初识C++(入门)
C++简单介绍
一、C++简介与核心增强
-
C++起源
-
由Bjarne Stroustrup于1982年在C语言基础上扩展面向对象特性而来,完全兼容C语言。
-
核心目标:提供更高效的抽象机制(如类、模板),支持复杂软件开发。
-
-
C++对C语言的增强
-
命名空间:解决全局符号(变量、函数)命名冲突问题。
-
引用:提供变量的别名,避免指针的复杂操作。
-
函数与运算符重载:允许同名函数根据参数类型/数量区分功能。
-
面向对象:封装、继承、多态(未在示例中展开)。
-
泛型编程:模板(template)支持类型无关的代码。
-
异常处理:
try/catch机制增强错误处理能力。 -
STL(标准模板库):提供通用容器(如
vector、map)和算法。
-
-
C++编译器与开发环境
-
gcc与g++的区别:
-
gcc默认按C语言编译.c文件,g++统一按C++编译。 -
链接阶段,
g++自动链接C++标准库(如libstdc++),gcc需手动指定。
-
-
Linux下安装g++:
-
sudo apt-get install g++
g++ -v # 验证安装
编译运行示例:
#include <iostream>
using namespace std;
int main() {
cout << "Hello World" << endl;
return 0;
}编译命令:g++ HelloWorld.cpp -o output && ./output
4.常见编译警告与解决
-
字符串常量转换警告
char* str = "Hello C++"; // 错误:C++禁止字符串常量转为char*
解决方案:
const char* str = "Hello C++"; // 只读访问
char str[] = "Hello C++"; // 可修改的字符数组二、命名空间(Namespace)详解
-
命名空间的作用
-
解决全局作用域中符号(变量、函数、类)的命名冲突问题。
-
允许将代码逻辑分组,增强可维护性。
-
命名空间的定义与声明
定义语法:
-
namespace NamespaceName {
int var; // 变量
void func() { ... } // 函数
class MyClass { ... }; // 类
}示例:
namespace A {
int global = 10;
void function() { cout << "Namespace A" << endl; }
}
namespace B {
int global = 20;
void function() { cout << "Namespace B" << endl; }
}3.命名空间成员的使用
-
作用域解析符(
::):
A::global = 100; // 访问A命名空间的global变量
B::function(); // 调用B命名空间的函数using namespace声明:
using namespace A;
global = 100; // 直接使用A中的global
function(); // 直接调用A中的functionusing声明单个成员:
using A::global; // 仅引入A中的global
global = 100; // 直接访问4.命名空间的别名
-
语法:
namespace Alias = OriginalNamespace; -
示例:
namespace A_Alias = A;
cout << A_Alias::global << endl; // 等同于A::global
5.特殊命名空间
-
全局命名空间:
-
隐式存在,所有全局变量和函数属于该空间。
-
访问方式:
::global_var或::function()。
-
int global = 50;
int main() {
::global = 100; // 显式访问全局命名空间
return 0;
}匿名命名空间:
-
成员仅在当前文件内可见(类似C的
static)
namespace {
int local_var = 10; // 仅在当前文件有效
void local_func() { ... }
}6.跨文件命名空间任务示例
-
文件
a.cpp:
#include "space.h"
namespace A_Space {
int calc(int a, int b) { return a + b; }
}- 文件
b.cpp:
#include "space.h"
namespace B_Space {
