new/delete到底做了啥?
目录
一、new调用了啥?
二、malloc为什么可以分配内存?
三、brk和mmap
(1)brk
(2)mmap
(3)对比
四、虚拟地址空间结构认识
五、malloc在高并发情况下的缺陷
因为在写代码的时候,最常用的就是new来创建一个对象,但是new在c语言中是没有的,所以我特别想搞清楚new和malloc到底有啥区别?在调用他们的时候又为什么可以给我分配内存?本篇文章基于对new源代码的分析,达到理解底层的内存池的作用。为后续我们的高并发内存池提供一个模范。
一、new调用了啥?
#include<iostream>
using namespace std;
class ymh
{
public:
ymh()
{
cout << "构造" << endl;
}
~ymh()
{
cout << "析构" << endl;
}
private:
int _data;
};
int main()
{
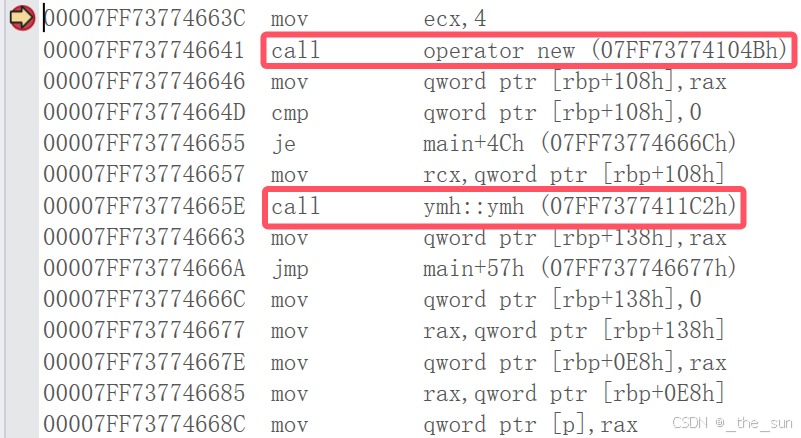
ymh* p = new ymh();
delete p;
return 0;
}这是一个简单的创建类对象的方式。我们进入new函数看看他实际上调用了哪些函数?
_NODISCARD _Ret_notnull_ _Post_writable_byte_size_(size) _VCRT_ALLOCATOR
_CRT_SECURITYCRITICAL_ATTRIBUTE
void* __CRTDECL operator new(size_t const size)
{
for (;;)
{
if (void* const block = malloc(size))
{
return block;
}
if (_callnewh(size) == 0)
{
if (size == SIZE_MAX)
{
__scrt_throw_std_bad_array_new_length();
}
