【橘子大模型】使用LangChain和LLM交互
上文中我们完成了ollama的安装和启动,并且测试了几个模型的效果,不管好坏来说。总算是跑起来了,接下来我们要使用langchian来进行一些开发。在开发之前我们需要做一个环境的准备,这个环境指的是python环境。
python版本:3.10(3.13有些兼容性问题)
ide:vscode
编辑环境:Jupyter Notebook
一、环境准备
1、python虚拟环境
我们先来安装python的虚拟环境,我们先创建一个本次项目的目录。langchainTraing
然后我们进入这个目录,为了方便我直接使用vscode的终端操作。
下面我是用venv创建的虚拟环境,实际上我比较推荐conda,因为venv每次创建都是一个完全独立的,conda是有共享层的,这样可以节省一点。不过也无所谓了,我本来也不是python开发,没有那么多python项目,不会有很大浪费的。
# 因为我的py版本是3.10.11,所以我在这个目录下创建了一个叫做myenv31011的虚拟环境目录
python3 -m venv myenv31011
# 激活该虚拟环境
source myenv31011/bin/activate
这是我们这个虚拟环境,它独立于其他的环境,类似于一个沙盒,你在这里折腾不耽误其他的。
此时我们就位于我们创建出来的这个虚拟环境了。

ok,一切都很顺利。
2、集成Jupyter Notebook
Jupyter Notebook 是一个交互式工具,集成了很多功能可以直接使用。具体的可以去网上看下介绍。我们这里需要在vscode中集成他的插件。直接在商店里安装即可。我们为什么要用这个而不是直接在ide中写代码呢,因为这个类似于一种交互式,比如你pip就可以直接下载包,你要是写代码你还的在外面去拉取包,然后回来写,这个基本能记录你所有的终端操作以及代码书写。
安装之后可以使用command + shift + p来唤出创建Jupyter Notebook文件,或者是** shift + p**,然后就可以进行编辑了。