int calc(int a, int b) { return a - b; }
}- 头文件
space.h:
#ifndef SPACE_H
#define SPACE_H
namespace A_Space { extern int calc(int a, int b); }
namespace B_Space { extern int calc(int a, int b); }
#endif- 主文件
main.cpp:
#include "space.h"
#include <iostream>
using namespace std;
int main() {
cout << A_Space::calc(5, 3) << endl; // 输出8
cout << B_Space::calc(5, 3) << endl; // 输出2
return 0;
}三、关键总结与对比
| 特性 | C语言 | C++增强 |
| 命名冲突解决 | 无机制,依赖唯一命名 | 命名空间分组管理 |
| 字符串常量处 | 允许char* str = "str" | 需用const char*或字符数组 |
| 函数重载 | 不支持 | 支持,根据参数类型/数量区分 |
| 作用域访问 | 全局变量直接访问 | 支持::、using声明等方式 |
引用
一、引用的基本概念
-
定义:
引用(Reference)是C++中为变量或对象创建的别名,与目标变量绑定后,对引用的操作等同于直接操作目标变量。-
语法:
类型 &引用名 = 目标变量; -
示例:
int data = 100; int "e = data; // quote是data的别名 quote = 200; // 等同于data = 200 cout << data; // 输出200
-
-
核心特性:
-
必须初始化:定义引用时必须绑定到目标变量。
int &ref; // 错误:未初始化 -
类型一致:引用类型必须与目标变量类型一致。
double a = 10.3; int &b = a; // 错误:类型不匹配 -
不可重新绑定:引用一旦初始化后,不能再绑定到其他变量。
int x = 10, y = 20; int &ref = x; ref = y; // 正确:将y的值赋给x(x=20) // &ref = y; // 错误:不能修改引用的绑定目标
-
二、引用的本质
底层实现:
引用在底层通过指针实现,编译器将其转换为指针操作,但语法上更安全简洁
int data = 10;
int &ref = data; // 编译器转换为 int* const ref = &data;
ref = 20; // 转换为 *ref = 20;三、引用的应用场景
-
作为函数参数:
通过引用传参,避免拷贝开销并允许修改实参。void swap(int &a, int &b) { int temp = a; a = b; b = temp; } int main() { int x = 10, y = 20; swap(x, y); // x=20, y=10 } -
作为函数返回值:
返回引用可避免拷贝,但需确保返回的引用不指向局部变量(否则悬空引用)。// 错误示例:返回局部变量的引用 int& func() { int x = 10; return x; // x在函数结束后销毁,引用无效 } // 正确示例:返回全局变量或静态变量的引用 int global = 10; int& getGlobal() { return global; } -
对指针和数组的引用:
-
指针的引用:
int data = 10; int *ptr = &data; int* &ref_ptr = ptr; // ref_ptr是ptr的别名 *ref_ptr = 20; // data=20 -
数组的引用:
int arr[3] = {1, 2, 3}; int (&ref_arr)[3] = arr; // ref_arr是数组arr的别名 cout << sizeof(ref_arr); // 输出12(假设int为4字节)
-
四、常引用(const引用)
-
定义:
使用const修饰的引用,禁止通过引用修改目标变量。-
语法:
const 类型 &引用名 = 目标变量; -
示例:
int num = 100; const int &cref = num; // cref = 200; // 错误:不能通过常引用修改值 num = 200; // 正确:直接修改原变量
-
-
绑定规则:
-
可以绑定到常量或非常量,但不可通过常引用修改目标。
