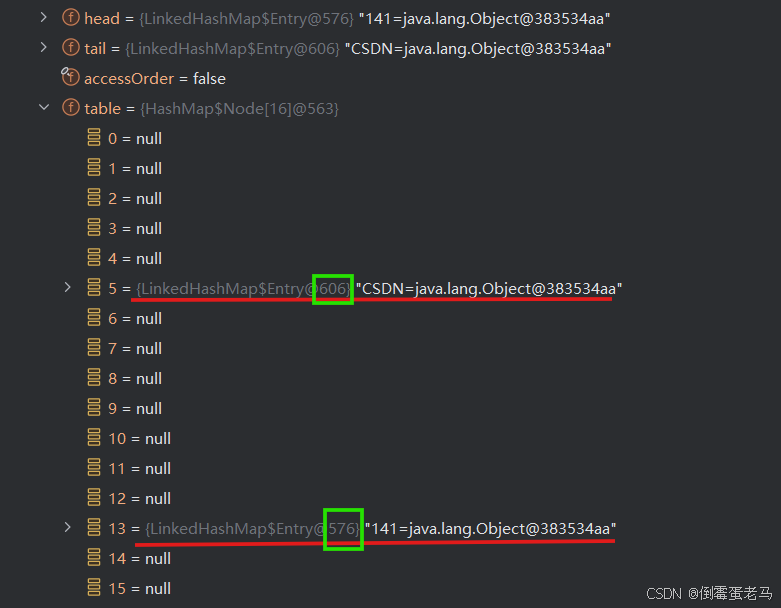
可以看到,目前 table 数组中有两个元素。注意,记住这两个元素目前的标识:141 的标识是 576 ,"CSDN" 的标识是 606
注意,重点的来了,如下:
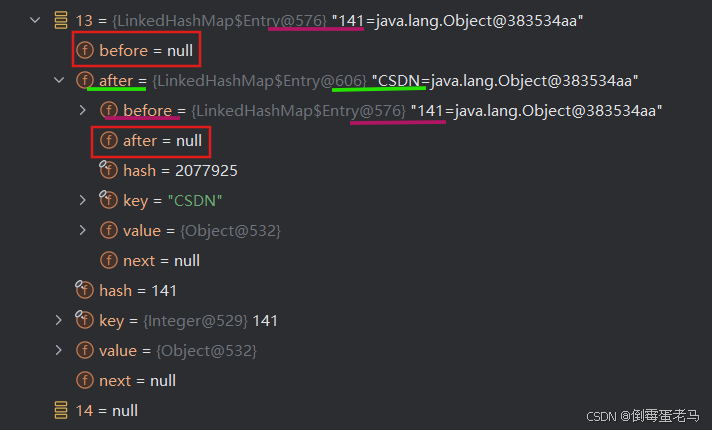
我们点开添加的第一个元素,可以看到,此时第一个元素 141 的 after 属性指向了第二个元素 "CSDN" ,而第二个属性的 before 属性则指向了第一个元素 141 ;并且 141 元素的 before 属性和 "CSDN" 元素的 after 属性均为 null 。此时, table 数组中的两个元素已然形成了一个简单的双向链表
并且,我们还可以看到 map 的 head、tail 属性分别指向了双向链表的第一个元素 141 和最后一个元素 "CSDN",如下图所示:
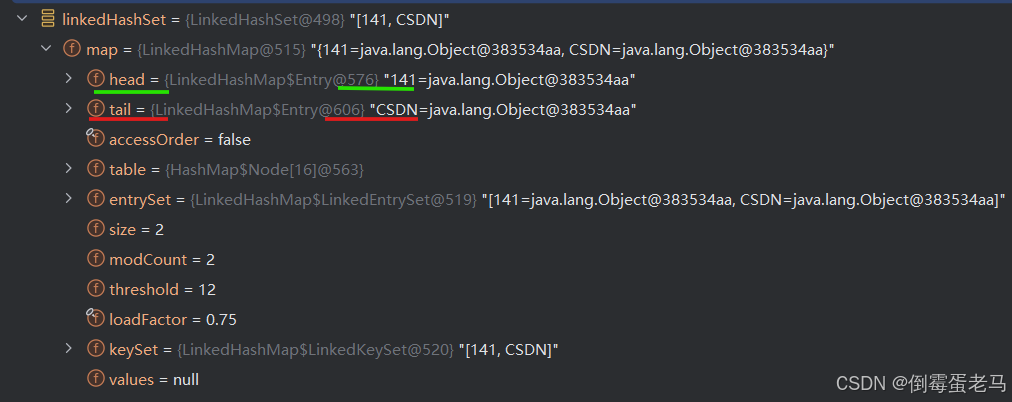
此时,linkedHashSet 的底层 "数组+链表" 结构如下图所示:

③ 向集合中添加第三个元素