else
{
__scrt_throw_std_bad_alloc();
}
}
// The new handler was successful; try to allocate again...
}
}
可以看到new实际上是被编译器转换成了operator new,而operator new是分为两个部分的:
(1)调用malloc
(2)如果分配内存失败则抛异常
那么有人就会问了,new不是会调用构造函数吗?可是这里的operator new并没有看到啊?其实是c++强调解耦,operator new只用于分配内存空间,而构造函数是编译器在编译代码的时候自动添加的,我们不能直接看到。
这里抛异常为什么不是根据malloc的返回值来决定抛异常与否呢?malloc失败只能返回NULL,但是你并不清楚是为什么失败,所以才有了下面对size的判断,看到底是你申请的空间超过理论最大值了,还是底层真的没有空间了。对于异常情况c++抛出不同的异常类型,可以方便程序员检查出自己代码的错误。
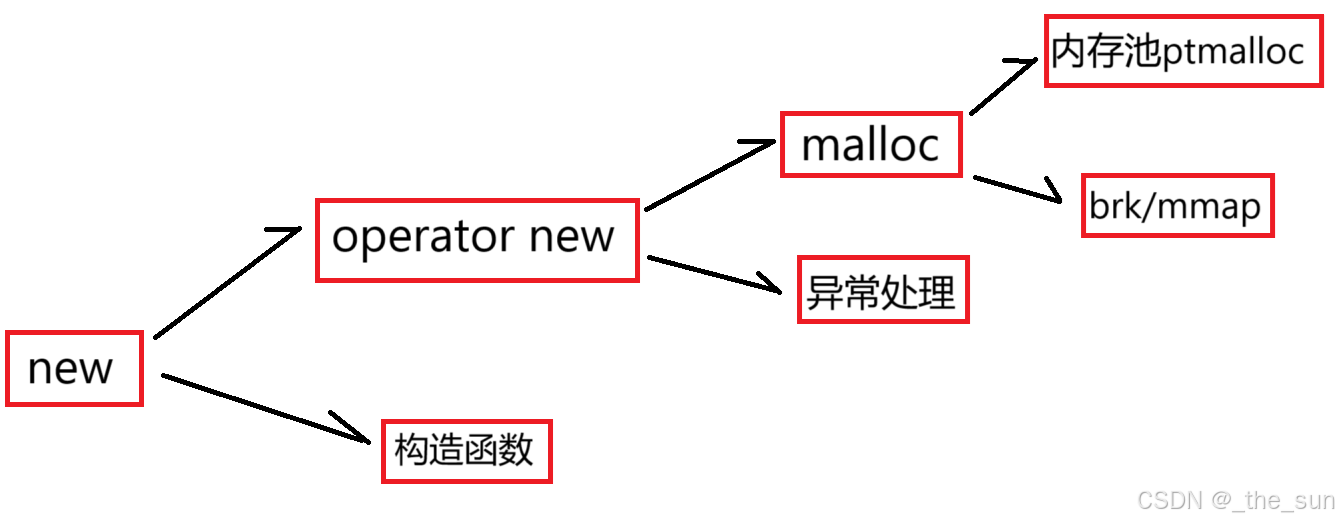
二、malloc为什么可以分配内存?
下面的三段代码是我在glibc库中找到的关于malloc的代码:
__libc_malloc函数是内存分配的主要入口点。- 在启用线程缓存的情况下,它首先尝试从线程缓存中获取内存块,以避免锁竞争和减少系统调用。
- 若线程缓存无法满足请求,则调用
__libc_malloc2,该函数可能负责更复杂的内存分配逻辑,如使用内存池、堆管理或系统调用。
void * __libc_malloc (size_t bytes)
{
#if USE_TCACHE
size_t tc_idx = csize2tidx (checked_request2size (bytes));
if (tcache_available (tc_idx))
return tag_new_usable (tcache_get (tc_idx));
