LLM大模型之精度问题(FP16,FP32,BF16)详解与实践
本篇文章主要对训练LLM以及部署应用时的精度问题进行了一些探讨和实践,读过后应该会对常用的浮点数FP16,FP32,BF16有一个更好的理解~全篇阅读和实现需要15分钟左右,建议收藏,欢迎关注~
浮点数据类型在IEEE 754-2019(2008)[1]标准中进行了详细的定义,定义了不同精度的浮点数格式,如binary16、binary32和binary64,分别用16位、32位和64位二进制来表示,想要更全方位深入的了解的话,可以点引用查看官方的paper。下面进行一些常用的浮点数介绍。
FP16
FP16也叫做 float16,两种叫法是完全一样的,全称是Half-precision floating-point(半精度浮点数),在IEEE 754标准中是叫做binary16,简单来说是用16位二进制来表示的浮点数,来看一下是怎么表示的(以下图都来源于维基百科[2]):

其中:
- Sign(符号位): 1 位,0表示整数;1表示负数。
- Exponent(指数位):5位,简单地来说就是表示整数部分,范围为00001(1)到11110(30),正常来说整数范围就是 21−230 ,但其实为了指数位能够表示负数,引入了一个偏置值,偏置值是一个固定的数,它被加到实际的指数上,在二进制16位浮点数中,偏置值是 15。这个偏置值确保了指数位可以表示从-14到+15的范围即 2−14−215 ,而不是1到30,注:当指数位都为00000和11111时,它表示的是一种特殊情况,在IEEE 754标准中叫做非规范化情况,后面可以看到这种特殊情况怎么表示的。
- Fraction(尾数位):10位,简单地来说就是表示小数部分,存储的尾数位数为10位,但其隐含了首位的1,实际的尾数精度为11位,这里的隐含位可能有点难以理解,简单通俗来说,假设尾数部分为1001000000,为默认在其前面加一个1,最后变成1.1001000000然后换成10进制就是:
# 第一种计算方式
1.1001000000 = 1 * 2^0 + 1 * 2^(-1) + 0 * 2^(-2) + 0 * 2^(-3) + 1 * 2^(-4) + 0 * 2^(-5) + 0 * 2^(-6) + 0 * 2^(-7) + 0 * 2^(-8) + 0 * 2^(-9) = 1.5625
# 第二种计算方式
1.1001000000 = 1 + 576(1001000000变成10进制)/1024 = 1.5625所以正常情况下计算公式就是:
进制(−1)sign×2exponent−15×1.fraction(2进制)
进制(−1)sign×2exponent−15×(1+fraction(10进制)1024)
举一个例子来计算,这个是FP16(float16)能表示的最大的正数:
0111101111111111=(−1)0×230−15×(1+10231024)=65504
同样,这个是FP16(float16)能表示的最大的负数:
1111101111111111=(−1)1×230−15×(1+10231024)=−65504
这就是FP16(float16)表示的范围[-65504,65504]。
我们来看一些特殊情况,FP16(float16)能表示最小的正数是多少呢?
