题目练习之map的奇妙使用

♥♥♥~~~~~~欢迎光临知星小度博客空间~~~~~~♥♥♥
♥♥♥零星地变得优秀~也能拼凑出星河~♥♥♥
♥♥♥我们一起努力成为更好的自己~♥♥♥
♥♥♥如果这一篇博客对你有帮助~别忘了点赞分享哦~♥♥♥
♥♥♥如果有什么问题可以评论区留言或者私信我哦~♥♥♥
✨✨✨✨✨✨ 个人主页✨✨✨✨✨✨
前面我们已经学习了一种新的容器map和set,这一篇博客我们来看看如何使用map和set在我们的算法题目中大放光彩,准备好了吗~我们发车去探索C++的奥秘啦~🚗🚗🚗🚗🚗🚗
目录
仿函数
前面K个高频单词
解法一:仿函数+排序
解法二:map和multimap的极致使用
单词识别
随机链表的复制
仿函数
在正式开始题目练习之前,我们首先来看看仿函数的概念,在后面我们会进行使用~
仿函数(Functor)是C++中的一种设计模式,通过将函数功能封装在类中并重载
operator()实现。它使得类对象可以像函数一样被调用,兼具函数的灵活性与类的封装性。仿函数能够包含状态信息,在多次调用间保持特定状态,适用于需要自定义行为或优化性能的场合。本质上仿函数是实现了一个重载了[ ]的类~
我们可以来看看下面的代码:
//定义一个仿函数,实现两个整数加法
class Add
{
public:
int operator()(int a, int b)
{
return a + b;
}
};
int main()
{
Add add;
cout << add(4, 6) << endl;
return 0;
}有了这样一个仿函数,我们就可以像函数调用一样,使用一个类对象,通过仿函数,可以定义自定义的比较、排序、查找等行为~
再比如下面的代码(我们希望使用算法库里面的sort来实现降序,但是算法库默认是升序的,这个时候我们就可以提供仿函数)
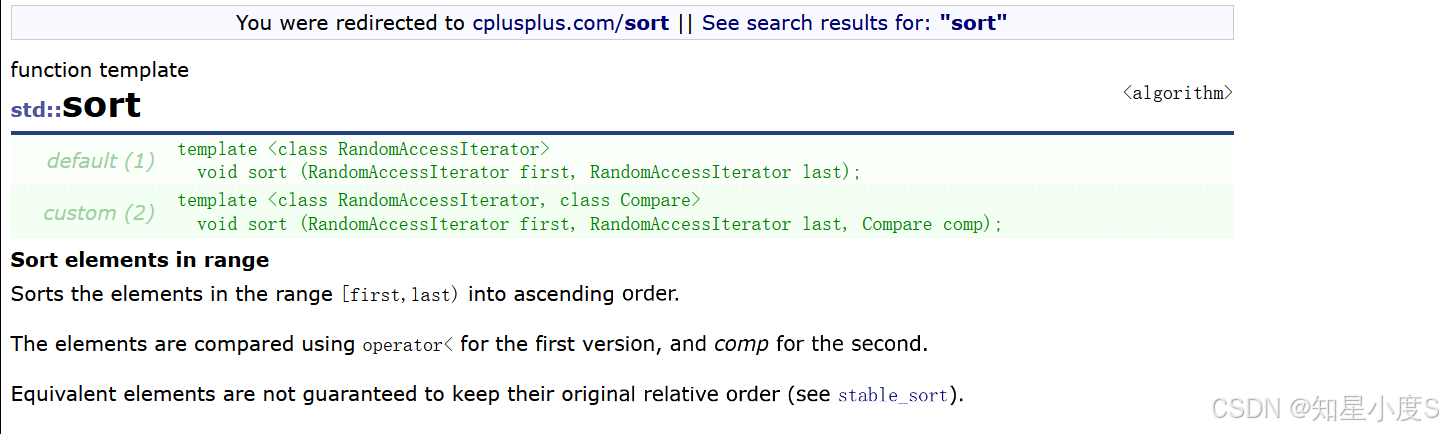
#include<algorithm>