我们来创建一个jupyter窗口。
你还可以把它保存到一个指定目录下,下次继续打开即可。
我们看到jupyter可以有很多的功能,你可以写markdown文档,也可以写代码,它都会顺序运行。
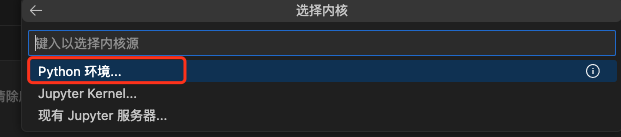
但是最重要的是我们这个jupeter是运行在哪个python环境下。这就需要我们选择内核。
我们点击右边的选择内核,然后选中我们创建的py虚拟环境即可。下面的那个jupyter内核我们没搞。
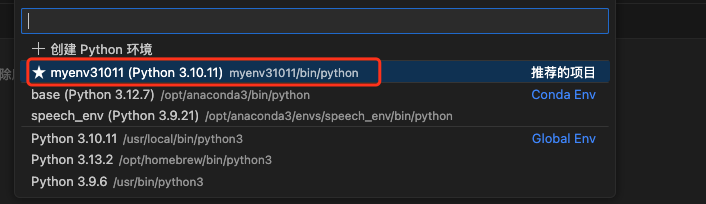
选中之后我们就可以进行开发了。
二、安装依赖
1、安装langchain
我们先来明确一下我们的结构,我们使用ollama来部署大模型(LLM)。然后我们使用langchain来对大模型的一些功能进行外部交互。那么很自然的我们其实需要langchain和ollma的依赖。下面我们就来安装这些依赖。
在jupyter中安装依赖就直接编码就行,你就把他当成一个终端使用即可。我们上面先搞个笔记,表示一下接下来干啥,你不写也行。
然后我们就安装langchain,这个要符合jupyter的语法。
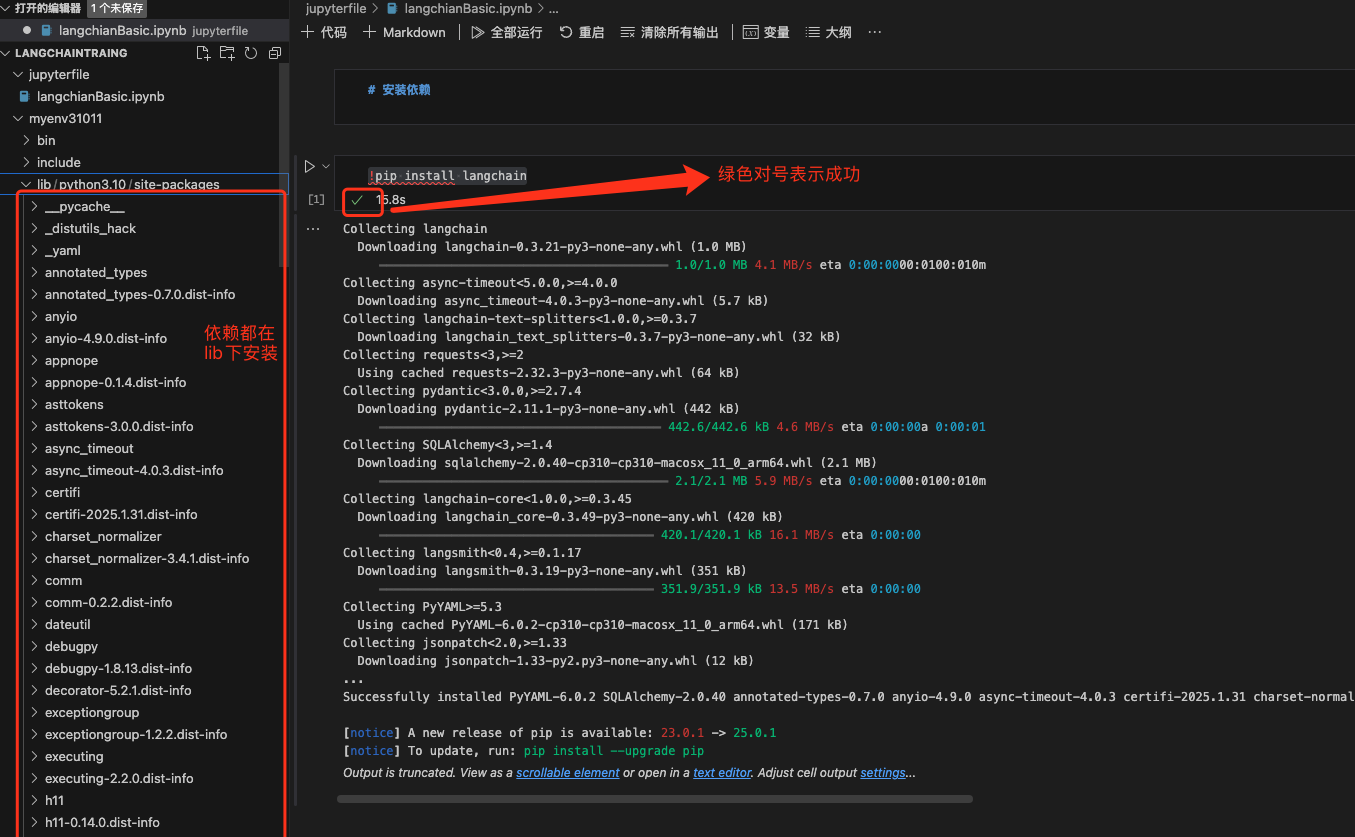
!pip install langchain
vscode爆红,不用管他,点击语句左边的运行就好,接下来他会提示你同意安装之类的。你就同意就好。
2、安装ollama
我们当然还要和ollama进行交互,不然你怎么调式发参数那些。所以我们需要安装一个langchian ollama的依赖。
我们先去langchian 的官网文档看下。我们搜索找到ollama llm.
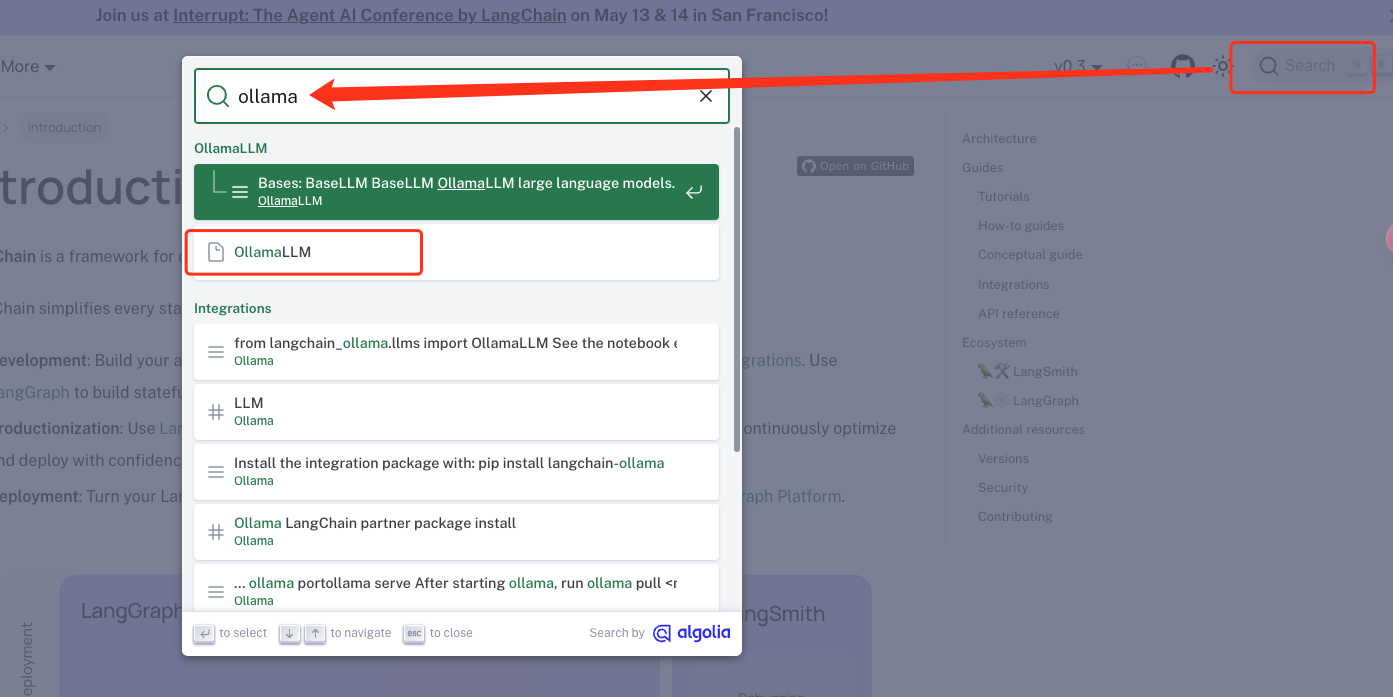
你能看到它左边支持各种各样的集成,我们先不去梳理他们的关系。
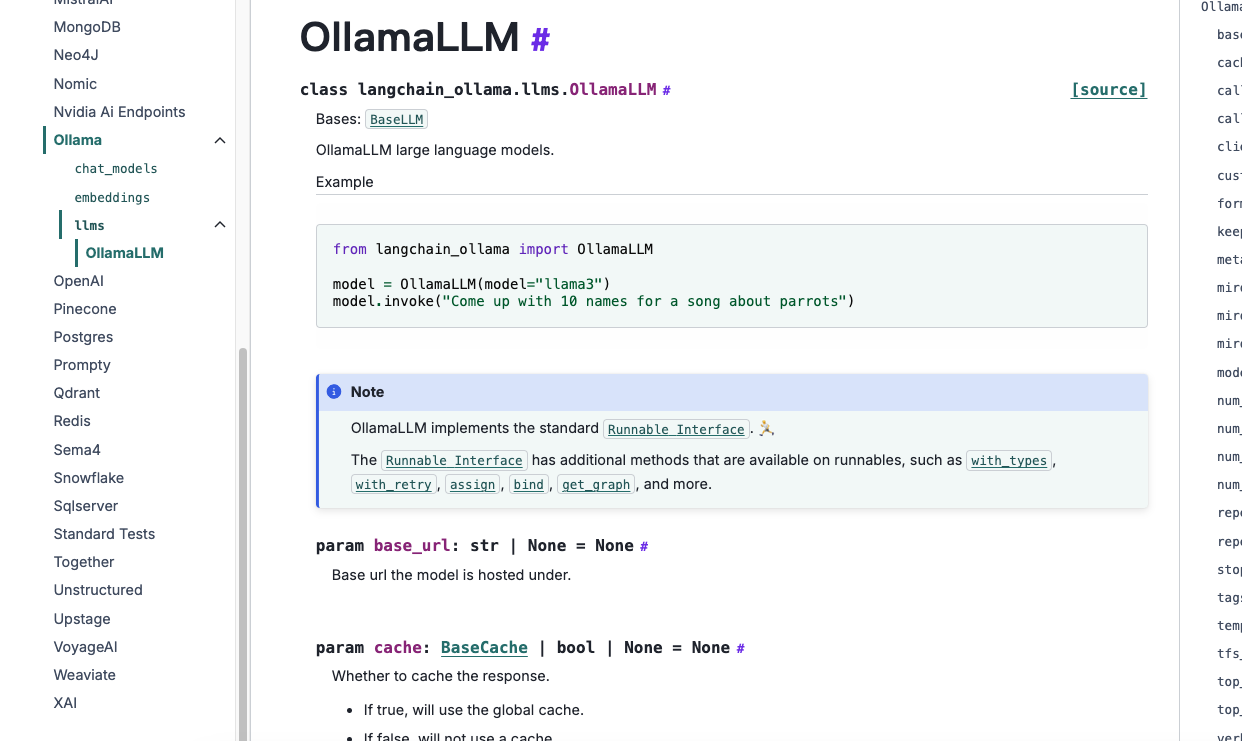
