【Project】高并发内存池
目录
什么是内存池
整体框架
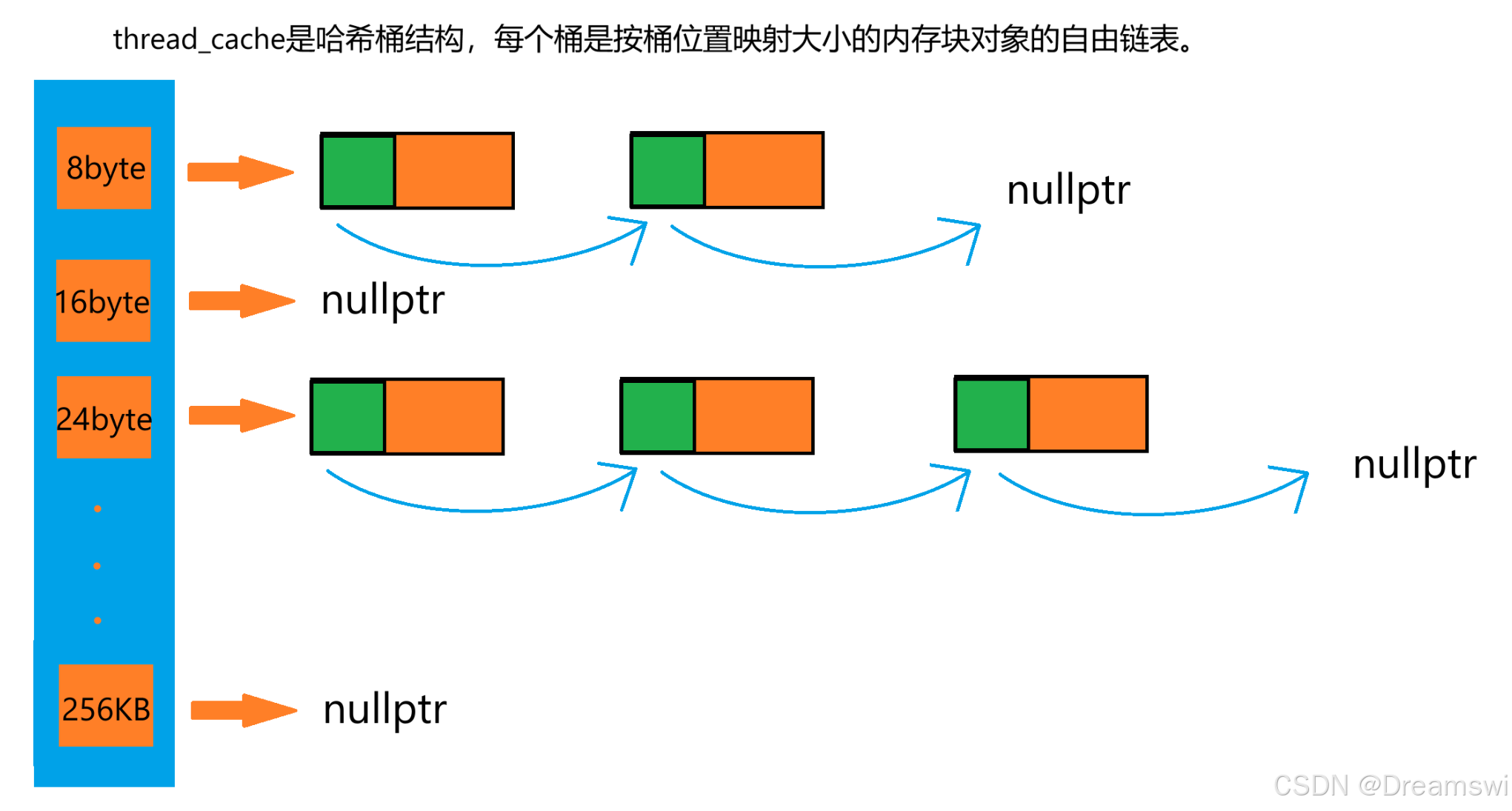
thread_cache
内存对象大小的对齐映射规则
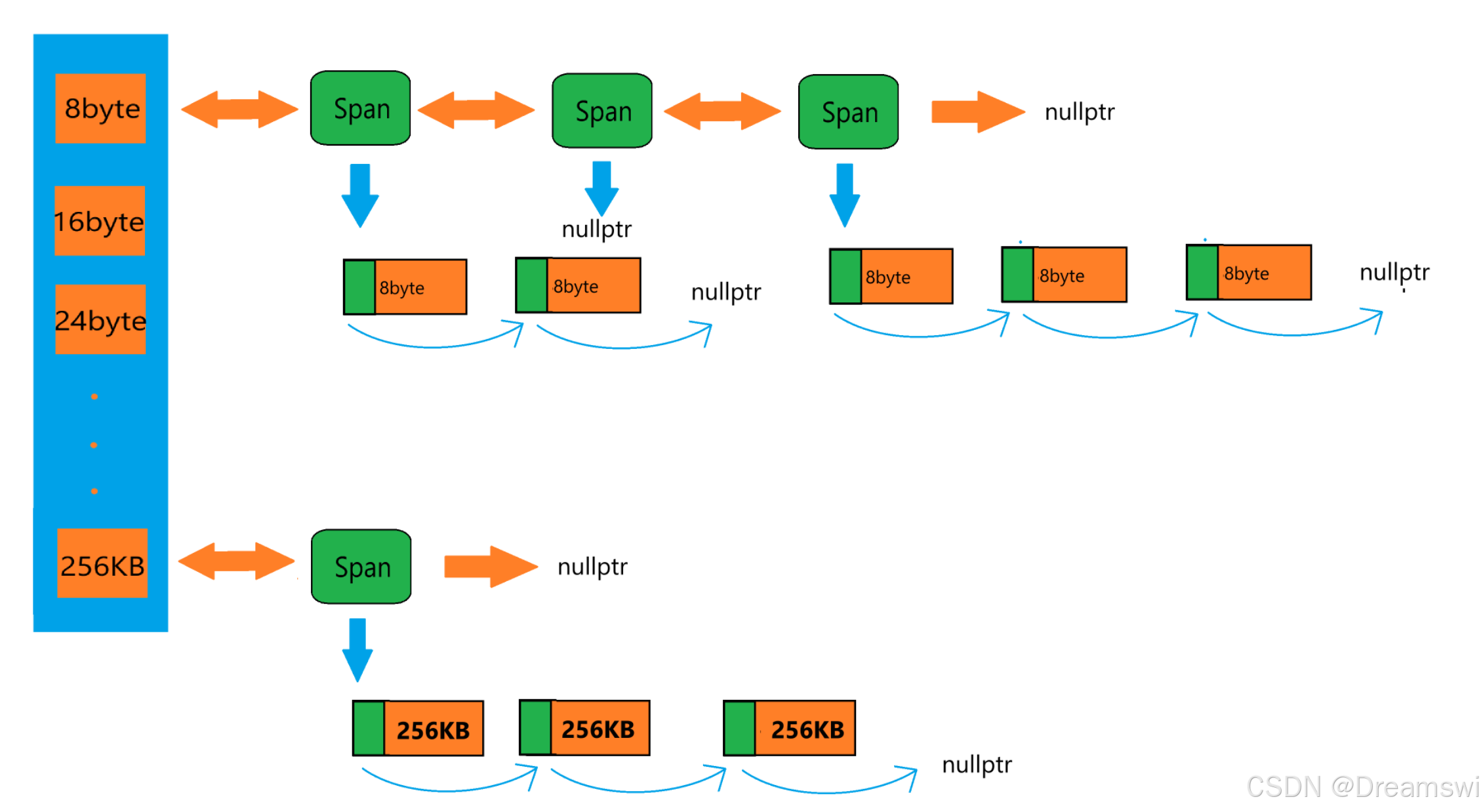
central_cache
申请内存
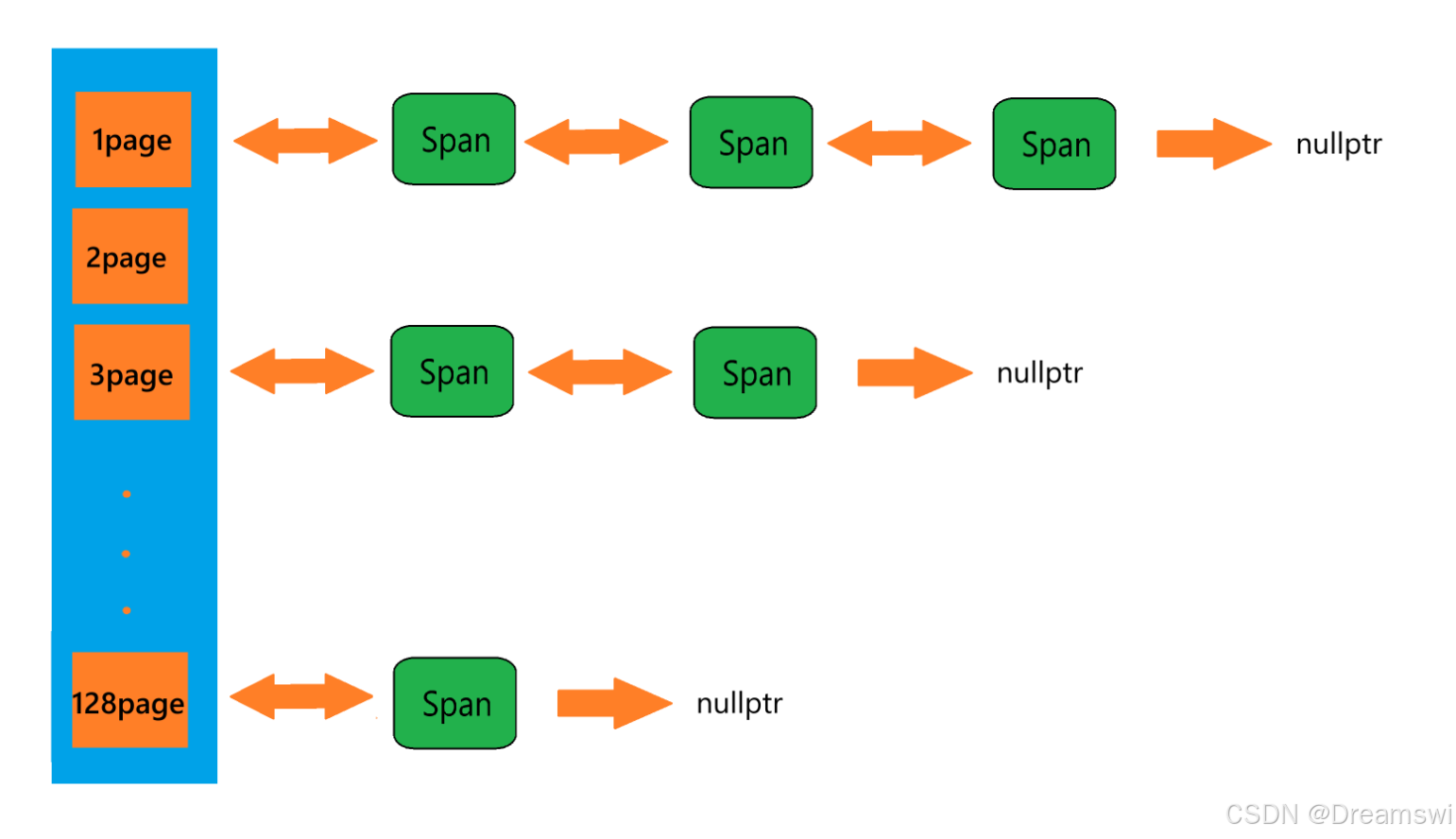
page_cache
申请内存
完整代码
什么是内存池
内存池是指程序预先从系统处申请一份足够大的内存,当程序需要内存时不去找系统申请而是找内存池申请内存。像这样向系统申请过量资源然后自己管理的方式被称为池化技术。因为申请资源都有较大的开销,而池化技术能大大减少这些开销。我们常用的malloc也是一个内存池。