//定义一个仿函数,进行两个整型的比较
class Compare
{
public:
bool operator()(int a, int b)
{
return a > b;//我们希望是降序,前面的大于后面的
}
};
int main()
{
vector<int> v = { 1,6,2,7,9,0,3,5 };
//算法库里面的sort默认是升序,我们可以写一个仿函数处理成降序
sort(v.begin(), v.end(), Compare());
//这里的Compare()相当于一个匿名对象
for (auto e : v)
{
cout << e << " ";
}
return 0;
}
sort在排序过程中多次调用匿名对象的operator()方法来比较元素,这样比较算法我们就可以自己定义,更加灵活~
前面K个高频单词
前面K个高频单词


解法一:仿函数+排序
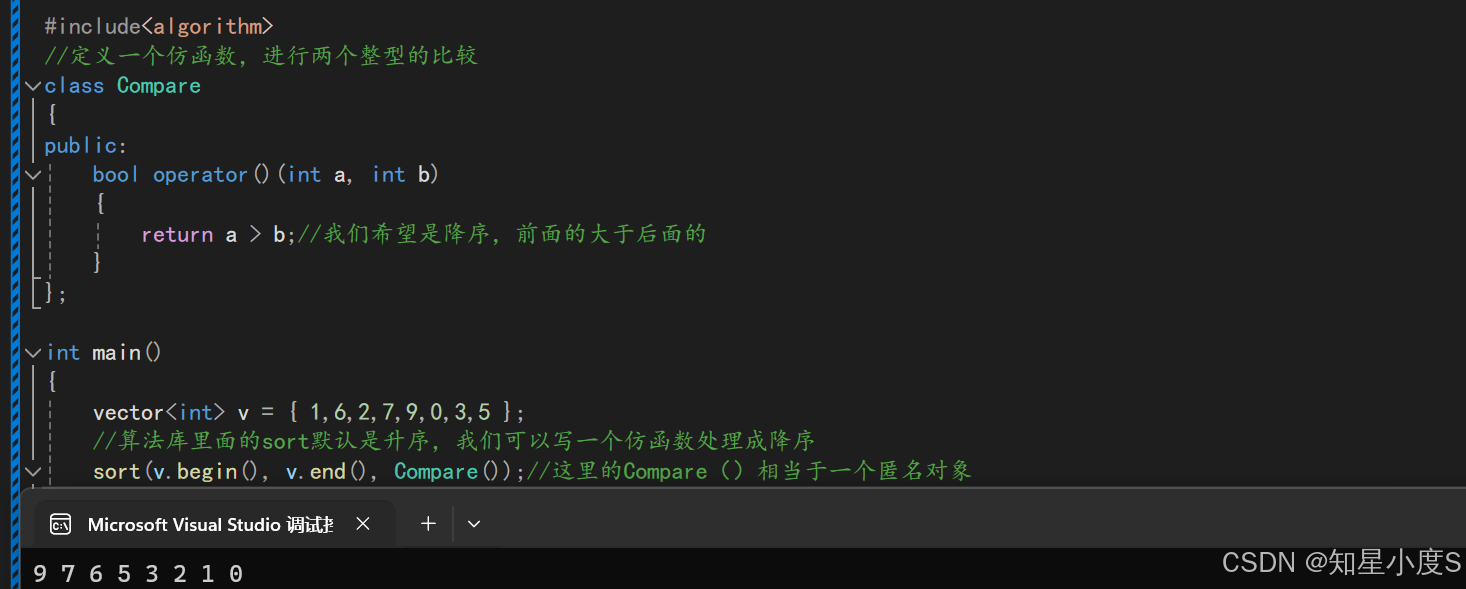
这个与我们前面的单词计数类似,但是需要注意的是这里想要的是降序,所以就需要使用到我们的仿函数~更多的注意点我们在代码中进行注释~
class Solution
{
public:
class Compare
{
public:
bool operator()(const pair<string, int>& a, const pair<string, int>& b)
{
解决方案一:控制比较逻辑
return (a.second > b.second) || (a.second == b.second && a.first < b.first);//个数相同让字典序小的在前面
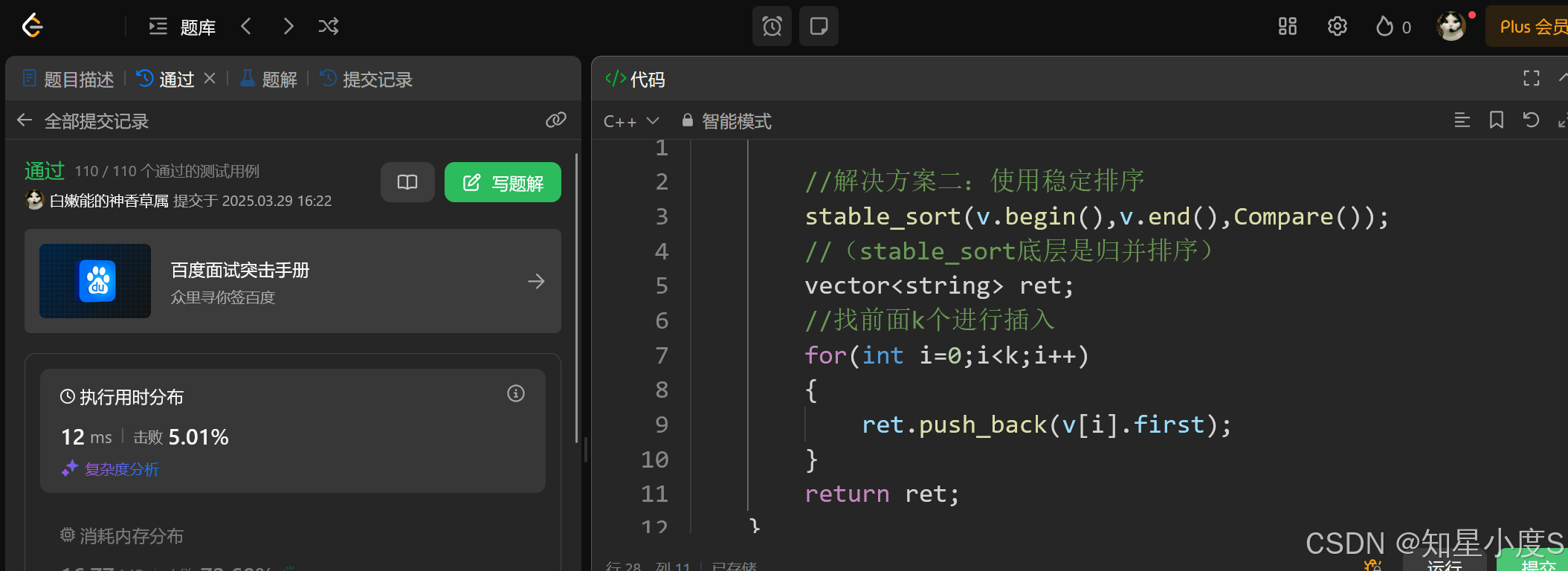
//解决方案二:使用稳定排序,不改变比较逻辑
//return a.second > b.second;//比较个数int
