2noise团队开源ChatTTS,支持多语言、流式合成、语音的情感、停顿和语调控制
简介
ChatTTS 是一个开源的文本转语音(Text-to-Speech, TTS)项目,由 2noise 团队开发,专门为对话场景设计。它在 GitHub 上广受欢迎,因其自然流畅的语音合成能力和多功能性而备受关注。
项目背景
-
目标:设计初衷是为大语言模型(LLM)助手等对话任务提供高质量的语音生成能力,同时支持多语言和多样化的语音控制。
-
训练数据:完整版模型基于超过 10 万小时的中英文语音数据训练,开源版本则使用了 40,000 小时的预训练数据(未经过特定微调,SFT)。
-
许可:代码采用 AGPLv3+ 许可证,模型采用 CC BY-NC 4.0 许可证,仅限学术研究和非商业用途。
技术特点
ChatTTS 在开源 TTS 领域表现出色,尤其在韵律(prosody)和对话自然度上超越了许多同类模型。
-
多语言支持:支持中文和英文,能够处理混合语言输入(例如中英文混杂的句子),适合多语言对话场景。
-
生成式架构:基于生成式模型(可能结合 Transformer 和 VAE),支持端到端的语音合成,生成自然且富有表现力的语音。
-
细粒度控制:
** 支持特殊标记(如 [laugh] 表示笑声、[uv_break] 表示停顿、[oral_2] 表示口语化语气),用户可手动调整语音的情感、停顿和语调。
** 提供词级和句级的控制选项,例如调整语速、音色温度(temperature)和采样参数(top_K、top_P)。 -
零样本能力:通过随机采样音色(sample_random_speaker),可以生成多样化的说话人声音,无需特定训练。
-
流式生成:支持流式音频输出,适合实时应用。
-
开源资源:提供 40,000 小时预训练模型和音色统计文件(spk_stats),便于开发者进一步研究和优化。
安装与使用
环境要求
-
Python 3.11+,依赖 PyTorch、torchaudio 等库。
-
建议使用 GPU,至少 4GB 显存(生成 30 秒音频的最低要求),如 RTX 4090 可达 7 个语义 token/秒。
