自动驾驶---苹果又要造车了吗?
1 背景
巴菲特一直认为造车的企业是一个做 “苦生意” 的企业,可能苹果高层也意识到了这一点, 于是造车计划在去年被终止。
但2025年2月份,苹果公司署名发了一篇自动驾驶领域的论文《Robust Autonomy Emerges from Self-Play》,详细阐述了如何通过自我对弈(self-play)来训练自动驾驶系统,从而使其在没有人工数据的情况下表现出强大的鲁棒性和自主性。

2 论文工作
首先给各位读者朋友阐述自我博弈的概念,自我博弈有点类似中国武侠小说《神雕侠侣》中周伯通的技能----“双手左右互搏”。自我博弈主要应用在强化学习领域,特别是在AlphaGo等棋类游戏中。
2.1 自我博弈
自我对弈是一种强化学习(Reinforcement Learning)方法,智能体通过与自己(或克隆版本)反复对抗来提升策略。经典案例如:
- AlphaZero:通过自我博弈学习围棋、国际象棋和将棋,无需人类数据。
- OpenAI Five:Dota 2 AI通过自我博弈训练团队协作。
在论文中,作者的目标是将这一方法应用于自动驾驶系统的训练,旨在通过模拟环境中的自我对弈,训练一个无需人工数据的自动驾驶策略。该方法的核心假设是:通过模拟环境进行大规模的自我对弈,智能体能够学会如何应对复杂的现实环境中的多种驾驶场景。
2.2 未来应用
开篇作者讲述了AlphaGo在围棋领域的成功应用,以及如何将类似的自我对弈机制应用于不同的复杂任务中。与自动驾驶相关的研究主要集中在如何利用模拟器进行训练,以及如何借助大规模数据进行无监督学习或自我学习。
这一工作主要可以用于自动驾驶场景的生成:10天可以生成16亿公里的模拟数据,每百万公里的费用不足5美元,大大降低World Model的成本。苹果将该成果放在CARLA,nuPlan以及Waymo开放数据集上进行零样本独立测试,均获得了SOTA表现。