}
};
vector<string> topKFrequent(vector<string>& words, int k) {
map<string, int> mp;
for (auto e : words)
{
mp[e]++;
}
//sort要求随机迭代器,而map是双向迭代器
//所以需要导入vector中——支持随机迭代器
vector<pair<string, int>> v(mp.begin(), mp.end());//迭代器区间初始化
//默认是升序,我们希望是降序,并且希望按照second去排序
//提供仿函数
//sort为不稳定排序,会更改顺序与以前的一致性
//解决方案一:控制比较逻辑
sort(v.begin(), v.end(), Compare());
//解决方案二:使用稳定排序
//stable_sort(v.begin(),v.end(),Compare());
//(stable_sort底层是归并排序)
vector<string> ret;
//找前面k个进行插入
for (int i = 0; i < k; i++)
{
ret.push_back(v[i].first);
}
return ret;
}
};
这里特别注意的是sort是不稳定排序(底层是快速排序),当两个元素的值相等时,排序后它们的相对顺序可能会发生改变,最开始map排序好的字典序又会发生变化~
这里有两种解决方案:
1、控制排序逻辑(当个数相等时,让字典序小的在前面)
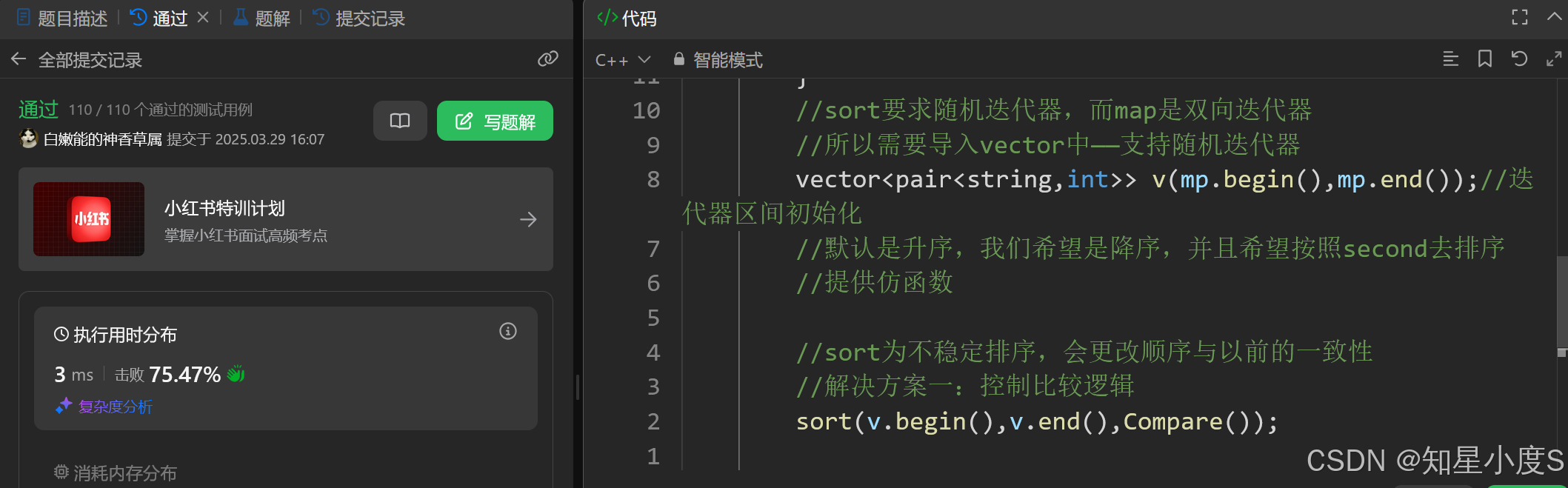
class Compare { public: bool operator()(const pair<string, int>& a, const pair<string, int>& b) { 解决方案一:控制比较逻辑 return (a.second > b.second) || (a.second == b.second && a.first < b.first);//个数相同让字典序小的在前面 } };
