爬虫练习案例
案例1:
爬取菜鸟教程左侧导航栏的分类内容:
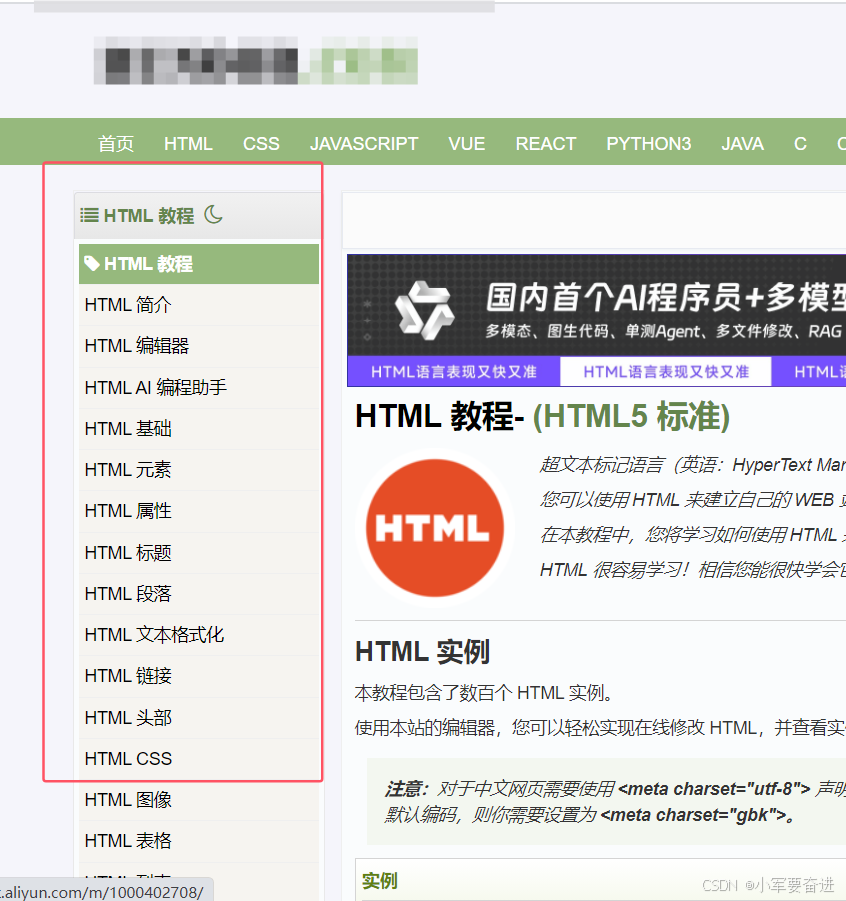
在pycharm中书写代码。
先倒入相关模块。
import requests
from bs4 import BeautifulSoup
import lxml.etree as le
这个案例写两种写法。
第一种:
url='https://www.runoob.com/html/html-tutorial.html'
response=requests.get(url)
# 第一种方法:
bs = BeautifulSoup(response.content, 'html.parser')
index=0
for a in bs.find(id='leftcolumn').find_all('a'):
index+=1
print(index,a.text.strip())
第二种:
#第二种方法:
contentx=le.HTML(response.content)
rets=contentx.xpath('//div[@id="leftcolumn"]/a/text()')
index=0
for category in rets:
index += 1
print(index,category.strip())
打印结果都是76条:

案例2:
爬取前程无忧工作职能里面的所有分类。

from selenium import webdriver
from selenium.webdriver.common.by import By
driver=webdriver.Chrome();#打开谷歌浏览器
url='https://we.51job.com/pc/search?keyword=&searchType=2&sortType=0&metro='
driver.get(url)
xpath1='//div[@class="e_e e_com"]/p' #定位到 "工作职能"按钮
element1=driver.find_element(By.XPATH,xpath1)
element1.click()
data=[]
element2=driver.find_elements(By.XPATH,'//ul[@class="cascader_panel_menu"][1]/li')
for span1 in element2:
driver.execute_script("arguments[0].scrollIntoView();", span1)#作用是将指定的元素滚动到浏览器视口中,使其可见
category1=span1.text
span1.click()
element3 = driver.find_elements(By.XPATH,'//ul[@class="cascader_panel_menu"][2]/li')
for span2 in element3:
driver.execute_script("arguments[0].scrollIntoView();", span2)
category2=span2.text
span2.click()
element4 = driver.find_elements(By.XPATH,'//ul[@class="cascader_panel_menu"][3]/li')
category3=[]
for span3 in element4:
driver.execute_script("arguments[0].scrollIntoView();", span3)
category3.append(span3.text)
data.append({
'level1':category1,
'level2':category2,
'level3':category3,
})
print(data)
输出:
