懒人版)RF_NSGA2_Topsis随机森林做代理预测模型NSGA3结合熵权法Topsis反求最佳因变量和对应的最佳自变量组合(含帕累托前沿解)
随机森林做代理预测模型NSGA3结合熵权法Topsis反求最佳因变量和对应的最佳自变量组合(含帕累托前沿解)
(懒人救星版)RF_NSGA3_Topsis
(懒人救星版)RF_NSGA3
懒人救星版:
1.任意多输入多输出都可以用(采用如下三套数据集:
4输入2输出.xlsx 4输入3输出.xlsx 5输入3输出.xlsx
2.加入数据拟合散点图
数据特点:(多元化的数据)
包含0-1数据、大于1的数据和极大的数据(10的8次方)
3.统计误差指标和决定系数R2都有
每个代码压缩文件包改动代码处不超过3处
如下图代码中:(改动点总计6处代码即可运行)

改动点和改动详细说明都已标注在代码中
RF_NSGA3(随机森林结合多目标遗传算法3)的帕累托前沿图:
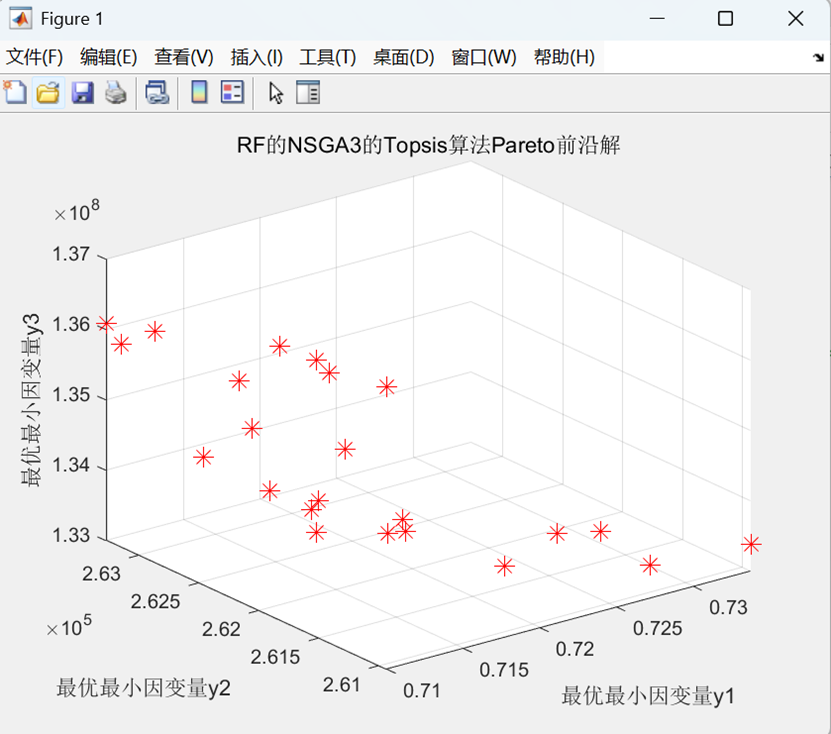
代码整体运行图如下图:
RF_NSGA3_topsis的整体寻优结果(命令行窗口截图如下:)

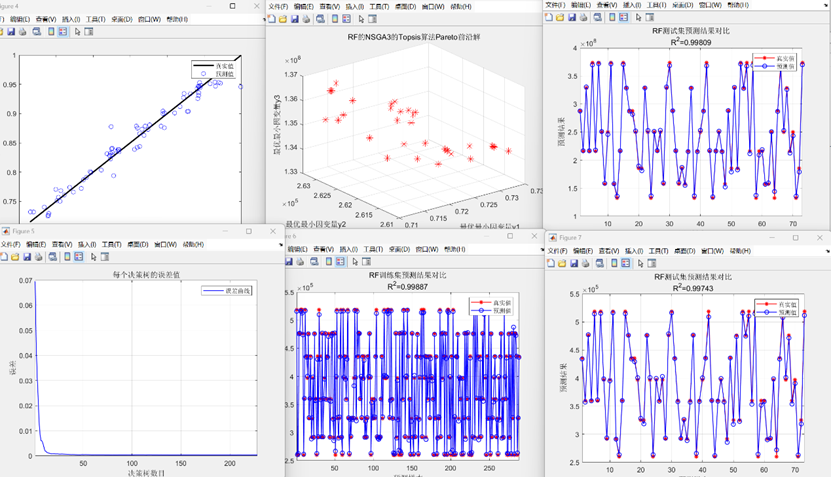
RF随机森林回归预测的误差指标如下图(三输出为例)