2、不对排序逻辑进行修改,使用稳定的排序,库里面提供了stable_sort可以帮助我们实现,底层事实上是归并排序~
解法二:map和multimap的极致使用
如果并不想写仿函数,有没有什么方法呢?也是有的,我们可以再使用一个multimap来进行对个数进行排序,需要注意的是这里不可以使用map了,因为不同字符串个数可能相等,那么map不支持key冗余就麻烦了~
class Solution
{
public:
vector<string> topKFrequent(vector<string>& words, int k) {
//map统计个数
map<string, int> count_map;
for (auto e : words)
{
count_map[e]++;
}
//multimap对个数进行排序
//修改第三个参数,我们希望按照降序排序
multimap<int, string, greater<int>> sort_map;
//写法一
auto it = count_map.begin();
while (it != count_map.end())
{
sort_map.insert({ it->second,it->first });
it++;
}
//写法二
/*
for(auto e: count_map)
{
sort_map.insert({e.second,e.first});
}
*/
vector<string> ret;
//不可以使用前面的it,类型是不一样的
auto itt = sort_map.begin();
//取前面k个
while (k--)
{
ret.push_back(itt->second);
itt++;
}
return ret;
}
};
注意点:
1、使用multimap的时候,我们希望的是大的在前面,第三个参数需要修改为greater<int>
2、这里不会出现字典序问题,是因为如果key已经存在,新元素会被插入到所有具有相同键的元素的末尾(或根据比较器定义的顺序),就顺便解决了字典序问题~
单词识别
单词识别

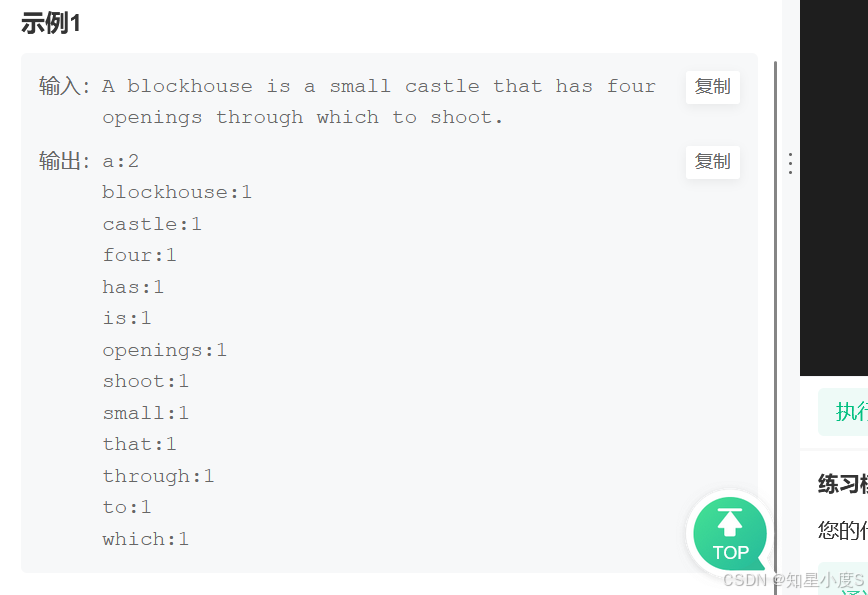
这个题目就比较温柔了,也就是我们前面的单词统计多了一些要求,我们知道使用
cin或scanf来读取输入时,它们默认会在遇到空格、制表符或换行符时停止读取。这意味着如果你直接读取一个字符串,它只会读取到第一个空格之前的内容。为了读取包含空格的整行字符串,我们可以使用getline函数,getline会读取一整行,包括空格,直到遇到换行符为止。
我们这里也可以不使用getline,直接使用while循环读取一个单词就进行处理!!!

#include <iostream>
using namespace std;
#include<map>
int main()
{
map<string,int> count_map;
string s;
while(cin>>s)
{
int n=s.size();
for(int i=0;i<n;i++)
{
//处理大小写
if(s[i]>='A'&&s[i]<='Z')
s[i]+=32;
//处理句号
if(s[i]=='.')
s.erase(i,1);//删除句号
}
count_map[s]++;
}
for(auto& e:count_map)
{
cout<<e.first<<":"<<e.second<<endl;
}
}
顺利通过,这一个题目还是比较简单的~
随机链表的复制
随机链表的复制
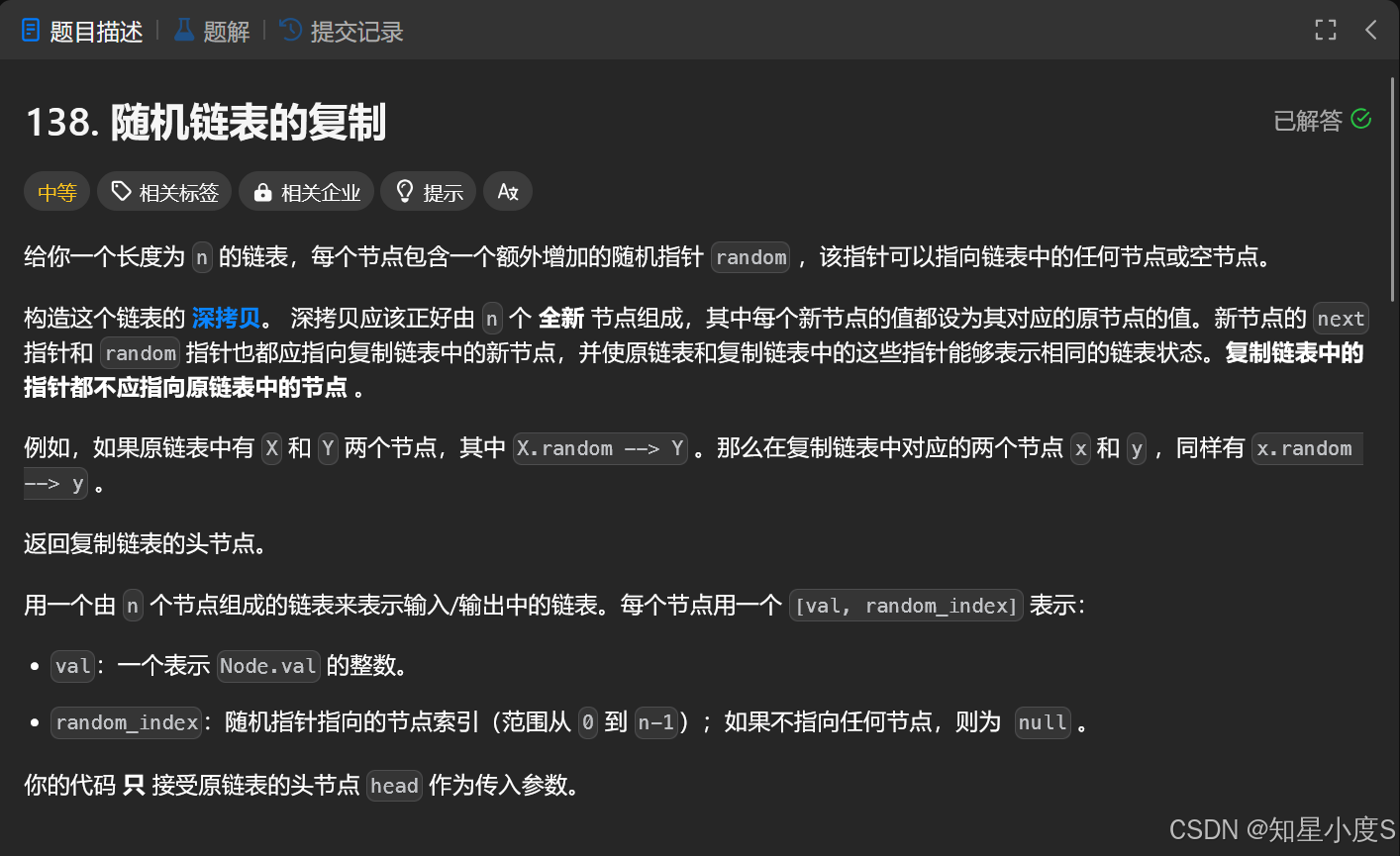
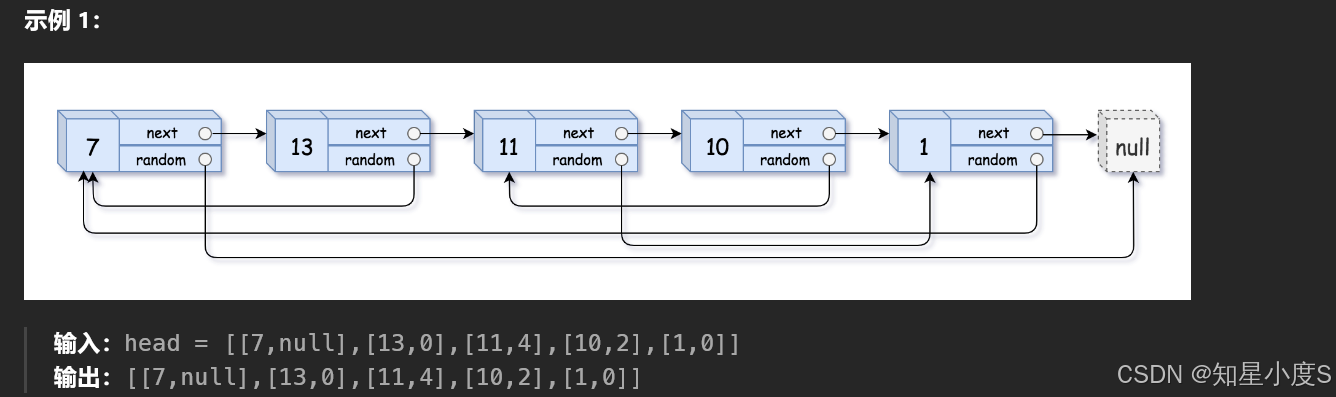