我们就针对ollama来操作即可。我们能看到对于chat聊天,它提供给我们的安装命令。
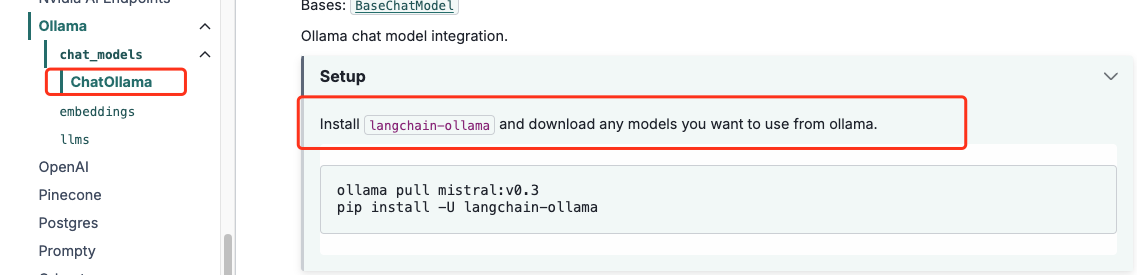
ok,这就是我们要的。接下来继续安装即可。继续添加一行代码。
!pip install langchain-ollama
然后运行即可。
同时我们后面会配置一些app key之类的东西,所以我们要在一个env文件中配置。所以我们还需要安装python中读取环境文件的依赖。于是我们还要加一行代码。就成这样了,我们直接一起运行这三行,放心之前加载过的这次不会加载了很快的。
!pip install langchain
!pip install langchain-ollama
!pip install python-dotenv
不出意外的话,应该是会成功的。我们看到我们的依赖都装上了。
然后我们在项目目录下创建一个环境变量的文件。.env后面我们用来做一些配置,然后用python-dotenv包进行读取,这样比较灵活。
ok,接下来我们就可以使用编程和我们上一节中部署的大模型进行交互了。
三、使用langchain进行与LLM交互
ok,此时我们已经万事俱备了,接下来我们就进行编码与我们的LLM进行交互。
首先我们先启动ollma。其实启动也简单,你装好之后他就配置了环境变量,你只需要执行任何一句ollama指令就起来了。
我在终端执行ollama list 此时就能唤醒ollama。然后我们启动ds 8b的模型。
ollama list
ollama run deepseek-r1:8b
一切都正常。
接下来我们开始编程。
那么作为一个开发你刚接到这个编程的需求,你之前完全不知道langchain怎么写,你怎么做。当然是查看文档了,我们去langchain的文档中定位ollama(我们是和ollama交互的)。langchain-ollama文档。
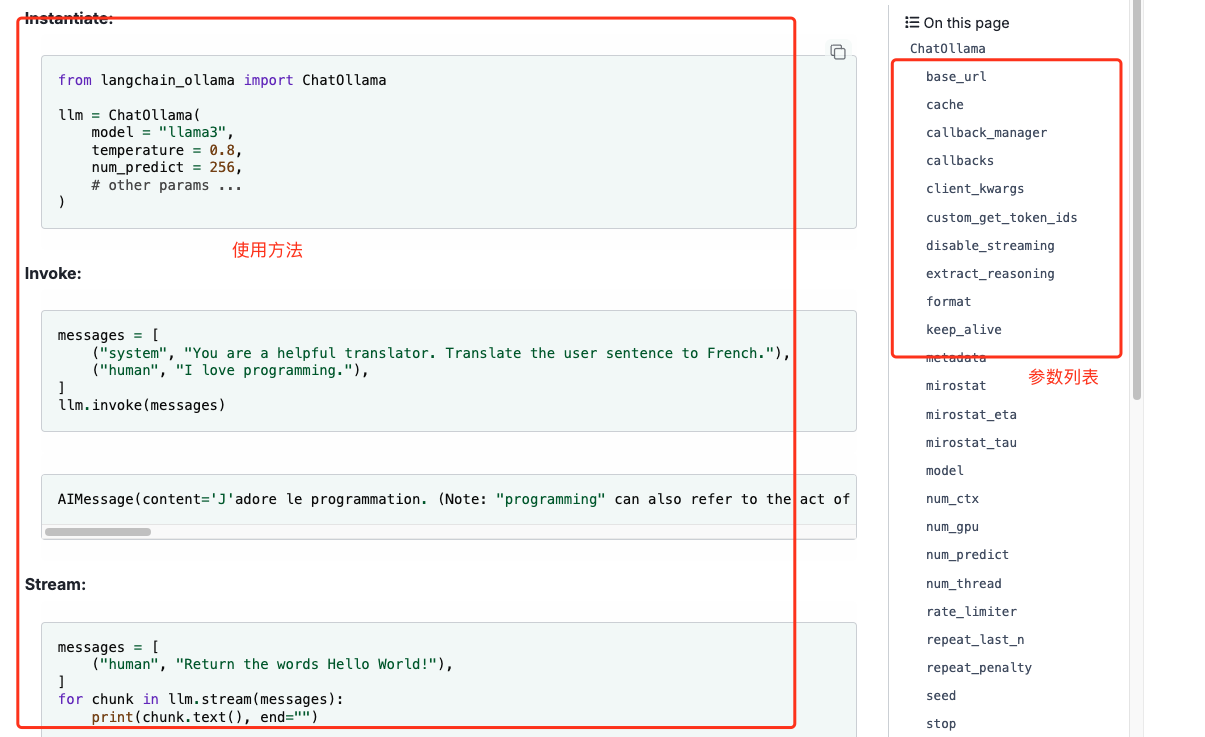