#endif
return __libc_malloc2 (bytes);
}
函数名为__libc_malloc,参数为size_t bytes,返回一个void指针。
这表明这是一个内存分配函数,用于分配指定大小的内存块。
函数内部检查USE_TCACHE宏定义,若定义,则计算tc_idx并
使用tcache_get从线程缓存(tcache)中获取内存块。若获取成功,则返回标记为可用的内存块。
若线程缓存不可用或未定义USE_TCACHE,则调用__libc_malloc2函数进行内存分配。static __always_inline void *
tag_new_usable (void *ptr)
{
if (__glibc_unlikely (mtag_enabled) && ptr)
{
mchunkptr cp = mem2chunk(ptr);
ptr = __libc_mtag_tag_region (__libc_mtag_new_tag (ptr), memsize (cp));
}
return ptr;
}static void * __attribute_noinline__
__libc_malloc2 (size_t bytes)
{
mstate ar_ptr;
void *victim;
if (!__malloc_initialized)
ptmalloc_init ();
MAYBE_INIT_TCACHE ();
if (SINGLE_THREAD_P)
{
victim = tag_new_usable (_int_malloc (&main_arena, bytes));
assert (!victim || chunk_is_mmapped (mem2chunk (victim)) ||
&main_arena == arena_for_chunk (mem2chunk (victim)));
return victim;