继续向下执行,将元素 11 加入到集合中,此时集合的状态如下所示:
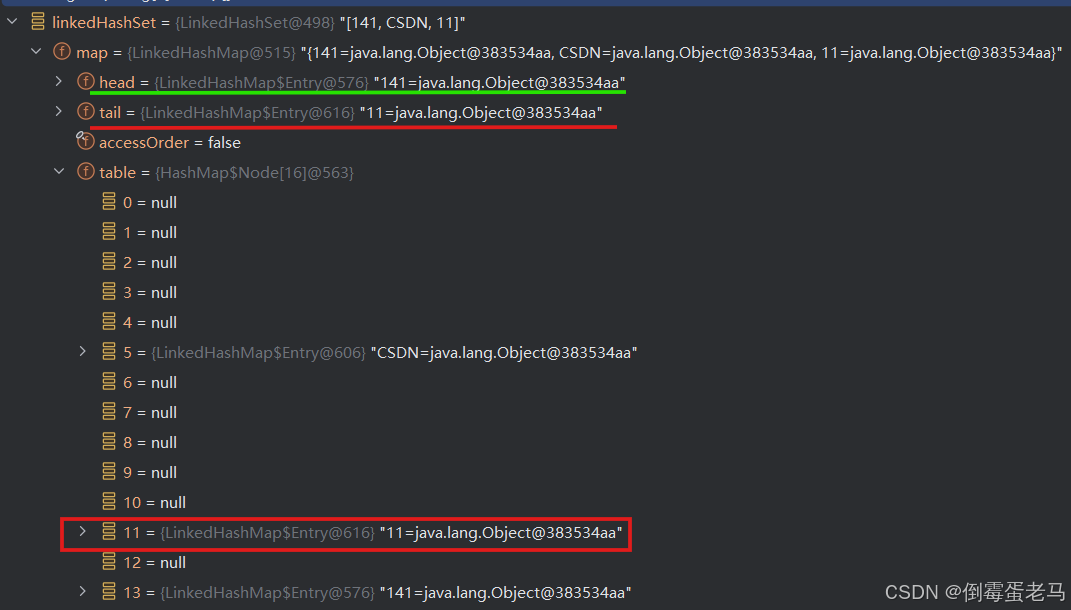
此时,linkedHashSet 的底层 "数组+链表" 结构如下图所示:
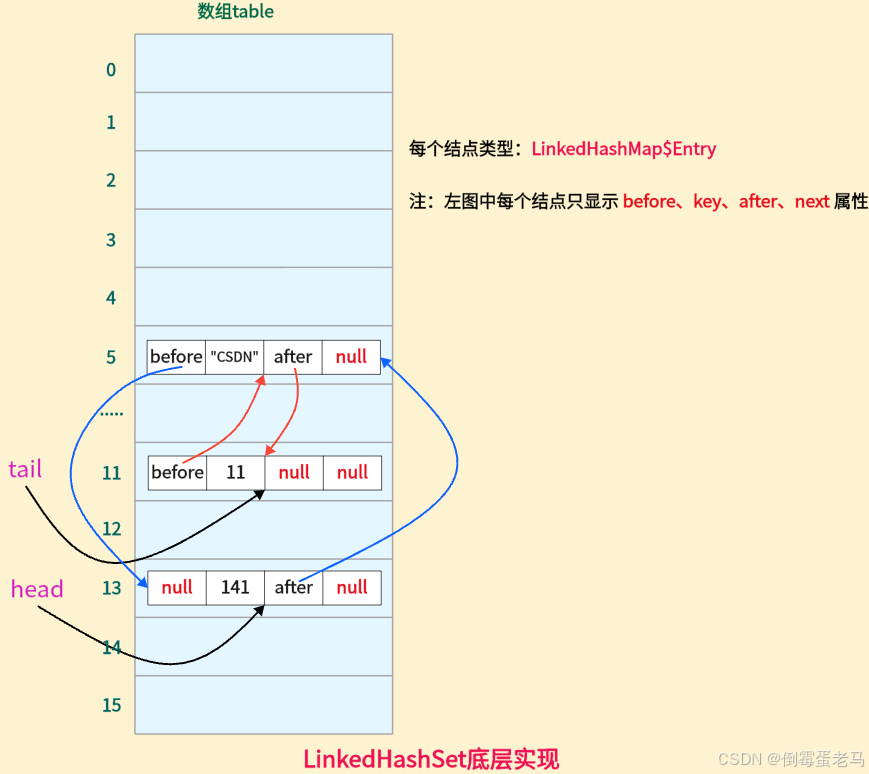
由于元素 11 是最后添加的,所以 tail 尾指针指向它
④ 向集合中添加第四个元素
继续向下执行,向集合中添加 new Apple("红富士1"),此时集合的状态如下所示:
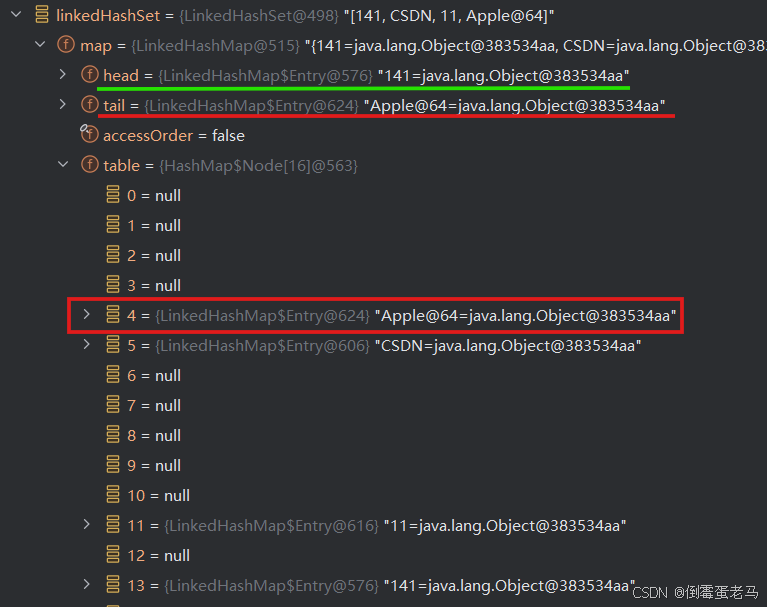
可以看到,new Apple ("红富士1") 存放在 table 数组的 4 索引处,标识为 624
此时, linkedHashSet 的底层 "数组+链表" 结构如下图所示:
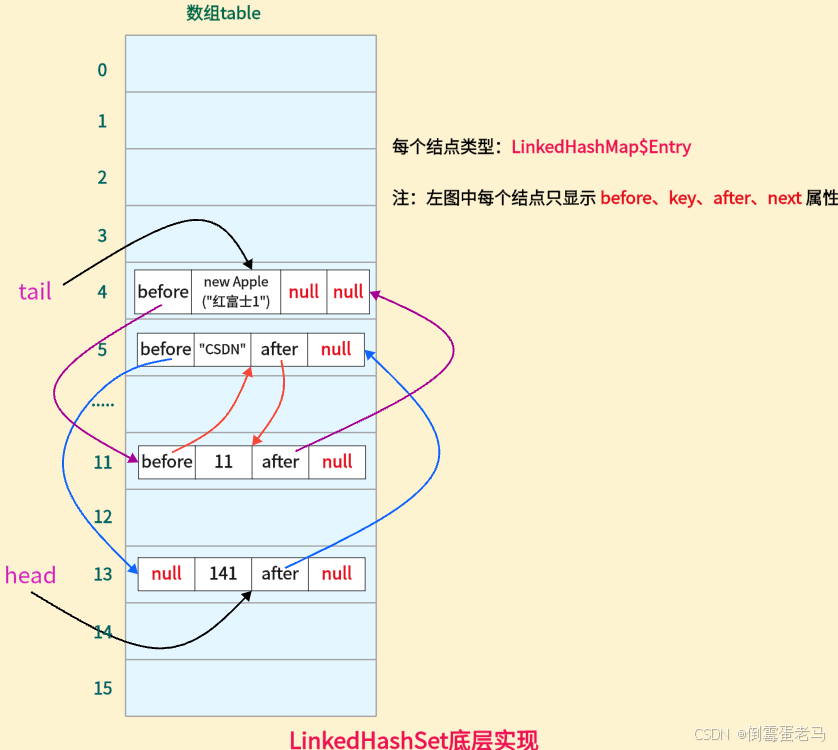
由于元素 new Apple("红富士1") 是最后添加的,所以 tail 尾指针指向它
⑤ 向集合中添加第五个元素(重要)
