000002 - Hadoop环境安装
Hadoop及其大数据生态圈
- 1. 背景
- 2. 实践
- 2.1 Linux服务器准备
- 2.2 在其中一台服务器上安装JDK
- 2.3 在其中一台服务器上安装HADOOP
- 2.4 本地模式运行一个hadoop案例
- 3. 自动化部署
1. 背景
要搭建Hadoop集群环境,我们需要执行如下
- 准备三台Linux服务器,服务器之间相互配置免密ssh登陆
- 在其中一台服务器上安装JDK
- 在其中一台服务器上安装HADOOP
- 本地运行模式-在一台服务器上运行HADOOP
- 将JDK和HADOOP分发给其他2台服务器
- 集群模式运行HADOOP
2. 实践
2.1 Linux服务器准备
我使用AWS创建三台服务器,并且将对服务器的创建过程以及服务器的配置全部用代码和脚本实现,参考这里.
2.2 在其中一台服务器上安装JDK
- 将jdk-8u212-linux-x64.tar.gz拷贝到node1的
/home/ec2-user/softwar目录。命令如下
# 需要先创建目录
scp -i "hadoop-instances-stack-key-pair.pem" jdk-8u212-linux-x64.tar.gz ec2-user@{node1_public_ip}:/home/ec2-user/software_package/
- ssh至node1服务器
ssh -i "hadoop-instances-stack-key-pair.pem" ec2-user@{node1_public_ip}
- 安装JDK
在node服务器上运行如下命令,解压JDK安装包
cd /home/ec2-user/software_package
tar -zxvf jdk-8u212-linux-x64.tar.gz -C /home/ec2-user/software_installation/
- 配置JDK环境变量
在node1上执行下方命令创建自定义env文件,这个文件会被/etc//profile加载
sudo vim /etc/profile.d/hadoop-learning-env.sh
输入如下内容后保存
#JAVVA_HOME
export JAVA_HOME=/home/ec2-user/software_installation/jdk1.8.0_212
export PATH=$PATH:$JAVA_HOME/bin
再输入如下命令重新加载环境变量
source /etc/profile
至此,JDK在node1节点安装成功
2.3 在其中一台服务器上安装HADOOP
- 将hadoop-3.1.3.tar.gz拷贝到node1的
/home/ec2-user/softwar目录。命令如下
scp -i "hadoop-instances-stack-key-pair.pem" hadoop-3.1.3.tar.gz ec2-user@{node1_public_ip}:/home/ec2-user/software_package/
- ssh至node1服务器
ssh -i "hadoop-instances-stack-key-pair.pem" ec2-user@{node1_public_ip}
- 解压HADOOP安装包
在node服务器上运行如下命令,解压JDK安装包
cd /home/ec2-user/software_package
tar -zxvf hadoop-3.1.3.tar.gz -C /home/ec2-user/software_installation/
- 配置HADOOP环境变量
在node1上执行下方命令修改自定义env文件,这个文件会被/etc//profile加载
sudo vim /etc/profile.d/hadoop-learning-env.sh
新增如下内容后保存
#HADOOP_HOME
export HADOOP_HOME=/home/ec2-user/software_installation/hadoop-3.1.3
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbin
再输入如下命令重新加载环境变量
source /etc/profile
至此,HADOOP在node1节点安装成功
2.4 本地模式运行一个hadoop案例
- ssh至node1服务器
ssh -i "hadoop-instances-stack-key-pair.pem" ec2-user@{node1_public_ip}
mkdir /home/ec2-user/workspace/wordcount
cd /home/ec2-user/workspace/wordcount
- 在wordcount目录下创建wordcount_input目录和wordcount_output目录
mkdir /home/ec2-user/workspace/wordcount/wordcount_input
- 在wordcount_input目录下放一个文本文件,其中包含一些单词,用空格隔开,下面是一个例子
apple banana bicycle
china apple cup bicycle
bicycle pinapple
- 执行下面命令,用hadoop本地运行模式统计文本中每个单词出现的次数
hadoop jar /home/ec2-user/software_installation/hadoop-3.1.3/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.3.jar wordcount /home/ec2-user/workspace/wordcount/wordcount_input/ /home/ec2-user/workspace/wordcount/wordcount_output
- 执行完成后,hadoop会创建一个目录/home/ec2-user/workspace/wordcount/wordcount_output,且统计结果就在这个目录下,如下图所示
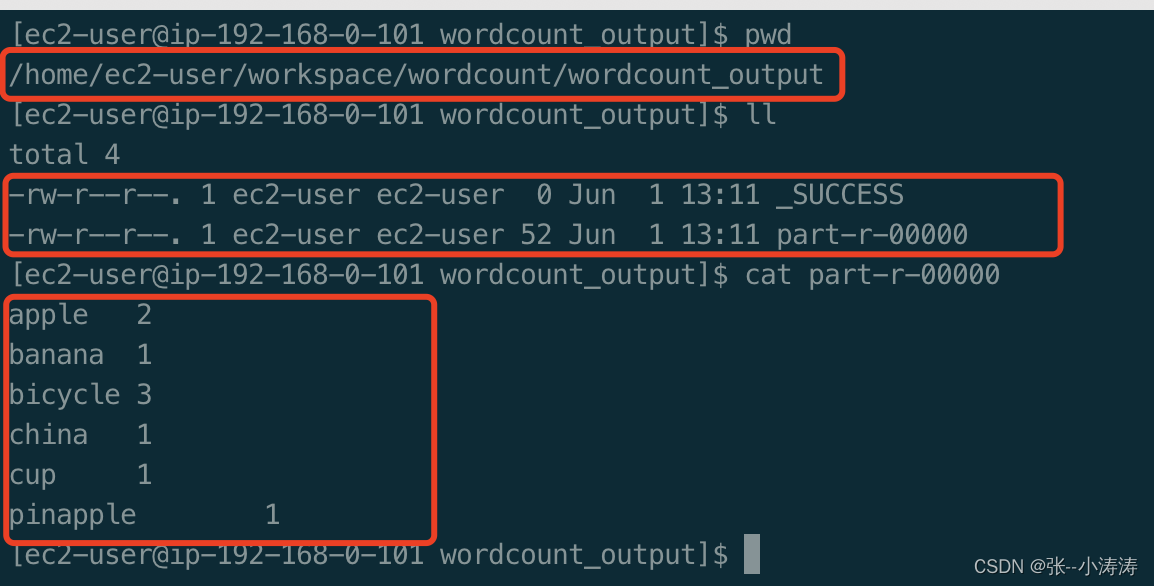
3. 自动化部署
在服务器创建成功后,我们还需要很多步骤来将JDK和HADOOP安装包上传解压至三台服务器,且需要对三台服务器进行环境变量的配置,着无疑是一个繁琐的步骤,因此我们可以将这写步骤使用脚本来实现。
参考这里