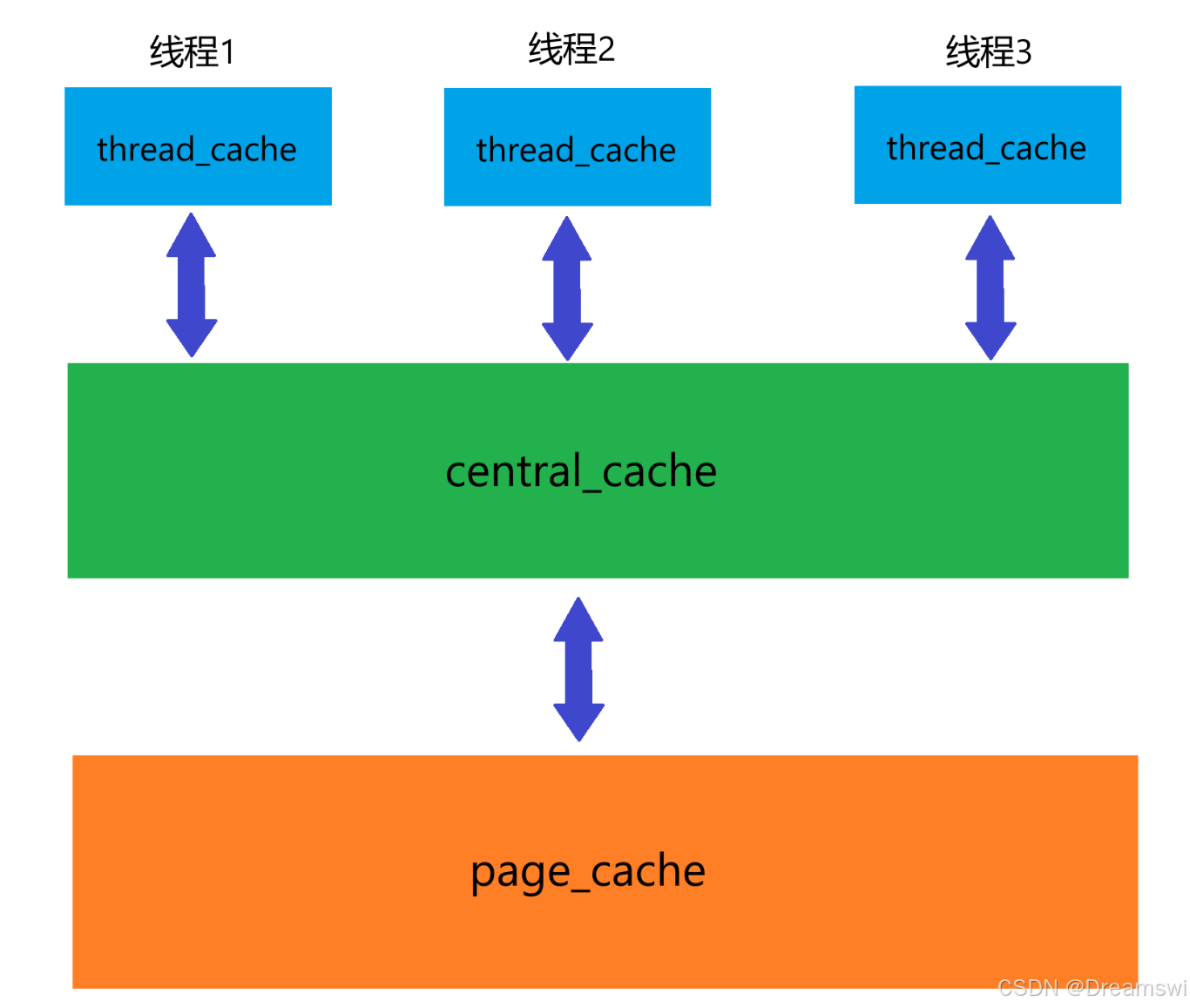
整体框架
- thread_cache:线程缓存是每个线程独有的,用于分配小于256KB,访问时不需要加锁,也是该线程池高效的地方。
- central_cache:中心缓存是所有线程共享的,thread_cache需要按需向central_cache申请对象。同时central_cache会在合适的时候回收thread_cache中的对象。访问时需要加桶锁,但因为只有thread_cache没有内存才会来访问,所以锁竞争不会非常激烈。
- page_cache:页缓存是中心缓存之上的一层缓存,按页存储或分配,当central_cache没有内存对象时向page_cache申请,page_cache会分配一定数量的页并切割成定长内存分配给page_cache。当一个span的几个跨度页对象都回收后,page_cache会回收entral_cache中符合条件的span对象,并合并相邻页,缓解内存外碎片问题。