-
可以绑定到临时对象(如字面量、表达式结果)。
const int &ref = 10; // 正确 const double &dref = 3.14; // 正确
-
-
应用场景:
-
函数参数传递时保护数据不被修改。
-
避免拷贝大型对象(如传递
const string&)。
-
五、引用与指针的对比
| 特性 | 引用 | 指针 |
|---|---|---|
| 初始化要求 | 必须初始化 | 可以不初始化(但可能野指针) |
| 空值合法性 | 不允许空值 | 允许nullptr |
| 重新绑定 | 不可重新绑定 | 可以指向不同对象 |
| 操作语法 | 直接使用别名(无需解引用) | 需通过*或->操作 |
| 内存占用 | 无额外内存(编译器优化为指针) | 占用内存存储地址 |
| 多级间接访问 | 仅支持一级引用 | 支持多级指针(如int**) |
六、const在指针和引用中的对比
-
指针的const修饰:
-
指向常量的指针(底层const):
const int *p = &x; // 不能通过p修改x的值 // *p = 20; // 错误 p = &y; // 正确:可以指向其他变量 -
常量指针(顶层const):
int *const p = &x; // p的指向不可变 *p = 20; // 正确:可以修改x的值 // p = &y; // 错误 -
指向常量的常量指针:
const int *const p = &x; // 既不能修改指向,也不能修改值
-
-
引用的const修饰:
-
常引用只能绑定到目标,且不能通过引用修改目标。
-
const int &cref = x;
// cref = 20; // 错误
x = 20; // 正确七、常见错误与注意事项
-
返回局部变量的引用:
导致悬空引用,引发未定义行为。int& func() { int x = 10; return x; // 错误:x在函数结束后销毁 } -
类型不匹配的引用:
引用类型必须与目标变量类型严格一致。double a = 10.3; int &b = a; // 错误:类型不匹配 -
修改常引用:
尝试通过常引用修改目标变量会编译报错。const int &cref = x; cref = 20; // 错误:assignment of read-only reference -
引用与指针的混淆:
引用不是指针,不能进行指针的运算(如++、--)。 - 重中之重:
- 指针在程序运行的时候,可以改变它的值,而引用和一个变量绑定之后就不能在引用其他变量
- ”sizeof(引用)” 得到的是所指向的变量(对象)的大小,而 ”sizeof(指针)” 得到的是指针本身的大小;
- 理论上,对于指针的级数没有限制,但是引用只能是一级
- 引用的本质是指针,但它在语义和使用上与指针有所不同。
- 引用不能是空的,它必须始终引用一个有效的对象。
- 指针可以是空的,并且可以在其生命周期内改变指向。
函数基本介绍
一、编译器对函数名的处理
-
C 编译器
-
函数名不变:编译后的函数名与源代码中的名称完全一致。
-
示例:函数
add在汇编代码中仍为add。 -
不支持函数重载:同名函数无法通过参数列表区分。
-
-
C++ 编译器
-
名称修饰(Name Mangling):将函数名与参数类型结合,生成唯一标识符。
-
示例:
-
int add(int a, int b)→_Z3addii -
float add(float a, float b)→_Z3addff
-
-
-
支持函数重载:通过不同参数列表生成不同修饰名,确保链接器正确区分函数。
-
二、函数重载(Function Overloading)
-
定义
-
在同一作用域内,允许定义多个同名函数,但要求 参数列表不同(参数类型或数量不同)。
-
示例:
-
int add(int a, int b); // 两个 int 参数
int add(int a, int b, int c); // 三个 int 参数
float add(float a, float b); // 两个 float 参数-
本质
-
通过名称修饰实现,不同参数列表生成不同的内部函数名。
-
编译后示例:
-
_Z3addii、_Z3addiii、_Z3addff。
-
-
-
限制
-
返回值类型不同不足以构成重载。
-
作用域必须相同:不同类或命名空间中的同名函数不构成重载。
-
三、默认参数(Default Arguments)
-
定义
-
在函数声明时为参数提供默认值,调用时若未传递该参数,则使用默认值。
-
示例:
-
int add(int a, int b, int c = 100); // c 的默认值为 1002.规则
-
默认参数必须从右向左连续设置:
int func(int a, int b = 10, int c = 20); // 正确
int func(int a, int b = 10, int c); // 错误!c 无默认值-
默认参数只能在声明中指定,定义时不可重复。
-
调用时省略参数需按顺序:
add(10, 20); // 等效于 add(10, 20, 100)-
应用场景
-
简化高频调用函数的参数传递。
-
注意避免与函数重载的二义性冲突。
-
四、内联函数(Inline Functions)
-
背景
-
普通函数调用的开销:压栈、跳转、返回等操作消耗时间和空间。
-
优化目标:消除调用开销,提升短小且频繁调用函数的性能。
-
-
定义与使用
-
使用
inline关键字标记函数,建议编译器内联展开:
-
inline int add(int a, int b) { return a + b; }强制内联(GCC扩展):
extern int add(int a, int b) __attribute__((always_inline));-
注意事项
-
编译器决策权:
inline仅为建议,编译器可能拒绝内联复杂函数(如含循环或递归)。 -
代码膨胀风险:过度内联会导致可执行文件体积增大,可能降低缓存效率。
-
适用场景:适合简单、高频调用的函数(如数学运算、getter/setter)。
-
五、对比总结
| 特性 | C 语言 | C++ 语言 |
|---|---|---|
| 函数名处理 | 无名称修饰 | 名称修饰(支持重载) |
| 函数重载 | 不支持 | 支持(参数列表不同即可) |
| 默认参数 | 不支持 | 支持(需从右向左设置) |
| 内联函数 | 无原生支持(可通过宏模拟) | 支持(inline 关键字或编译器属性) |
六、最佳实践
-
函数重载
-
确保参数列表差异明确,避免仅通过返回值类型重载。
-
优先使用参数类型差异而非默认参数实现重载。
-
-
默认参数
-
默认参数声明放在头文件中,定义时不可重复默认值。
-
避免默认参数与重载函数产生二义性。
-
-
内联函数
-
仅对简单、高频调用的函数使用内联。
-
谨慎使用强制内联属性(如
always_inline),需评估代码膨胀影响。
-
C++ 堆区内存管理总结与归纳
一、内存分配与释放机制对比
| 特性 | C语言 (malloc/free) | C++ (new/delete) |
|---|---|---|
| 类型 | 标准库函数 | 运算符 |
| 内存初始化 | 分配原始内存,不调用构造函数 | 分配内存并调用构造函数(初始化对象) |
| 内存释放 | 仅释放内存,不调用析构函数 | 调用析构函数后释放内存 |
| 返回值 | void*,需手动类型转换 | 返回对应类型指针,无需类型转换 |
| 内存大小计算 | 需手动计算(如 malloc(sizeof(int) * n) | 自动计算类型大小(如 new int[n]) |
| 安全性 | 易产生内存泄漏和类型错误 | 类型安全,减少人为错误 |
| 适用场景 | 与C代码兼容、简单内存分配 | 面向对象编程,需构造/析构函数的场景 |
二、new 和 delete 的具体用法
-
单个对象的内存管理
-
分配并初始化:
-
int* p = new int(10); // 分配内存并初始化为102.释放内存:
delete p; // 调用析构函数并释放内存对象数组的内存管理
-
分配数组(C++11起支持显式初始化):
int* arr = new int[3]{1, 2, 3}; // 分配3个int并初始化为1,2,3- 释放数组:
delete[] arr; // 释放数组内存注意事项
-
不可混用
new[]与delete:必须使用delete[]释放数组。 -
避免显式计算数组长度:
int size = sizeof(p)/sizeof(p[0]); // 错误!指针无法计算数组长度三、malloc/free 与 new/delete 的区别
-
核心差异
-
对象生命周期管理:
-
new/delete自动调用构造函数和析构函数,适用于对象。 -
malloc/free仅操作原始内存,不涉及对象生命周期。
-
-
类型安全:
-
new返回类型化指针,malloc返回void*需手动转换。
-
-
底层关系:
-
new/delete底层通过malloc/free实现,但添加了构造/析构逻辑。