Topsis求解帕累托前沿解各解的接近度结果如下:

RF随机森林回归预测模型的整体运行效果图(三输出为例)
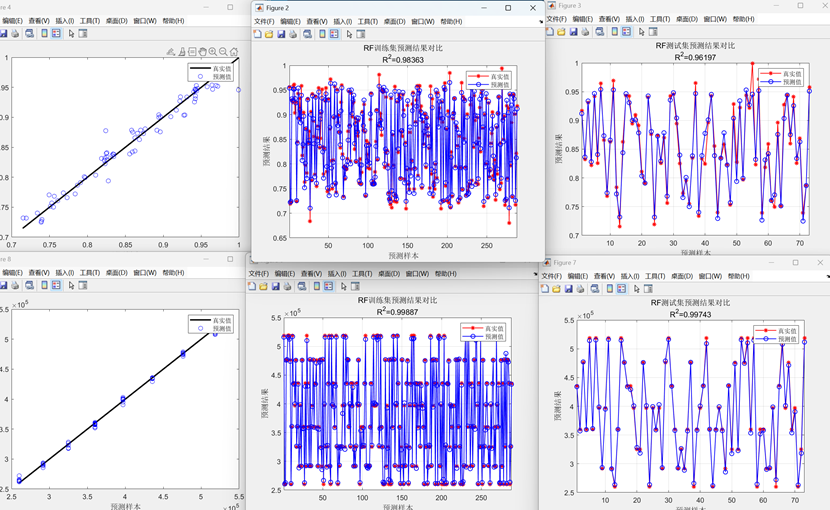
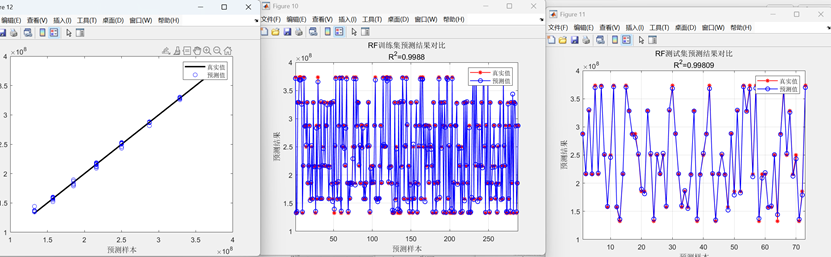
采用的数据集如下:
4输入2输出.xlsx如下:
4输入3输出.xlsx如下:
5输入3输出如下:

首先,Topsis,也就是逼近理想解排序法,是一种多准则决策分析方法。它的基本思想是通过计算各方案与理想解(正理想解)和负理想解之间的距离来进行排序。理想解是各指标的最优值,负理想解是各指标的最劣值。然后根据相对接近度来排序,相对接近度越高,方案越优。
然后是熵权法,这是一种客观赋权方法,用于确定各指标的权重。熵原本是热力学中的概念,后来在信息论中用于衡量信息的不确定性。熵权法通过计算各指标的熵值来判断该指标的离散程度,离散程度越大,熵值越小,信息量越大,权重也就越高。反之,离散程度越小,熵值越大,权重越低。
Topsis 熵权法是指在 Topsis 中使用熵权法来确定各指标的权重,而不是主观赋权。这样可以让权重的确定更客观,减少主观因素的影响。
Topsis 熵权法是一种结合了逼近理想解排序法(Topsis)和熵权法的多准则决策分析方法,主要用于解决多指标评价问题。其核心思想是通过熵权法客观确定指标权重,再利用 Topsis 对方案进行排序。
原理如下:
包括数据标准化、熵权计算、加权矩阵构建、理想解确定、距离计算和排序
1. 数据标准化

2. 熵权法计算指标权重
熵权法通过指标的信息量客观确定权重,步骤如下:


3. 构建加权标准化矩阵

4. 确定正理想解和负理想解