继续向下执行,向集合中添加 new Apple("红富士2")
注意,由于我们没有在 Apple 类重写 equals 方法,因此两个 Apple 对象会被判定为不同的元素,可以加入集合;由于在 Apple 类中重写了 hashCode 方法,因此这两对象最终得到的哈希值一样,因此它们会挂载到同一链表下。在前面的 ④ 已经知道,new Apple("红富士1") 存放在 table 数组的 4 索引处,标识为 624 ,因此 new Apple("红富士2") 将挂载到 table 数组索引 4 处的链表
挂载到同一链表下的过程与 HashSet 中是完全一致的,这里就不再赘述,我们直接看添加完该元素之后的集合状态,如下图所示:
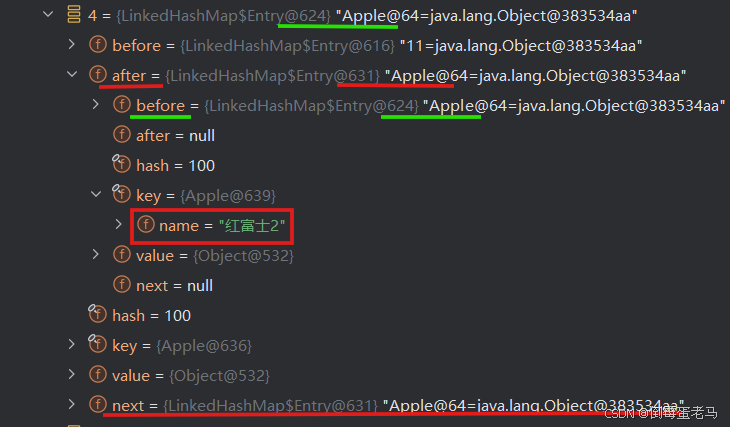
可以看到,新添加的元素 new Apple("红富士2") 与标识为 624 的元素 new Apple("红富士1") 确实挂载在了同一链表下
此时, linkedHashSet 的底层 "数组+链表" 结构如下图所示:
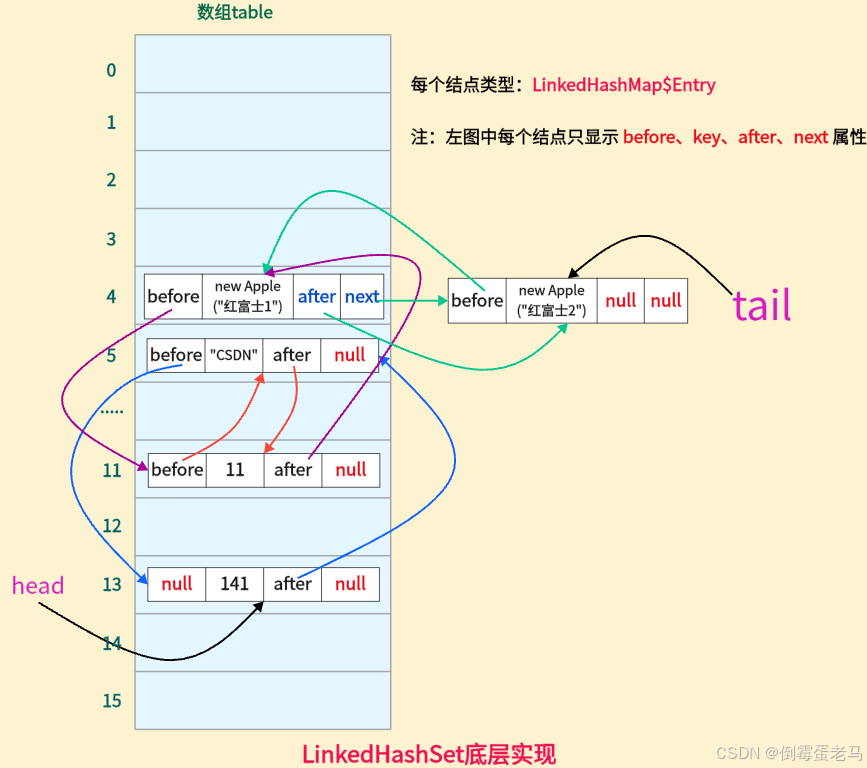