-
-
-
为何C++保留
malloc/free?-
兼容C代码:C++需与C语言库和遗留代码兼容。
-
低级内存操作:某些场景需直接操作原始内存(如自定义内存池)。
-
四、面试常见问题
-
为何C++引入
new/delete?-
支持对象构造和析构,确保资源管理安全。
-
提供类型安全和更简洁的语法。
-
-
new初始化数组的限制(C++11前)-
C++98不允许显式初始化动态数组,所有元素默认初始化。
-
C++11允许显式初始化(如
new int[3]{1,2,3})。
-
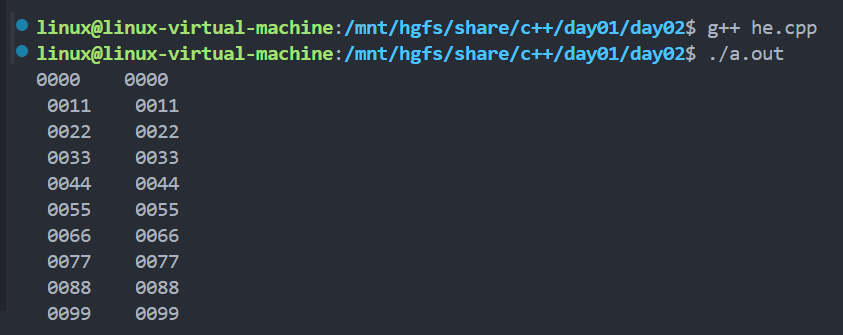
五、格式化输出内存数据
-
控制符说明
控制符 作用 示例 std::hex十六进制输出 cout << hex << num;std::uppercase十六进制字母大写 cout << uppercase << 0xff;std::setw(n)设置输出宽度为n位 cout << setw(2) << num;std::setfill(ch)设置填充字符为ch cout << setfill('0') << num;std::nouppercase恢复小写输出 cout << nouppercase << 0xff; -
输出
unsigned char的陷阱-
unsigned char可能被当作字符输出(如 ASCII 码),需强制转换为int:
-
cout << static_cast<int>(buffer[i]);简单示例:
#include <iostream>
#include <iomanip>
using namespace std;
// 分配内存函数
void allocate_memory(unsigned char* &buffer, int size) {
buffer = new unsigned char[size];
if (buffer == nullptr) {
cerr << "内存分配失败!" << endl;
exit(EXIT_FAILURE);
}
}
// 写入数据函数
void write_data(unsigned char* buffer, int size) {
for (int i = 0; i < size; i++) {
buffer[i] = static_cast<unsigned char>(0x11 * i);
}
}
// 输出数据函数
void print_data(unsigned char* buffer, int size) {
cout << hex << uppercase << setfill('0');
for (int i = 0; i < size; i++) {
//cout << setw(2) << static_cast<int>(buffer[i]);
cout << hex << setw(4) << setfill('0') << static_cast<int>(buffer[i]) ;
cout<< " ";
cout << hex << uppercase << setw(4) << setfill('0') << static_cast<int>(buffer[i])<< endl;
if (i != size - 1) cout << " ";
}
cout << hex << nouppercase << setfill(' ') << endl;
}
int main() {
const int SIZE = 10;
unsigned char* buffer = nullptr;
// 分配内存
allocate_memory(buffer, SIZE);
// 写入数据
write_data(buffer, SIZE);
// 输出数据
print_data(buffer, SIZE);
// 释放内存
delete[] buffer;
return 0;
}
C++ 调用 C 语言动态库
一、C++ 与 C 的函数名处理差异
-
C 语言编译器
-
无名称修饰:函数名在编译后保持原样(如
add→add)。 -
不支持函数重载:同名函数无法通过参数列表区分。
-
-
C++ 编译器
-
名称修饰(Name Mangling):将函数名与参数类型结合生成唯一标识符(如
add(int, int)→_Z3addii)。 -
支持函数重载:通过不同参数列表生成不同修饰名。
-
二、C++ 调用 C 动态库的链接问题
-
问题现象
-
在 C++ 代码中直接调用 C 动态库函数时,链接器报错