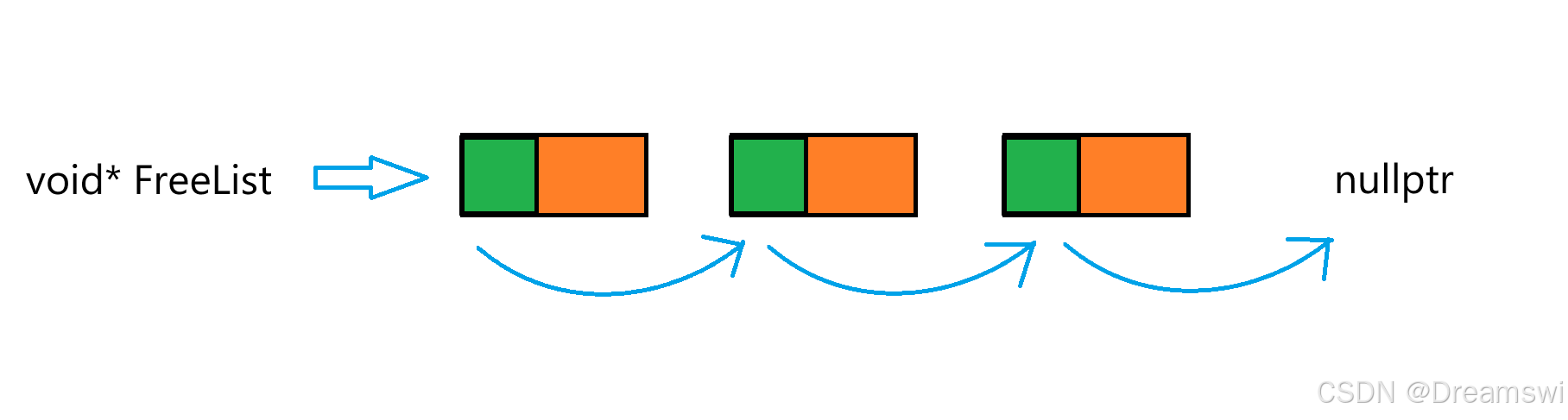
FreeList:管理切分好的小对象的自由链表。
在32/64位环境下,前4/8字节用于存储下一个切分好的小对象的地址
假设obj是一个切好的内存对象,则*(void**)obj就可以访问一个指针的内存大小。因为解引用后obj的类型为void*就是一个指针,在32/64环境下就是4/8字节。
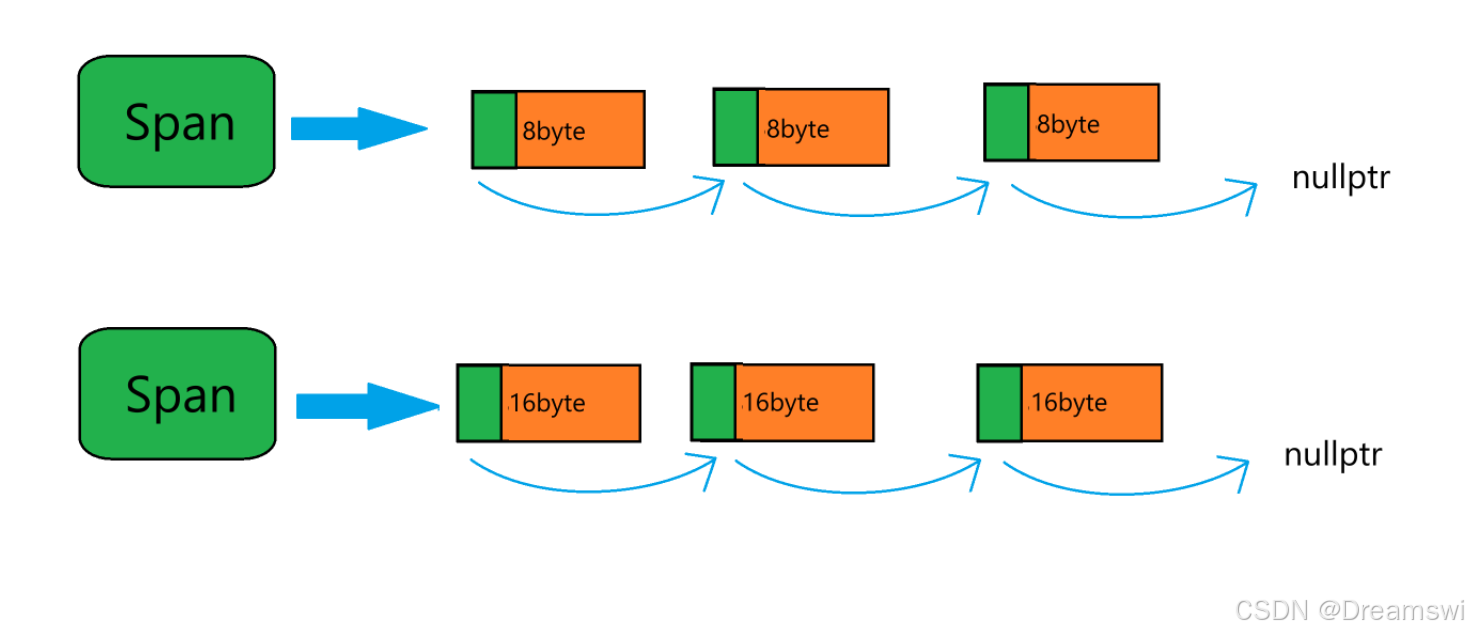
Span:管理多个连续页大块内存跨度结构。
struct Span
{
PAGE_ID _pageId = 0; //大块内存起始页的页号
size_t _n = 0; //页的数量