0000000000000001=(−1)0×21−15×(1+11024)≈0.000000059604645
我们就不一一的计算了,贴一个FP16(float16)特殊数值的情况:
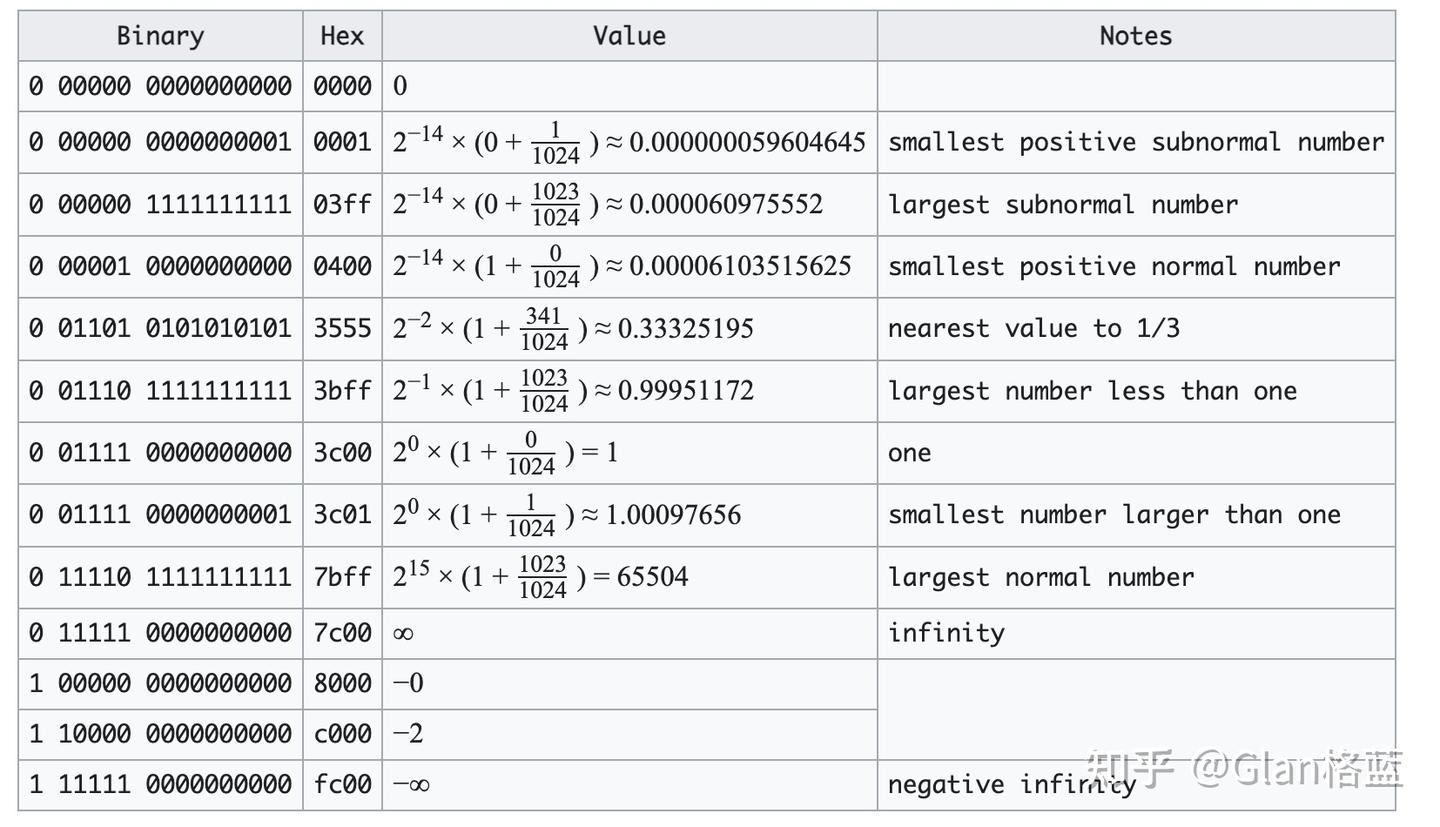
上表中,subnormal number是指指数位为全0的特殊情况情况,其他的也是一些常见的特殊情况。
接下来看一下在pytorch中是如何表示的:
torch.finfo(torch.float16)
# 结果
finfo(resolution=0.001, min=-65504, max=65504, eps=0.000976562, smallest_normal=6.10352e-05, tiny=6.10352e-05, dtype=float16)一些解释:
resolution(分辨率):这个浮点数类型的在十进制上的分辨率,表示两个不同值之间的最小间隔。对于torch.float16,分辨率是 0.001,就是说两个不同的torch.float16数值之间的最小间隔是 0.001。min(最小值):对于torch.float16,最小值是 -65504。max(最大值):对于torch.float16,最大值是 65504。eps(机器精度):机器精度表示在给定数据类型下,比 1 大的最小浮点数,对于torch.float16,机器精度是 0.000976562,对应上表中的smallest number larger than one。smallest_normal(最小正规数):最小正规数是大于零的最小浮点数,对于torch.float16,最小正规数是 6.10352e-05,对应上表中的smallest positive normal numbertiny(最小非零数):最小非零数是大于零的最小浮点数,对于torch.float16,最小非零数也是 6.10352e-05,也是对应上表中的smallest positive normal number
这里要详细的解释一下resolution(分辨率),这个是我们以十进制来说的两个数之间的最小间隔,我们看一个例子就会明白:
import torch
# 把10进制数转化为 torch.float16
num = 3.141
num_fp16 = torch.tensor(num).half()
print(num_fp16)
# 结果
tensor(3.1406, dtype=torch.float16)
num = 3.1415
num_fp16 = torch.tensor(num).half()
print(num_fp16)
# 结果
tensor(3.1406, dtype=torch.float16)
# 可以看到3.141和3.1415间隔只有0.0005,所以在float16下结果是一样的
num = 3.142
num_fp16 = torch.tensor(num).half()
print(num_fp16)
# 结果
tensor(3.1426, dtype=torch.float16)
# 可以看到结果不一样了从上面代码可以看到,十进制中相隔0.001,在float16中才会有变化,这个时候会有一个疑问,难道精度只有小数点后三位?那怎么之前见了很多参数都是有很多小数点的?那我们来看一下全过程,把float16变成2进制,再把2进制变成16进制:
import struct
def float16_to_bin(num):
# 将float16数打包为2字节16位,使用struct.pack
packed_num = struct.pack('e', num)
# 解包打包后的字节以获取整数表示
int_value = struct.unpack('H', packed_num)[0]
# 将整数表示转换为二进制
binary_representation = bin(int_value)[2:].zfill(16)
return binary_representation