ok,我们只需要直接用就好了。
from langchain_ollama import ChatOllama
llm = ChatOllama(
base_url = "http://127.0.0.1:11434", # ollama的端口默认11434
model = "deepseek-r1:8b", # 选择刚才在ollama启动的模型
temperature = 0.8, # 下面是一些参数,适当调整一下就好,具体我们先不解释含义
num_predict = 256,
max_tokens = 2500
)
resp = llm.invoke("给我用java写一个冒泡排序,并且输出代码") # 使用invoke的方式执行
print(resp)
输出结果为:
content='<think>\n嗯,用户让我用Java写一个冒泡排序,并且输出代码。看起来他可能是一个刚开始学习编程的学生,对吧?那我应该怎么一步步引导他呢?\n\n首先,我得回忆一下冒泡排序的基本原理。冒泡排序是一种简单的排序算法,每次通过比较相邻元素并进行交换,直到整个数组按顺序排列。那它的步骤大概是这样的:从左到右遍历数组,逐个比较当前和前一个元素,如果当前元素较大,就交换它们。然后,重复这个过程多次,直到没有发生任何交换为止,这时候数组就已经有序了。\n\n那我应该先写出代码的大致框架。通常,冒泡排序的时间复杂度是O(n²),所以适用于数据量不大的情况。我需要用一个循环来控制重复比较和交换的过程。外层循环控制多少次,这取决于数组的长度,或者可以一直运行直到没有元素被交换。\n\n接下来,我得考虑如何实现这个逻辑。在Java中,可以使用for循环来控制。' additional_kwargs={} response_metadata={'model': 'deepseek-r1:8b', 'created_at': '2025-03-31T05:28:52.891118Z', 'done': True, 'done_reason': 'length', 