Graph Attetion Networks
【通俗易懂-保姆级讲解图注意力网络GAT】 https://www.bilibili.com/video/BV1cr421L7Cq/?share_source=copy_web&vd_source=f00bfb41b3b450c3767070ed82f30ac8
【图神经网络系列讲解及代码实现-GAT 1】 https://www.bilibili.com/video/BV1wP411T7dr/?share_source=copy_web&vd_source=f00bfb41b3b450c3767070ed82f30ac8
简介:
时间:2018
会议:ICLR
作者:Petar Velickovic, Guillem Cucurull, Arantxa Casanova, Yoshua Bengio
摘要:
通过堆叠节点能够关注其邻域特征的层,我们能够(隐式地)为邻域中的不同节点指定不同的权重,而不需要任何类型的高成本矩阵运算(例如求逆)或依赖于预先知道的图结构。
创新点:
①在图神经网络中引入了注意力机制,使得模型能学习到邻居节点的重要性(注意力权重)
②通过注意力机制为每个节点分配权重,而不是依赖于节点度数的非参数化缩放因子
③通过并行使用多个注意力机制(头),使模型能够捕捉更复杂的关系
GAT架构:
节点i只和邻居节点做attetion计算

过程:

①计算注意力系数
逐个计算节点i与其相邻节点的注意力系数
注意力:关注的点在哪

一个点的当前情况对它的未来情况也有影响,因此也需要算本身,相关性需要算包括自己和自己的(自注意力)全部点之间的相关性
计算方法:
W:代表一个共享的线性转换层(线性矩阵,全连接层),将特征维度从变为
a:为一个函数,将多个值映射为一个值/一维
②masked attention&聚合值为“1”
已经算出每个节点和每个节点之间的注意力值,但完全不连接的需要将其注意力值置为“0”,可以和网络的邻接矩阵一对一相乘(哈达玛乘积),有连接的矩阵值为“1”,无连接的矩阵值为“0”

通过类似于掩码的形式,保留原有的形式
将进行归一化操作,映射值为
值
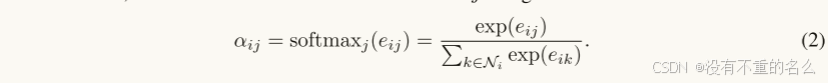
使用LeakyReLU,增加非线性,模型的学习能力

③加权求和,聚合操作
将得到的节点与邻域节点的注意力分数和value(不是原始特征h,而是成了
转换之后的)
相乘求和,做加权平均
和之前采用的值是一样的,用于减少参数量,作者认为在做特征升维降维转换时
起到的作用是一样的

④扩展机制以使用多头注意力
K个头时,当使用拼接时,得到了

或者可以采用特征求和取平均,得到

代码解析:
# -*- coding: utf-8 -*-
# @Author: 95793
# @Date: 2025/4/6 15:59
import torch
from torch import nn
import torch.nn.functional as F
class GATLayer(nn.Module):
def __init__(self, in_features, out_features, dropout, alpha, concat=True):
super(GATLayer, self).__init__()
self.in_features = in_features
self.out_features = out_features
self.dropout = dropout
self.alpha = alpha
self.W = nn.Parameter(torch.zeros(size=(in_features, out_features)))
nn.init.xavier_uniform_(self.W.data, gain=1.414)
self.a = nn.Parameter(torch.zeros(size=(2 * out_features, 1)))
nn.init.xavier_uniform_(self.a.data, gain=1.414)
self.leakeyrelu = nn.LeakyReLU(self.alpha)
def forward(self, input_h, adj):
h = torch.mm(input_h, self.W)
N = h.size()[0]
input_concat = torch.cat([h.repeat(1, N).view(N * N, -1), h.repeat(N, 1)], dim=1).\
view(N, -1, 2 * self.out_features)
e = self.leakeyrelu(torch.matmul(input_concat, self.a).squeeze(2))
zero_vec = -1e12 * torch.ones_like(e)
attention = torch.where(adj > 0, e, zero_vec)
attention = F.softmax(attention, dim=1)
attention = F.dropout(attention, self.dropout, training=self.training)
output_h = torch.matmul(attention, h)
return output_h
if __name__ == '__main__':
x = torch.randn(6, 10)
adj = torch.tensor([[1, 1, 1, 0, 0, 0],
[1, 1, 1, 0, 0, 0],
[1, 1, 1, 0, 1, 1],
[0, 0, 0, 1, 0, 1],
[0, 0, 1, 0, 1, 1],
[0, 0, 1, 1, 1, 1]], dtype=torch.float32)
my_gat = GATLayer(10, 5, 0.2, 0.2)
print(my_gat(x, adj))