num = 3.141
num_fp16 = torch.tensor(num).half()
print(num_fp16)
binary_representation = float16_to_bin(num_fp16)
print(binary_representation) # 打印二进制表示
# 结果
tensor(3.1406, dtype=torch.float16)
0100001001001000
num = 3.1415
num_fp16 = torch.tensor(num).half()
binary_representation = float16_to_bin(num_fp16)
print(binary_representation) # 打印二进制表示
# 结果
tensor(3.1406, dtype=torch.float16)
0100001001001000 # 还是一样的结果
num = 3.142
num_fp16 = torch.tensor(num).half()
print(num_fp16)
binary_representation = float16_to_bin(num_fp16)
print(binary_representation) # 打印二进制表示
# 结果
tensor(3.1426, dtype=torch.float16)
0100001001001001 # 不一样了再看一下把2进制变成16进制:
def binary_to_float16(binary_string):
# 检查输入是否是有效的16位二进制字符串
if len(binary_string) != 16:
raise ValueError("输入的二进制字符串必须是16位长")
# 提取组成部分:符号、指数、尾数
sign = int(binary_string[0]) # 符号位
exponent = int(binary_string[1:6], 2) # 指数位
mantissa = int(binary_string[6:], 2) / 1024.0 # 尾数位,除以2的10次方(即1024)以获得10位精度
# 根据符号、指数和尾数计算float16值
value = (-1) ** sign * (1 + mantissa) * 2 ** (exponent - 15)
return value
# 10进制3.141对应float16:3.1406
binary_representation = "0100001001001000"
# 将二进制表示转换为float16
float16_value = binary_to_float16(binary_representation)
print("通过2进制转化后Float16值:", float16_value)
# 结果:
通过2进制转化后Float16值: 3.140625
# 10进制3.1415对应float16:3.1406
binary_representation = "0100001001001000"
# 将二进制表示转换为float16
float16_value = binary_to_float16(binary_representation)
print("通过2进制转化后Float16值:", float16_value)
# 结果:
通过2进制转化后Float16值: 3.140625
# 10进制3.142对应float16:3.1426
binary_representation = "0100001001001001"
# 将二进制表示转换为float16
float16_value = binary_to_float16(binary_representation)
print("通过2进制转化后Float16值:", float16_value)