undefined reference。 -
原因:C++ 编译器期望函数名经过修饰,而 C 库中的函数名未修饰。
-
-
解决方案:
extern "C"-
作用:告知 C++ 编译器按 C 语言规则处理函数名,避免名称修饰。
-
语法:在 C 语言头文件中添加条件编译指令:
-
#ifdef __cplusplus
extern "C" {
#endif
extern int add(int, int);
extern int sub(int, int);
#ifdef __cplusplus
}
#endif-
说明:
-
__cplusplus宏仅在 C++ 编译环境中定义。 -
C 编译器会忽略
extern "C"声明,保持兼容性。
-
三、动态库的生成与使用
nm -D libas.so
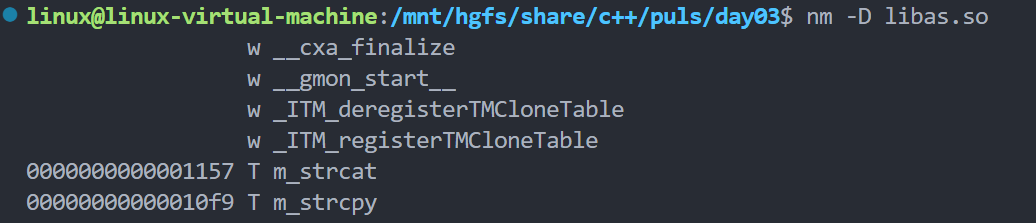
-
编译时错误
-
undefined reference:未正确链接库或未使用extern "C"声明。 -
libas.so: cannot open shared object file:运行时未找到动态库,需设置LD_LIBRARY_PATH。
-
-
验证动态库符号
-
使用
nm命令查看库中的符号列表:
-
-
C 语言库中的符号应为原始函数名(如
add、sub),而非修饰后的名称。 -
生成 C 动态库
# 编译为位置无关代码(-fPIC)
// add.c和sub.c都作为示例代码
gcc -fPIC -c add.c -o add.o
gcc -fPIC -c sub.c -o sub.o
# 生成动态库(-shared)
gcc -shared -o libas.so add.o sub.oC++ 调用动态库
-
编译命令:
g++ main.cpp -I ./ -L ./ -las-
-
-I ./:指定头文件路径。 -
-L ./:指定库文件路径。 -
-las:链接名为libas.so的库(-l后跟库名,省略lib前缀和.so后缀)。
-
-
编译时出现链接错误使用
readelf -a a.out | grep "共享库"
确保编译时能找到库文件
-
运行时路径设置:
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:动态库路径
./a.out运行时动态库未找使用
ldd a.out
若出现not found需要更改路径
export LD_LIBRARY_PATH=动态库路径(pwd查找当前路径)
确保运行时系统能找到动态库路径
五、关键总结
| 要点 | 说明 |
|---|---|
| 名称修饰差异 | C++ 通过名称修饰支持重载,C 无此机制。 |
extern "C" 的作用 | 避免 C++ 对 C 函数名进行修饰,确保链接正确。 |
| 动态库生成与链接 | 使用 -fPIC 和 -shared 生成动态库,-I、-L、-l 指定路径和库名。 |
| 运行时库路径 | 通过 LD_LIBRARY_PATH 设置动态库搜索路径。 |
面向对象与面向过程
一、核心区别
| 维度 | 面向过程(Procedure-Oriented) | 面向对象(Object-Oriented) |
|---|---|---|
| 核心思想 | 将问题分解为一系列步骤,通过函数逐步实现。 | 将问题抽象为对象,通过对象间的交互解决问题。 |
| 关注点 | 步骤逻辑:关注“怎么做” | 对象职责:关注“谁来做” |
| 典型场景 | 简单、线性任务(如数学计算、脚本处理) | 复杂系统(如游戏、企业级应用) |
| 设计模式 | 自顶向下,逐步细化 | 自底向上,先定义对象再组合 |
二、示例对比
1. 将大象放进冰箱
-
面向过程:
-
打开冰箱
-
放入大象
-
关闭冰箱
-
void putElephant() {
openFridge();
placeElephant();
closeFridge();
}面向对象:
-
冰箱对象调用
open()方法 -
冰箱对象调用
store(elephant)方法 -
冰箱对象调用
close()方法
class Fridge {
public:
void open();
void store(Object obj);
void close();
};
Fridge fridge;
fridge.open();
fridge.store(elephant);
fridge.close();2. 五子棋游戏
-
面向过程:
-
按步骤实现:开始游戏 → 黑子走棋 → 绘制 → 判断输赢 → 白子走棋 → ...