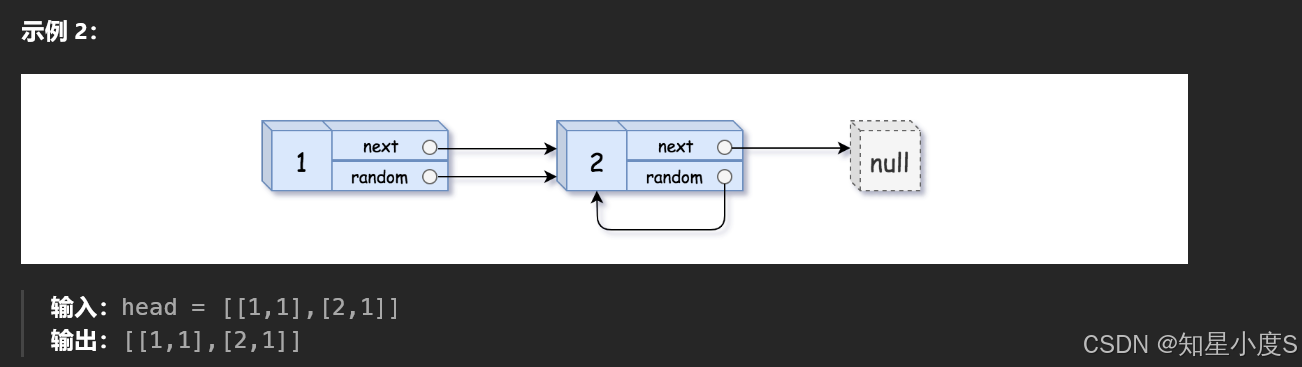

看这题目长度就知道这不是一个简单题,我们前面使用C语言写,写了一堆,具体可以看看这一篇博客题目练习之链表那些事儿(再续)
接下来我们一起来探索C++有什么奇妙的地方呢~~~
既然是是map的奇妙使用,那么一定需要就是map了,思路和前面差不多,不过有了map,代码实现就会更加简单了~
思路:
- 第一遍遍历:
- 创建一个
map来存储原节点和复制节点的映射关系。- 遍历原链表,为每个节点创建一个新的复制节点,并将其连接到复制链表中。
- 将原节点和复制节点的映射关系存储到
map中。- 第二遍遍历:
- 重新遍历原链表,根据
map中的映射关系设置复制节点的random指针。- 返回结果:
- 返回复制链表的头节点。
//随机链表的复制
/*
// Definition for a Node.
class Node {
public:
int val;
Node* next;
Node* random;
Node(int _val) {
val = _val;
next = NULL;
random = NULL;
}
};
*/
class Solution
{
public:
Node* copyRandomList(Node* head)
{
map<Node*, Node*> CopyMap;// 用于存储原节点和复制节点的映射关系
Node* newHead = nullptr;
Node* newTail = nullptr;
Node* cur = head;
// 第一遍遍历:创建复制节点并构建映射关系
while (cur)
{
// 如果复制链表为空,初始化头和尾指针
if (newHead == nullptr)
{
newHead = newTail = new Node(cur->val);
}
// 否则,创建新节点并连接到复制链表的尾部