安装步骤
git clone https://github.com/2noise/ChatTTS
cd ChatTTS
conda create -n chattts python=3.11
conda activate chattts
pip install -r requirements.txt```
### 基本使用示例
```python
###################################
# Sample a speaker from Gaussian.
rand_spk = chat.sample_random_speaker()
print(rand_spk) # save it for later timbre recovery
params_infer_code = ChatTTS.Chat.InferCodeParams(
spk_emb = rand_spk, # add sampled speaker
temperature = .3, # using custom temperature
top_P = 0.7, # top P decode
top_K = 20, # top K decode
)
###################################
# For sentence level manual control.
# use oral_(0-9), laugh_(0-2), break_(0-7)
# to generate special token in text to synthesize.
params_refine_text = ChatTTS.Chat.RefineTextParams(
prompt='[oral_2][laugh_0][break_6]',
)
wavs = chat.infer(
texts,
params_refine_text=params_refine_text,
params_infer_code=params_infer_code,
)
###################################
# For word level manual control.
text = 'What is [uv_break]your favorite english food?[laugh][lbreak]'
wavs = chat.infer(text, skip_refine_text=True, params_refine_text=params_refine_text, params_infer_code=params_infer_code)
"""
In some versions of torchaudio, the first line works but in other versions, so does the second line.
"""
try:
torchaudio.save("word_level_output.wav", torch.from_numpy(wavs[0]).unsqueeze(0), 24000)
except:
torchaudio.save("word_level_output.wav", torch.from_numpy(wavs[0]), 24000)
应用场景
-
对话助手:为 LLM(如 ChatGPT)提供语音输出,增强交互体验。
-
教育与培训:生成自然语音用于语言学习或课程内容。
-
内容创作:用于视频配音、播 播客或有声书的语音合成。
-
研究:学术研究人员可利用其开源模型探索 TTS 技术。
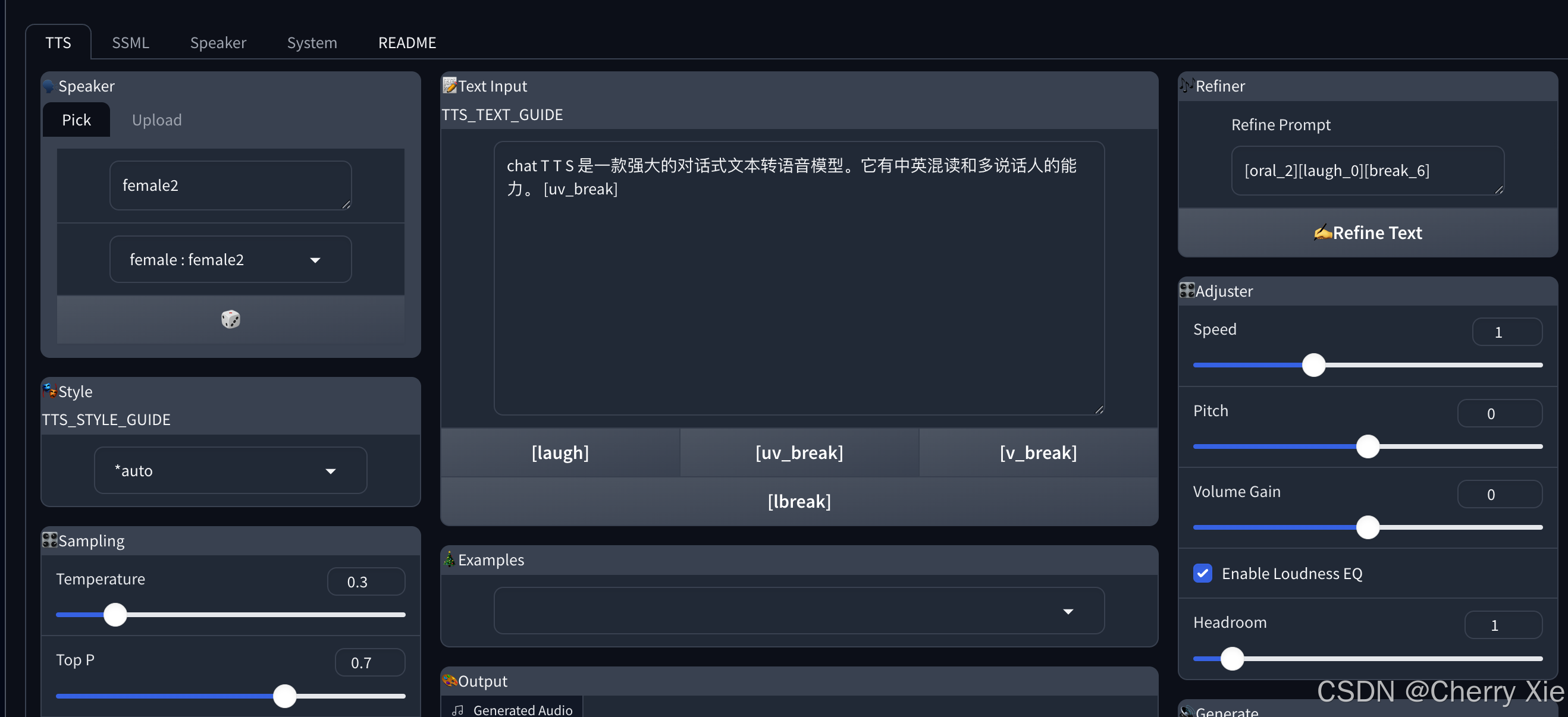
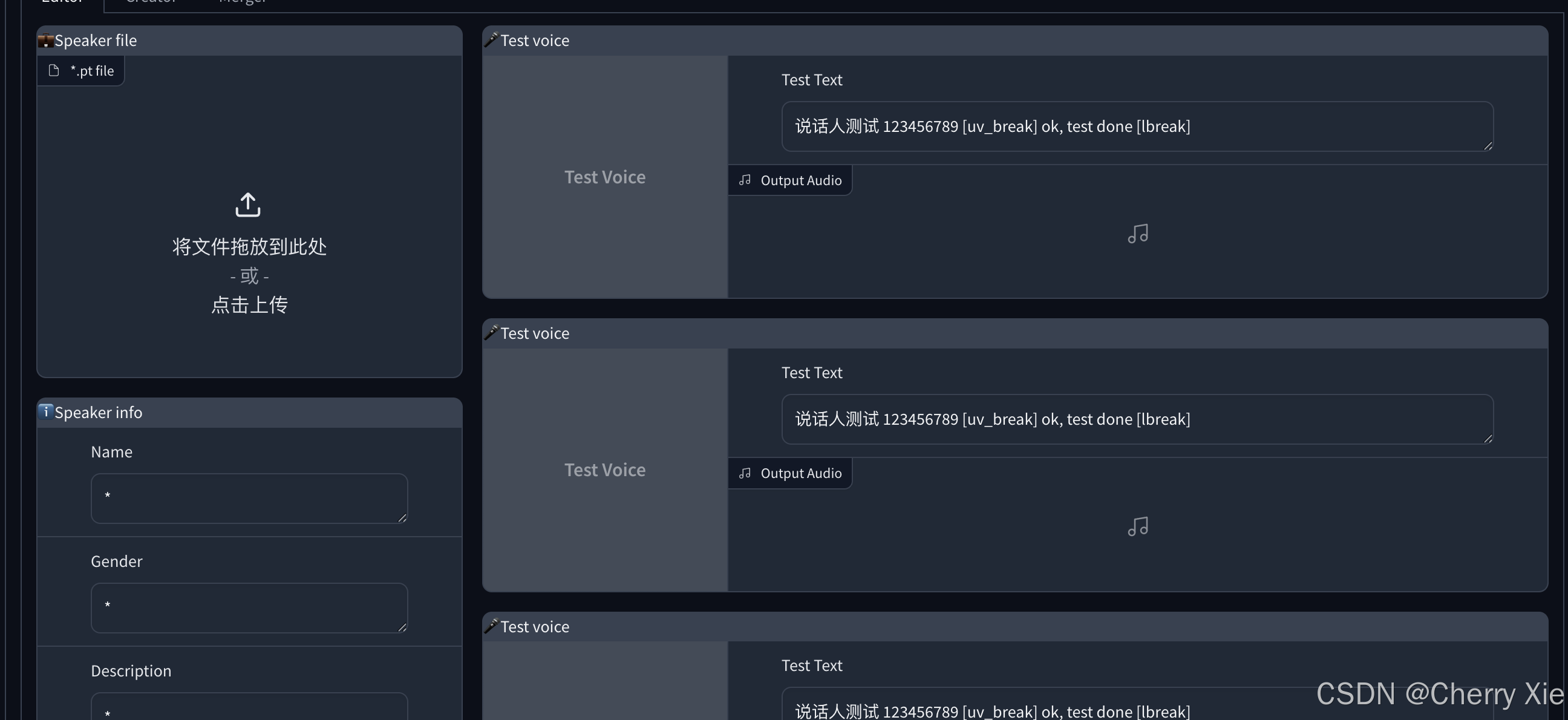
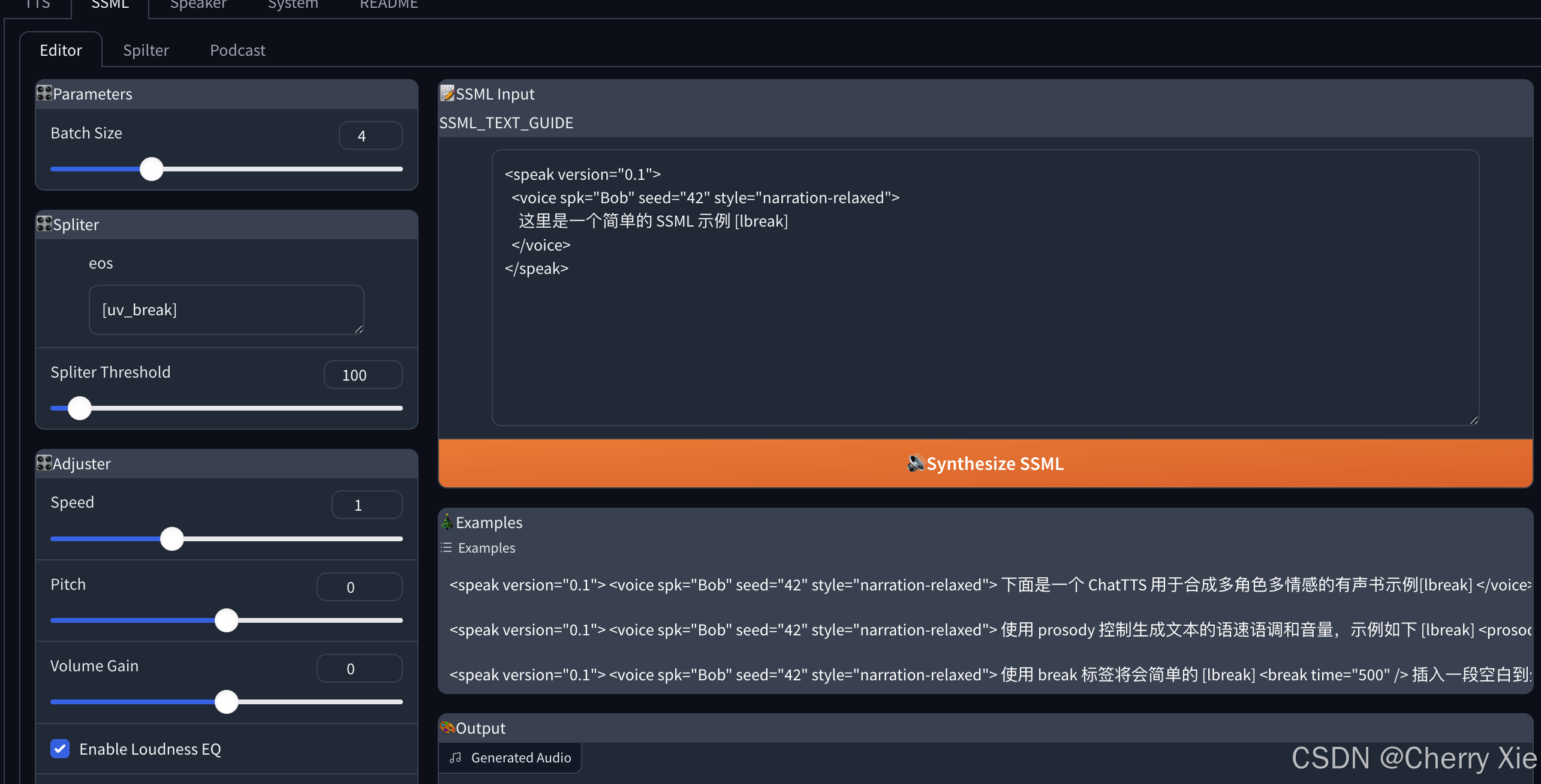
看看效果
相关文献
在线体验地址:https://chattts.com/zh?__theme=dark
github地址:https://github.com/2noise/ChatTTS/tree/main