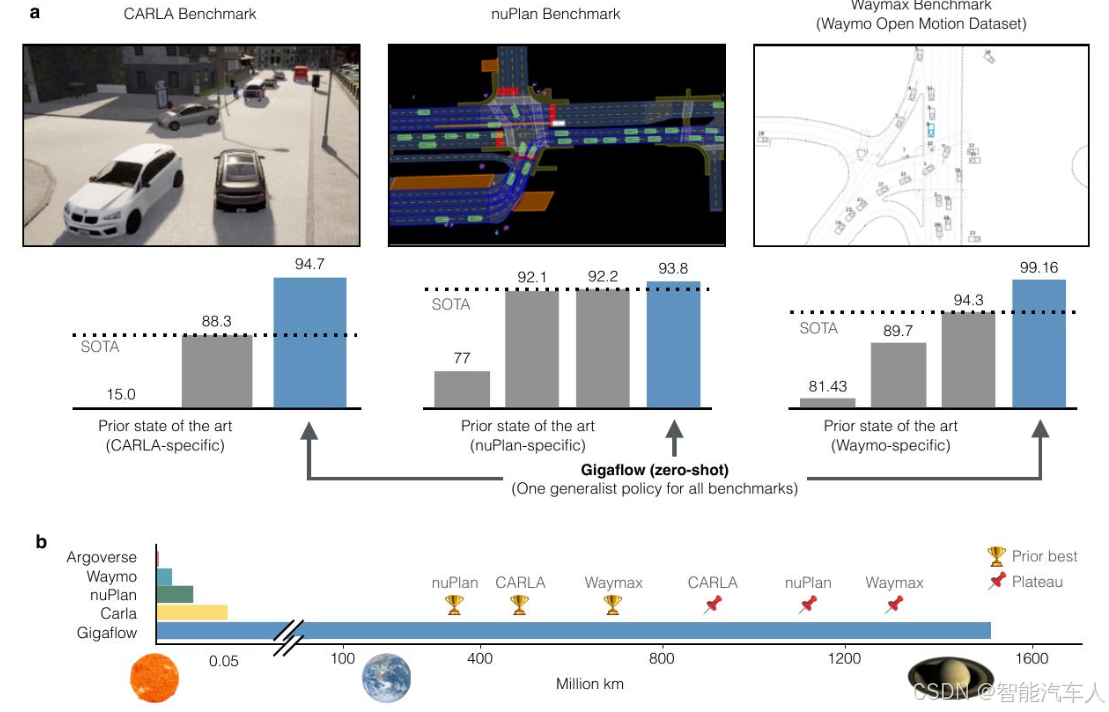
2.3 方法
在这一部分,作者介绍了他们的方法,主要包括以下几个方面:
-
模拟器开发(Gigaflow):为实现大规模训练,研究团队开发了一个名为Gigaflow的高效批量模拟器。该模拟器可以在单个8-GPU节点上每小时合成和训练相当于42年的驾驶经验。
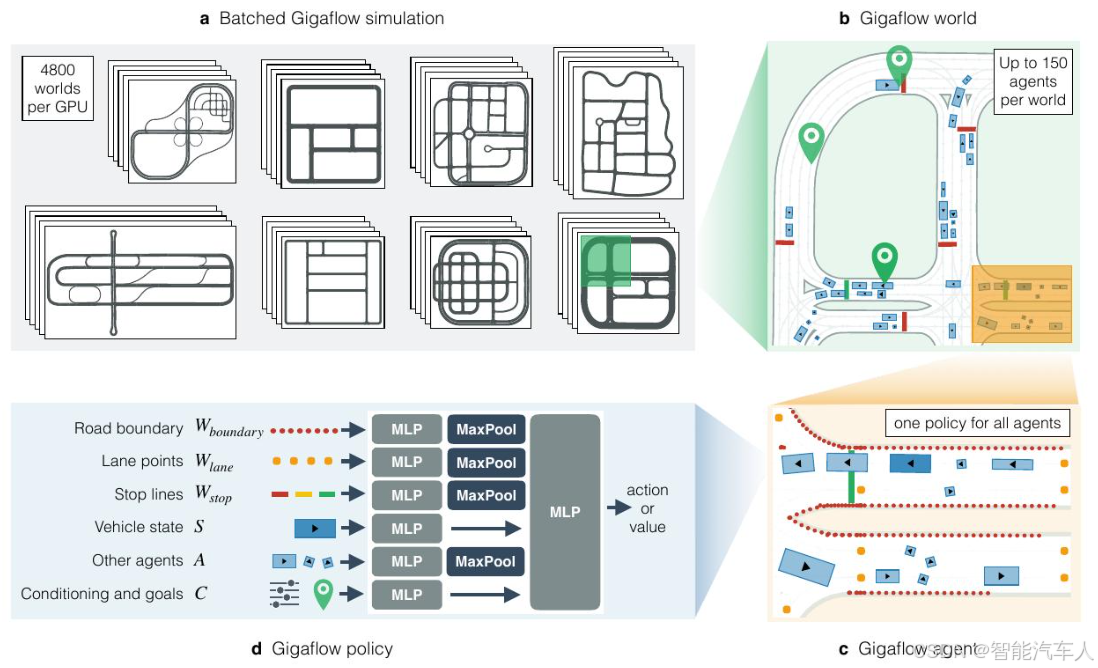
-
a. GIGAFLOW在大规模并行的自博弈强化学习设置中,模拟数万个虚拟世界,其中包含数百万个智能体;
-
b. 每个虚拟世界要求智能体在地图上导航至目标位置,且不能发生碰撞;
-
c. 每个智能体在给定的一组局部观测信息的情况下,优化自身的表现;
-
d. 所有智能体都使用一个紧凑的共享策略网络。
-
-
自我对弈训练:通过让自动驾驶系统与自己进行对弈,即在没有人类驾驶数据的情况下进行训练,研究人员能够大规模地生成各种驾驶场景,促使智能体学习如何应对不同的驾驶任务。
-
奖励和目标函数:为了确保自我对弈过程中的学习有效,作者设计了奖励函数,重点奖励在复杂的交通情境中做出正确决策的智能体行为,其中奖励项包括到达目标,避免碰撞,居中行驶和车道对齐等,处罚项包括闯红灯,偏离道路等。
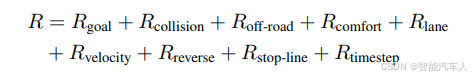
2.4 实验设计
本章节详细介绍了实验的设置,包括模拟环境的构建和实验的具体细节:
-
环境设置:为了评估训练效果,作者在模拟环境中设立了多个基准测试,模拟了不同的驾驶场景,例如城市道路、高速公路等,以确保训练的全面性。
-
自我对弈的规模和时长:研究人员通过让多个智能体同时进行自我对弈,从而在短时间内生成大量的训练数据。总计训练的模拟时间达到16亿公里的驾驶经验,相当于人类驾驶员的42年经验。
-
训练过程:每个智能体在模拟环境中进行反复训练,逐步提高其驾驶策略,以应对更复杂的交通情况和驾驶任务。