else
{
newTail->next = new Node(cur->val);
newTail = newTail->next;
}
// 将原节点和复制节点的映射关系存储到map中
CopyMap[cur] = newTail;
//继续往后面遍历
cur = cur->next;
}
// 第二遍遍历:设置复制节点的random指针
//重新遍历原来的链表
cur = head;
//复制链表的当前结点
Node* copycur = newHead;
while (cur)
{
// 如果原节点的random指针为空,复制节点的random指针也为空
if (cur->random == nullptr)
copycur->random = nullptr;
// 否则,根据映射关系设置复制节点的random指针
else
copycur->random = CopyMap[cur->random];
cur = cur->next;
copycur = copycur->next;
}
return newHead;//返回新链表头结点
}
};
成功通过,为了更好地理解,我们举例说明:
假设原链表中有两个节点
X和Y,其中X.random -> Y。在复制链表中,我们希望对应的两个节点x'和y'也有x'.random -> y'。
- 在第一遍遍历中,我们创建了
x'和y',并将X映射到x',Y映射到y'存储在nodeMap中。- 在第二遍遍历中,当处理节点
X时,cur->random是Y,我们通过nodeMap[Y]找到y',然后将x'.random设置为y'。这样,我们就正确地设置了复制链表中节点的
random指针~
有了map我们就不需要手动去进行链接,方便了不少~
♥♥♥本篇博客内容结束,期待与各位优秀程序员交流,有什么问题请私信♥♥♥
♥♥♥如果这一篇博客对你有帮助~别忘了点赞分享哦~♥♥♥
✨✨✨✨✨✨个人主页✨✨✨✨✨✨