'total_duration': 5706366542, 'load_duration': 26621250, 'prompt_eval_count': 16, 'prompt_eval_duration': 218922416, 'eval_count': 256, 'eval_duration': 5460375292, 'message': Message(role='assistant', content='', images=None, tool_calls=None)} id='run-49d4b01d-2ab0-4057-9a29-c293247bd823-0' usage_metadata={'input_tokens': 16, 'output_tokens': 256, 'total_tokens': 272}
瞬间懵逼,输出的东西没有代码,只有分析过程和一些元数据。
但是我们在终端使用就是完整的。

可见是我们的参数设置的有些损耗。那我们逐个看一下参数。
最终我定位为num_predict这个参数。

这个参数太小了无法填充完整的上下文,他默认才128,我们改成-2,此时填充完整上下文。参数解释我们先不搞,后面单独开一个。
此时结果就完美了,只是耗时比较长。
但是不管如何,我们是实现了初步的调用。我可以告诉你的是,你每次调用除了输出的元数据不变,其他的多少都会有变化的。那么这个变化我们要如何记录一下呢,或者我们如何监控一下。此时langchain也提供了这个能力。那就是langsmith。
四、LangSmith监控你的LangChain
LangSmith 是一个一体化开发人员平台,适用于由提供支持的应用程序LLM生命周期的每一步,无论您是否使用 LangChain 进行构建。调试、协作、测试和监控您的LLM应用程序。
为啥叫史密斯呢,不知道是不是为了致敬史密斯夫妇?毕竟特工就是监控别人的,对不起,我瞎猜的。

在下一篇文章中我们将会使用LangSmith来监控我们的LangChain应用。后会有期。