看着可能有点乱,但是看准 head、tail 和每个结点的 before、after ,还是可以很轻松找到顺序的,这里添加的顺序是:141 --> "CSDN" --> 11 --> new Apple("红富士1") --> new Apple("红富士2")
这里还要说明一下 after 和 next 的区别
1° after是用于双向链表中,专门指向下一个元素,没有下一个元素则为 null 。不管某一个结点的下一个元素是在 table 数组中其他索引处的位置,还是挂载在该结点的后面,after 都会指向它
2° next 则和我们在 HashSet 中分析的一样,如果数组某一个索引处的元素形成了链表, next 会指向链表中的下一个元素
3° 比如上图所示的元素 new Apple("红富士1"),它的 after 指向元素 new Apple("红富士2") 。由于元素 new Apple("红富士2") 恰好挂载在了它的后面,即它们在 table 数组同一索引处的位置,所以元素 new Apple("红富士1") 的 next 属性也指向元素 new Apple("红富士2")
4° 简单来说, after 是针对了整个双向链表,针对于所有元素,针对于全局;而 next 则是仅仅针对于同一索引位置处形成的单向链表,针对于 table 数组同一索引位置处的元素,针对于局部
5° 从源码角度分析,next 属性由 HashMap$Node 类维护,而 after 由 LinkedHashMap$Entry 类维护
所以,通过 Debug 和底层的"数组+链表"结构图看到,在 table 数组的所有元素中,只有第一个 Apple 对象元素 new Apple("红富士1") 的 next 属性有指向,且指向和它的 after 属性一样,指向了挂载在它后面的第二个 Apple 对象元素 new Apple("红富士2")
五、完结
🆗,以上就是本文 LinkedHashSet 源码分析的全部内容了。本文主要针对于与 HashSet 的差异展开讲解,如果对 HashSet 的源码比较熟悉,那看本文比会比较容易。由于 LinkedHashSet 集合如何判断重复元素、扩容机制、链表转换为红黑树和 HashSet 是完全一致的,所以本文不再赘述