}
arena_get (ar_ptr, bytes);
victim = _int_malloc (ar_ptr, bytes);
/* Retry with another arena only if we were able to find a usable arena
before. */
if (!victim && ar_ptr != NULL)
{
LIBC_PROBE (memory_malloc_retry, 1, bytes);
ar_ptr = arena_get_retry (ar_ptr, bytes);
victim = _int_malloc (ar_ptr, bytes);
}
if (ar_ptr != NULL)
__libc_lock_unlock (ar_ptr->mutex);
victim = tag_new_usable (victim);
assert (!victim || chunk_is_mmapped (mem2chunk (victim)) ||
ar_ptr == arena_for_chunk (mem2chunk (victim)));
return victim;
}
从这上面的分析我们就可以看出来:malloc底层调用了__libc_malloc,而__libc_malloc又做了以下步骤:
(1)检查线程缓存中有没有空闲内存块,如果有则直接分配返回
(2)如果没有空闲内存块了,则调用__libc_malloc2真正的分配空间。
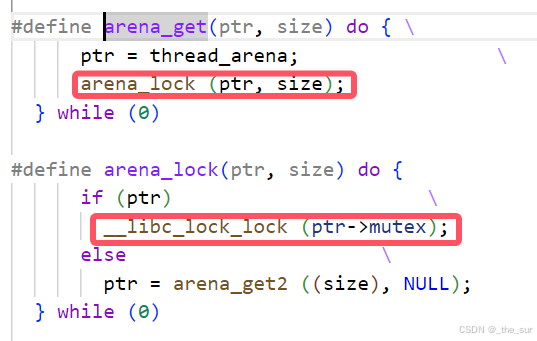
(3)__libc_malloc2又做了许多的事情,比如调用arena_get函数进行mutex加锁,而
brk和mmap的使用隐藏在_int_malloc函数中,根据分配的内存大小和配置,动态选择最合适的内存分配方式。(只不过由于封装的太厉害,我们要进入很深的函数才能看到真的调用了brk和mmap等系统调用,在这里我们还找到了一份lite_malloc的代码,他可以直观的看到brk和mmap)