Span* _next = nullptr; //双向链表的结构
Span* _prev = nullptr;
size_t _objSize = 0; //切好的小对象的大小
size_t _useCount = 0; //切好小块内存,被分配给thread cache的计数
void* _freeList = nullptr; //切好的小块内存的自由链表
bool _isUse = false; //是否在被使用
};注:总大小为8byte /16byte,包括绿色存储地址的部分。
thread_cache
线程缓存要每一个线程独有,所以要使用_declspec(thread) 去声明一个ThreadCache*类型的对象。扩展的存储类属性thread,它与_declspec关键字一起用来声明一个线程本地变量。
#pragma once
#include "Common.h"
class ThreadCache
{
public:
//申请和释放内存对象
void* Allocate(size_t size);
void Deallocate(void* ptr, size_t size);
//从中心缓存获取对象
void* FetchFromCentralCache(size_t index, size_t size);
//释放对象时,链表过长时,回收内存回到中心缓存
void ListTooLong(FreeList& list, size_t size);
private:
FreeList _freeLists[NFREELIST];
};
//TLS thread local storage
//扩展的存储类属性thread,它与__declspec关键字一起用来声明一个线程本地变量。
static _declspec(thread) ThreadCache* pTLSThreadCache = nullptr;thread_cache结构:
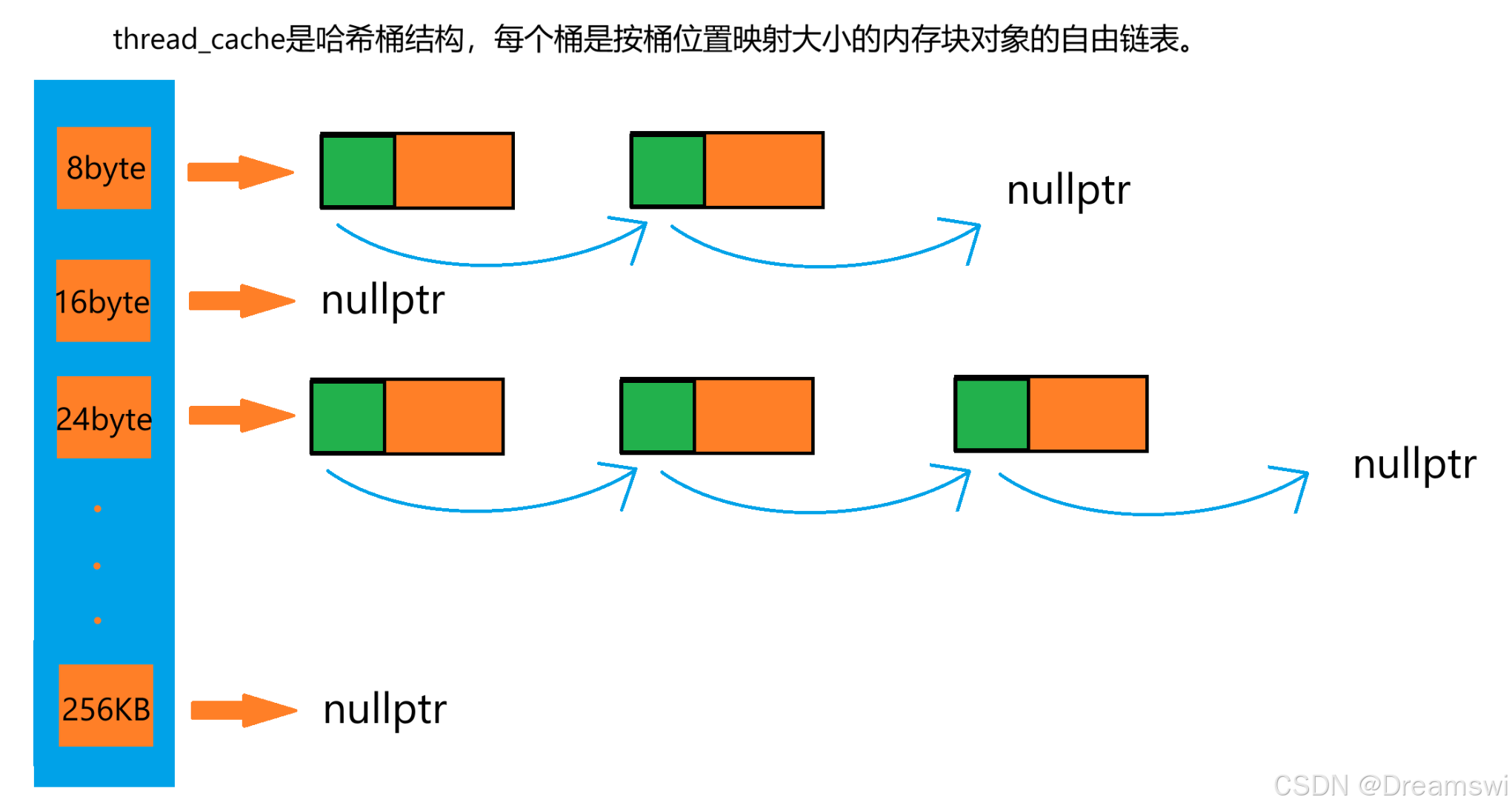
内存对象大小的对齐映射规则
ThreadCache内部有一个 FreeList _freeLists[NFREELIST] 数组,NFREELIST为208。
对齐规则如下:
【字节范围】 【对应数组的下标范围】
[1,128] 8byte对齐 freelist[0,16)
[128+1,1024] 16byte对齐 freelist[16,72)
[1024+1,8*1024] 128byte对齐 freelist[72,128)
[8*1024+1,64*1024] 1024byte对齐 freelist[128,184)
[64*1024+1,256*1024] 8*1024byte对齐 freelist[184,208)
为什么要如此对齐,假设一律以8byte进行对齐,那么256*1024字节需要256*1024除以8得32768,也就是说需要建32768个自由链表桶。这样设计还有一个好处,内存内碎片的浪费整体控制在10%左右,假设申请129字节,按照16字节对齐则分配给他144字节,其中15字节是浪费,15除以144得0.104...。
按照规则,申请0到8字节一律返回8字节大小的内存对象,则FreeList _freeLists[0] 对应8byte的桶,如此类推FreeList _freeLists[1] 对应16byte的桶,FreeList _freeLists[2] 对应24byte的桶......