# 结果:
通过2进制转化后Float16值: 3.142578125因为在计算机中是以2进制存储计算的,所以转换后的float16值会有很多位小数,但这些后面的小数是没有精度的,换成10进制的精度是只有0.001的。注:在-1~1之间精度是0.0001,因为有隐含位1的关系,大家可以试一下。
BF16
BF16也叫做bfloat16(这是最常叫法),其实叫“BF16”不知道是否准确,全称brain floating point,也是用16位二进制来表示的,是由Google Brain开发的,所以这个brain应该是Google Brain的第二个单词。和上述FP16不一样的地方就是指数位和尾数位不一样,看图:

- Sign(符号位): 1 位,0表示整数;1表示负数
- Exponent(指数位):8位,表示整数部分,偏置值是 127
- Fraction(尾数位):7位,表示小数部分,也是隐含了首位的1,实际的尾数精度为8位
计算公式:
进制(−1)sign×2exponent−127×1.fraction(2进制)
这里要注意一下,并不是所有的硬件都支持bfloat16,因为它是一个比较新的数据类型,在 NVIDIA GPU 上,只有 Ampere 架构以及之后的GPU 才支持,如何判断呢?很简单:
import transformers
transformers.utils.import_utils.is_torch_bf16_gpu_available()
# 结果为True就是支持看一下在pytorch中是如何表示的:
import torch
torch.finfo(torch.bfloat16)
# 结果
finfo(resolution=0.01, min=-3.38953e+38, max=3.38953e+38, eps=0.0078125, smallest_normal=1.17549e-38, tiny=1.17549e-38, dtype=bfloat16)这个结果就不在赘述了,每个字段表示的含义和上述的是一致的,主要注意的是bfloat16的10进制间隔精度是0.01(注:在-1~1之间精度是0.001),表示范围是[-3.40282e+38,3.40282e+38]。可以明显的看到bfloat16比float16精度降低了,但是表示的范围更大了,能够有效的防止在训练过程中的溢出。有兴趣的同学可以用上述代码实验一下bfloat16~
FP32
FP32也叫做 float32,两种叫法是完全一样的,全称是Single-precision floating-point(单精度浮点数),在IEEE 754标准中是叫做binary32,简单来说是用32位二进制来表示的浮点数,看图:

- Sign(符号位): 1 位,0表示整数;1表示负数
- Exponent(指数位):8位,表示整数部分,偏置值是 127
- Fraction(尾数位):23位,表示小数部分,也是隐含了首位的1,实际的尾数精度为24位
计算公式:
进制(−1)sign×2exponent−127×1.fraction(2进制)
看一下在pytorch中是如何表示的:
import torch
torch.finfo(torch.float32)
# 结果
finfo(resolution=1e-06, min=-3.40282e+38, max=3.40282e+38, eps=1.19209e-07, smallest_normal=1.17549e-38, tiny=1.17549e-38, dtype=float32)这个结果也不在赘述了,每个字段表示的含义和上述的是一致的,主要注意的是float32的10进制间隔精度是0.000001(注:在-1~1之间精度是0.0000001),表示范围是[-3.40282e+38,3.40282e+38]。可以看到float32精度又高,范围又大,可是32位的大小对于现在大模型时代的参数量太占空间了。
以上就是对常见FP16,FP32,BF16精度的浮点数的一点介绍,后续会围绕:1.大模型中不同精度占用的显存大小?2.大模型中不同精度之间如何转换?3.模型训练中的混合精度是什么?等问题,有时间再写一篇文章~