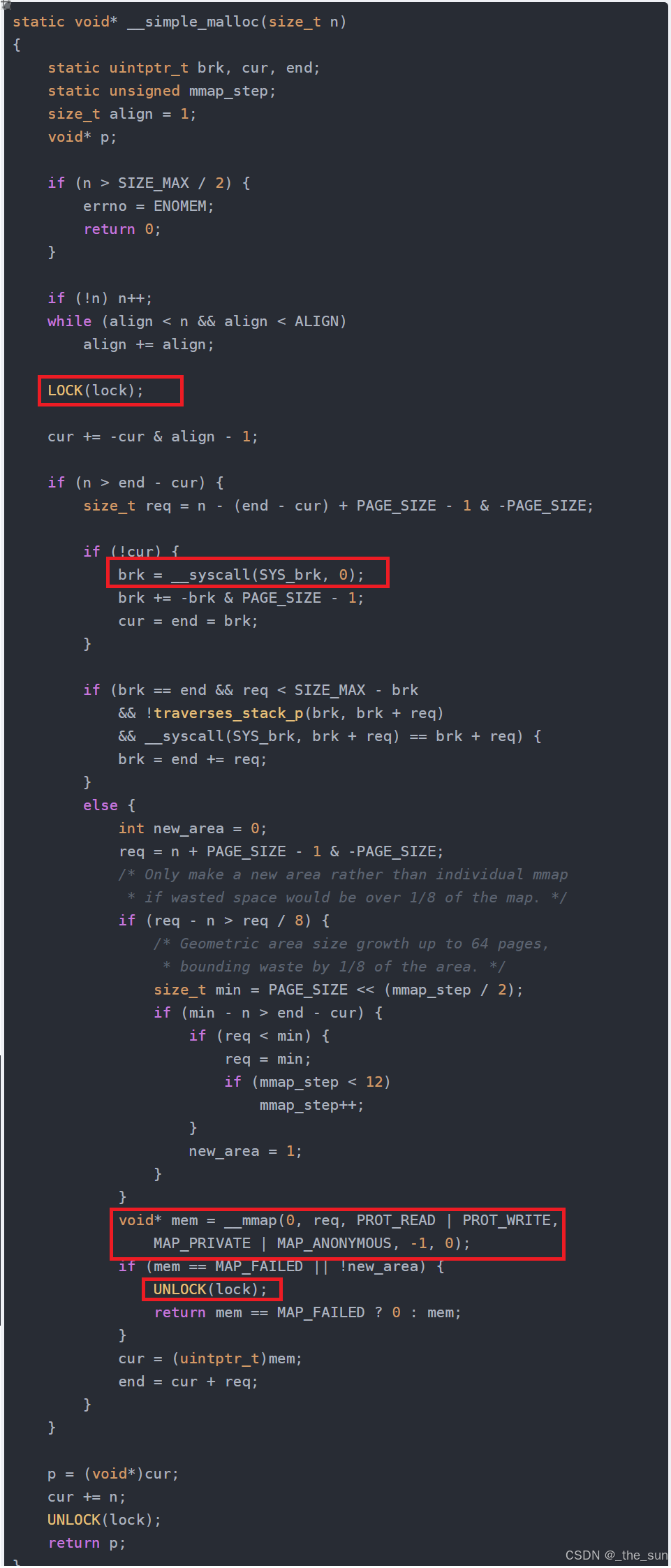
总结:
malloc会先在自己的内存池中找,看有没有空闲空间如果有则分配给调用者,如果没有则利用系统调用brk和mmap向操作系统拿一块空间再分配。
三、brk和mmap
(1)brk

(2)mmap

(3)对比

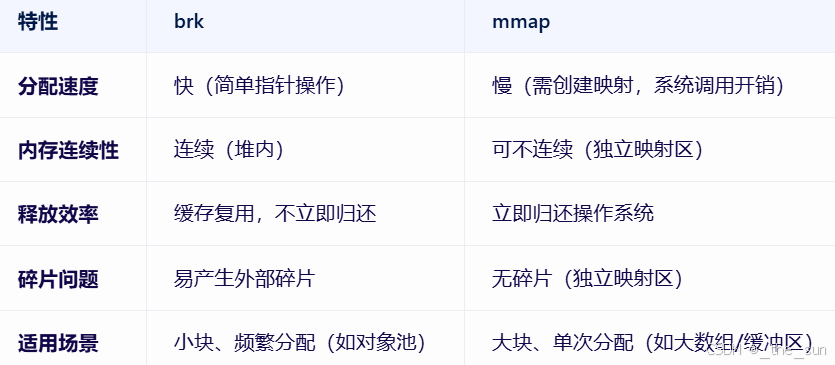
注意:不论是brk还是mmap,都是在虚拟地址空间中进行分配的,也就是他只是操作了我们pcb结构体中的某些字段,但是真正和物理内存建立映射是在第一次访问发生缺页中断的时候。
四、虚拟地址空间结构认识
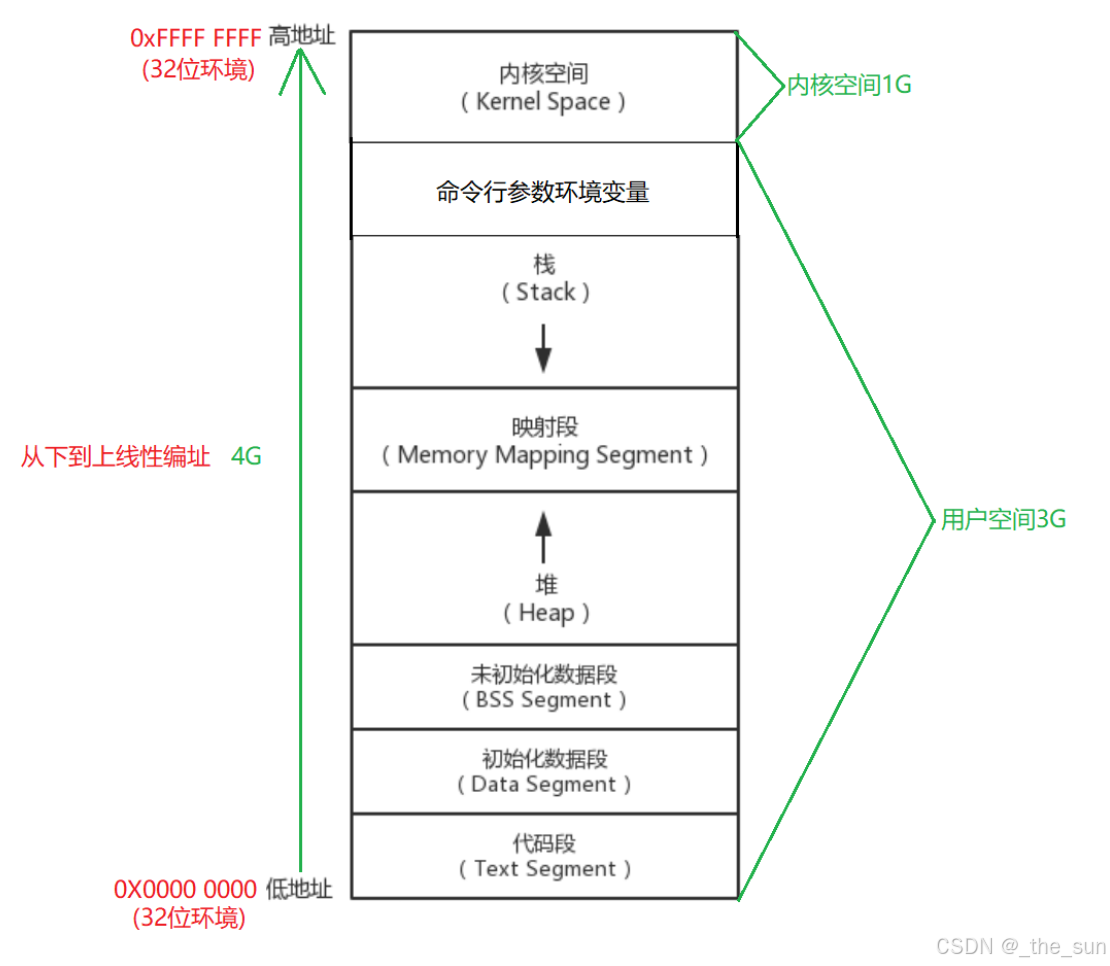
我们平时写完程序编译后,其实是把高级语言编译成机器码,存放在磁盘中,但是这些机器码中一定记录了各个区段的相对位置关系,这样在运行程序的时候就方便从磁盘中直接拿到虚拟地址空间。
下面是各个区域负责存放什么东西的示意图。大家了解一下即可。
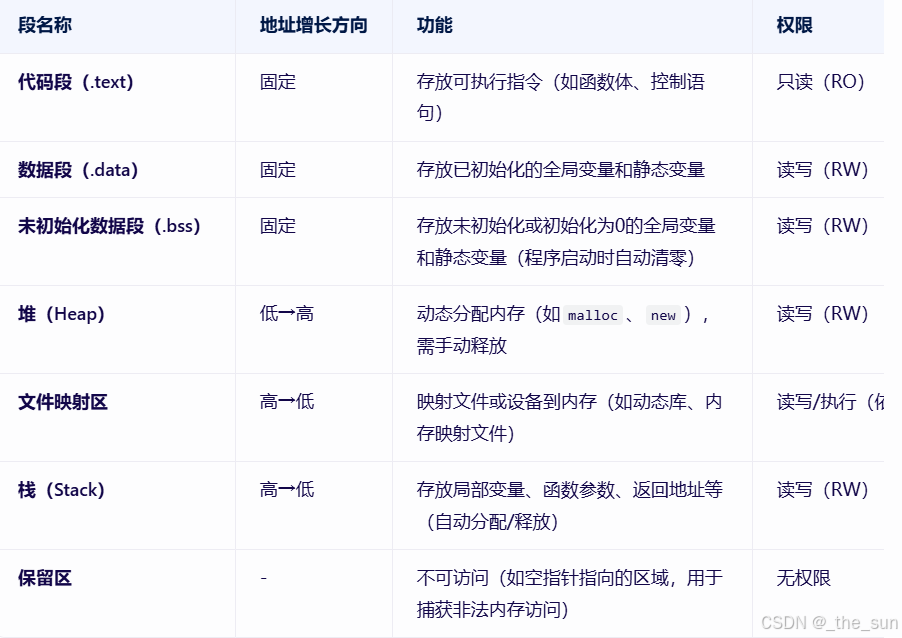
五、malloc在高并发情况下的缺陷
malloc是一个针对大多数情况下都适用的内存分配器,大多地方适用则意味着他在多线程同时访问的情况下,会有一定的劣势。
(1)并没有采取像tcmalloc的线程使用自己的缓存TLS无锁访问,而是全局锁,这就导致了多个线程即使想要访问自己的缓存也要进行竞争。
(2)TCmalloc采取了不同大小的内存块放到不同的链表维护,这样使用的时候可以直接查看对应桶中有无节点,而malloc采取的则是把所有不同大小的内存块放入一个链表,使用的时候遍历该链表。
(3)malloc的内存碎片问题也不如TCmalloc。
malloc在普通情况下已经足够优秀了,但是术业有专攻,我们同样需要学习在高并发场景下更优秀的TCmalloc。