2.5 结果
这一部分详细展示了实验结果和讨论,并进行了对比分析:
-
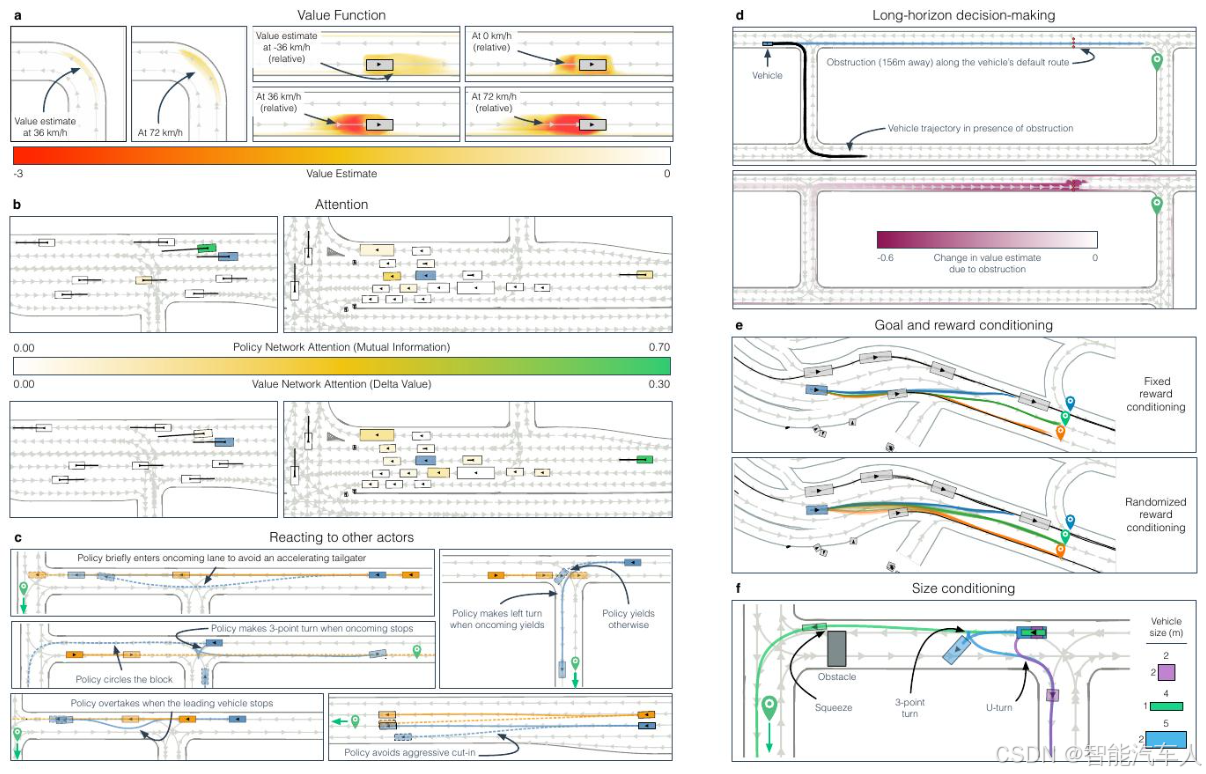
性能评估:训练后的策略在三个独立的自动驾驶基准测试中表现出色,超越了现有的最先进技术水平。此外,研究还通过与人类驾驶员的实际场景对比,验证了自我对弈策略的优越性。
-
鲁棒性测试:在多种不同的驾驶环境中,训练后的自动驾驶系统表现出极高的鲁棒性,能够有效应对突发的交通状况和复杂的驾驶场景。统计数据显示,在每17.5年的连续驾驶中,发生一次交通事故,表现出极低的事故率。
-
零-shot学习:一个显著的结果是,训练的模型完全没有依赖任何人工驾驶数据,所有训练数据都是通过自我对弈生成的,这展示了自我对弈策略的强大能力,能够在不同的驾驶场景中无缝适应。
同时对实验结果进行了深入讨论,探讨了该方法的潜力和局限性:
-
自我对弈的优势:自我对弈能够大规模生成多样化的训练数据,智能体在模拟环境中的持续学习,使得其能够逐步改进策略,增强系统的鲁棒性和自主性。
-
局限性与挑战:尽管自我对弈有许多优点,但其训练过程仍然需要大量计算资源,且在实际道路测试中可能会遇到一些不可预见的复杂情况。因此,如何将该方法与真实数据结合,进一步提高其在复杂环境中的表现,仍然是未来研究的一个方向。
3 结论及展望
研究表明,通过自我对弈训练,自动驾驶系统能够在没有人工数据的情况下实现高效、鲁棒的驾驶能力。这为未来的自动驾驶技术提供了新的研究思路,尤其是在不依赖人类驾驶数据的情况下进行大规模训练,说明自我对弈在自动驾驶系统中的巨大潜力。
尽管自我对弈方法已取得显著进展,但仍有多个方面需要进一步探索:
-
更高效的训练算法:如何进一步提高训练效率,减少对计算资源的需求,是未来工作的一个重要方向。
-
与真实数据的融合:为了进一步提高系统的实用性,未来的工作可以探索如何将自我对弈和真实驾驶数据相结合,以提高模型在实际环境中的表现。