为了方便转换,RoundUp函数将申请大小转换为对齐数大小,例如:0到8字节分配8字节,9到16字节分配16字节如此类推。Index函数又将对齐数大小转换为要访问的自由链表数组下标,例如:8字节则访问0号下标,16字节则访问1号下标。
static inline size_t _RoundUp(size_t bytes, size_t alignNum)
{
//& ~(alignNum - 1),使前n位为0。
//例如:对齐数为8,则使前3位为0。
//二进制中,8为1000,减一后为0111,反转则为1000
return ((bytes + alignNum - 1) & ~(alignNum - 1));
}
static inline size_t RoundUp(size_t size)
{
if (size <= 128)
{
return _RoundUp(size, 8);
}
else if (size <= 1024)
{
return _RoundUp(size, 16);
}
else if (size <= 8 * 1024)
{
return _RoundUp(size, 128);
}
else if (size <= 64 * 1024)
{
return _RoundUp(size, 1024);
}
else if (size <= 256 * 1024)
{
return _RoundUp(size, 8 * 1024);
}
else
{
return _RoundUp(size, 1 << PAGE_SHIFT);
}
}
static inline size_t _Index(size_t bytes, size_t align_shift)
{
return ((bytes + (1 << align_shift) - 1) >> align_shift) - 1;
}
//计算映射的哪一个自由链表桶
static inline size_t Index(size_t bytes)
{
assert(bytes <= MAX_BYTES);
//每个区间有多少个链
static int group_array[4] = { 16, 56, 56, 56 };
if (bytes <= 128) {
return _Index(bytes, 3);
}
else if (bytes <= 1024) {
return _Index(bytes - 128, 4) + group_array[0];
}
else if (bytes <= 8 * 1024) {
return _Index(bytes - 1024, 7) + group_array[1] + group_array[0];
}
else if (bytes <= 64 * 1024) {
return _Index(bytes - 8 * 1024, 10) + group_array[2] + group_array[1] + group_array[0];
}
else if (bytes <= 256 * 1024) {
return _Index(bytes - 64 * 1024, 13) + group_array[3] + group_array[2] + group_array[1] + group_array[0];
}
else {
assert(false);
}
return -1;
}central_cache
因为是所有线程共有的,所以采用单例模式。
#pragma once
#include "Common.h"
//单例模式
class CentralCache
{
public:
static CentralCache* GetInstance()
{
return &_sInst;
}
//获取一个非空的span
Span* GetOneSpan(SpanList& list, size_t byte_size);
//从中心缓存获取一定数量的对象给thread cache
size_t FetchRangeObj(void*& start, void*& end, size_t batchNum, size_t size);
//将一定数量的对象释放到span跨度
void ReleaseListToSpans(void* start, size_t byte_size);
private:
SpanList _spanLists[NFREELIST];
private:
CentralCache()
{}
CentralCache(const CentralCache&) = delete;
static CentralCache _sInst;
};central_cache结构:
central_cache也是哈希桶结构,但挂载的是Span链表,8byte映射位置下的Span中的页被分割成8byte大小的内存对象并使用FreeList连接起来。
申请内存
- 当thread_cache没有内存时,就会采用慢开始算法从central_cache中批量申请内存。central_cache会从SpanList中找到合适的span,从span中取内存对象给thread_cache
- 如果合适的span中没有内存对象可分配了,就需要向page_cache申请新的span对象,拿到span后按照管理的大小切好并连接成FreeList管理,再将切好的内存对象分配给thread_cache。
- 每分配一个对象,对应的span就要进行一次进行++usecount。
page_cache
#pragma once
#include "Common.h"
#include "ObjectPool.h"
#include "PageMap.h"
class PageCache
{
public:
static PageCache* GetInstance()
{
return &_sInst;
}
//获取从对象到span的映射
Span* MapObjectToSpan(void* obj);
//释放空闲span回到Pagecache,并合并相邻的span
void ReleaseSpanToPageCache(Span* span);
//获取一个K页的span
Span* NewSpan(size_t k);
std::mutex _PageMutex;
private:
PageCache()
{}
PageCache(const PageCache&) = delete;
SpanList _spanLists[NPAGES];
ObjectPool<Span> _spanPool;
TCMalloc_PageMap1<32 - PAGE_SHIFT> _idSpanMap;
static PageCache _sInst;
};page_cache结构:
page_cache是哈希桶结构,挂载的也是Span链表,但与central_cache不一样,central_cache是和thread_cache一样的大小对齐关系映射的,且挂载有切好的小内存对象。page_cache是按页数映射,且未被切成小内存对象,即一个span对象就为诺干页内存。
申请内存
- 当central_cache向page_cache申请内存时,则先去找对应页数下的桶,看看有没有Span对象,如果没有则往下查找有更大页数的桶,如果找到则将其分裂为两个。 例如:central_cache想要一个8页的span对象,但page_cache没有8页的span对象,往下查找找到了10页的span对象,那么就将该10页的span切割为2页和8页的span,将8页的span返回给central_cache,2页的span挂载回page_cache下2页的桶中。
- 如果一直查找到128页的桶都没有span对象,则使用系统调用申请一个128页的内存挂载回Span链表中,再重复步骤一。
完整代码
Project/ConcurrentMemoryPool/ConcurrentMemoryPool · swi/c++ - 码云 - 开源中国