-
代码耦合度高,修改规则可能影响全局逻辑。
-
-
面向对象:
-
对象划分:
-
玩家对象:处理输入,通知棋盘变化。
-
棋盘对象:绘制棋盘,更新棋子状态。
-
规则对象:判断输赢、犯规。
-
-
优势:模块独立,修改规则仅需调整规则类。
-
三、优缺点对比
| 维度 | 面向过程 | 面向对象 |
|---|---|---|
| 优点 | 1. 设计简单,适合小型程序。 2. 执行效率高。 | 1. 易维护、易扩展。 2. 代码复用性高。 |
| 缺点 | 1. 维护性差,逻辑耦合度高。 2. 难以适应复杂需求。 | 1. 设计复杂度高。 2. 性能略低于面向过程。 |
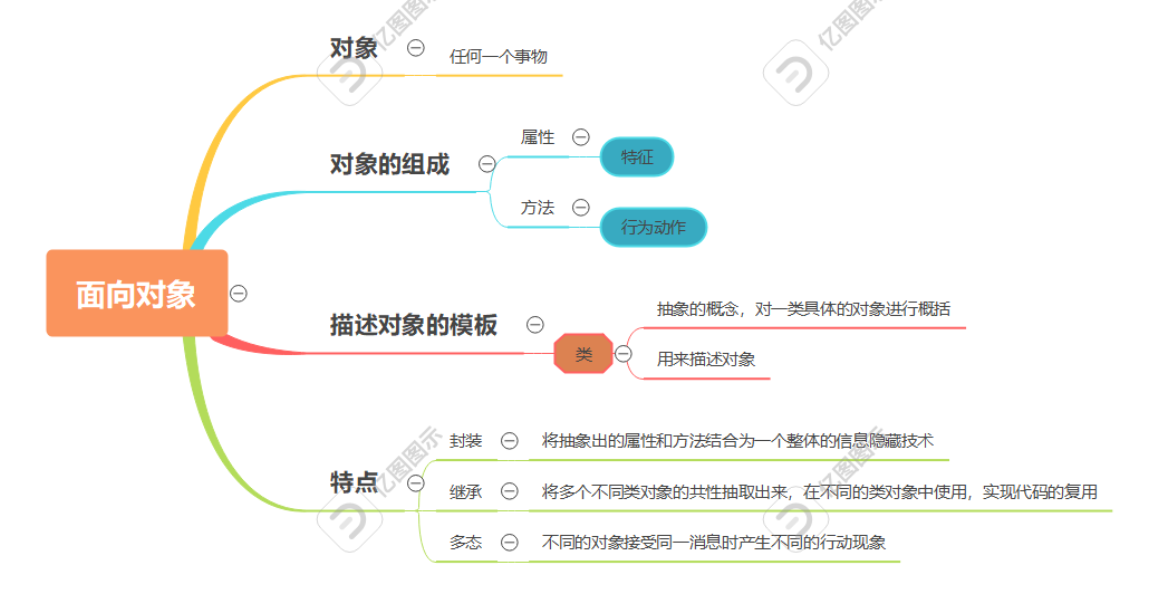
四、面向对象的核心特性
-
封装(Encapsulation)
-
定义:将数据(属性)和方法(行为)绑定为一个独立的对象,隐藏内部实现细节。
-
示例:
-
class Car {
private:
int speed; // 属性
public:
void accelerate() { speed += 10; } // 方法
};继承(Inheritance)
-
定义:子类继承父类的属性和方法,实现代码复用和层次化设计。
-
示例:
class Animal {
public:
void eat() { ... }
};
class Dog : public Animal { ... }; // Dog 继承 Animal多态(Polymorphism)
-
定义:同一操作作用于不同对象时,产生不同的行为。
-
示例:
class Shape {
public:
virtual void draw() = 0; // 抽象方法
};
class Circle : public Shape {
void draw() override { /* 绘制圆形 */ }
};五、适用场景
-
面向过程:
-
简单任务(如数学运算、脚本处理)。
-
对性能要求极高的场景(如嵌入式开发)。
-
-
-
面向对象:
-
复杂系统(如GUI应用、游戏开发)。
-
需要长期维护和扩展的项目(如企业级软件)。
-
六、总结
| 核心思想 | 适用场景 | 核心特性 | 开发效率 vs 运行效率 |
|---|---|---|---|
| 面向过程 | 简单、线性问题 | 无 | 开发快,运行效率高 |
| 面向对象 | 复杂、模块化系统 | 封装、继承、多态 | 开发慢,运行效率略低 |
总结:
-
面向过程以步骤为核心,适合简单、一次性任务;
-
面向对象以对象为核心,通过封装、继承、多态提升代码的可维护性和扩展性,适合复杂系统。
-
实际开发中,二者常结合使用(如面向对象框架内封装面向过程逻辑)。

- 这是本人的学习笔记不是获利的工具,小作者会一直写下去,希望大家能多多监督我
- 文章会每攒够两篇进行更新发布(受平台原因,也是希望能让更多的人看见)
- 感谢各位的阅读希望我的文章会对诸君有所帮助