pandas【9】数据合并concat/_append
pandas.concat — pandas 2.2.3 documentation
批量合并相同格式的Excel、给DataFrame添加行、给DataFrame添加列
1. concat
pandas.concat(
objs,
*,
axis=0,
join='outer', #{‘inner’, ‘outer’}, default ‘outer’
ignore_index=False,
keys=None,
levels=None,
names=None,
verify_integrity=False,
sort=False,
copy=None)例1
>>> s1 = pd.Series(['a', 'b'])
>>> s2 = pd.Series(['c', 'd'])
>>> pd.concat([s1, s2])
0 a
1 b
0 c
1 d
dtype: object>>> pd.concat([s1, s2], ignore_index=True)
0 a
1 b
2 c
3 d
dtype: object>>> pd.concat([s1, s2], keys=['s1', 's2'],
... names=['Series name', 'Row ID'])
Series name Row ID
s1 0 a
1 b
s2 0 c
1 d
dtype: object例2
0)

1)按行连接


2) 按列连接


3) 被连接数据的索引不同
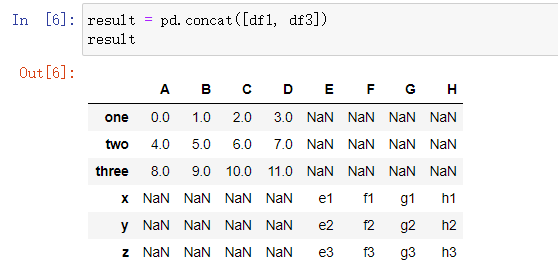

4)连接时取交集

5)按列连接时修改行索引

6)重设结果的索引
ignore_index: ignore_index参数默认为False,结果的索引是被连接数据的索引(行索引和列索引)。将ignore_index修改为True,可以重设结果的行索引或列索引。
按行连接时,设置ignore_index为True,结果的行索引被重设为0开始的整数索引。按列连接时,则列索引被重设。

7)添加外层行索引
keys: keys参数默认为空,可以用keys参数给结果添加外层的行索引,使行索引变成多重行索引。也可以添加多层,如果添加多层行索引则用元组的方式传入。
前面提到concat()的第一个参数可以用字典的方式传入,其效果与使用keys参数相同。

给结果添加外层的行索引后,可以用添加的外层行索引将被连接数据取出。

2. append
DataFrame.append(other, ignore_index=False, verify_integrity=False, sort=False)
other:要追加的DataFrame、Series或类似字典的对象。
ignore_index:是否忽略索引,在结果中重新标记行的索引,默认为False。
verify_integrity:如果为True,在创建具有重复索引的情况下会引发ValueError异常,默认为False。
sort:如果为True,则在列不对齐时对列进行排序,默认为False。import pandas as pd
if __name__ == '__main__':
# 创建第一个DataFrame
df1 = pd.DataFrame([[1, 2], [3, 4]], columns=['A', 'B'], index=['x', 'y'])
print(df1)
# 输出:
# A B
# x 1 2
# y 3 4
# 创建第二个DataFrame
df2 = pd.DataFrame([[5, 6], [7, 8]], columns=['A', 'B'], index=['x', 'y'])
print(df2)
# 输出:
# A B
# x 5 6
# y 7 8
# 使用append方法将df2追加到df1末尾
df_appended = df1._append(df2)
print(df_appended)
# 输出:
# A B
# x 1 2
# y 3 4
# x 5 6
# y 7 8
# 创建一个Series对象
series = pd.Series([9, 10], name='C')
print(series)
# 输出:
# 0 9
# 1 10
# Name: C, dtype: int64
# 使用append方法将series追加到df1末尾
df_appended_series = df1._append(series)
print(df_appended_series)
# 输出:
#
# A B 0 1
# x 1.0 2.0 NaN NaN
# y 3.0 4.0 NaN NaN
# C NaN NaN 9.0 10.0可以一行一行的给bataFrame添加数据
#第一个入参是一个列表,避免了多次复制
pd.concat(
[pd.DataFrame([i], columns=['A']) for i in range (5)],
ignore_index=True)Pandas知识点-连接操作concat-腾讯云开发者社区-腾讯云
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处:http://www.dtcms.com/a/100835.html
如若内容造成侵权/违法违规/事实不符,请联系邮箱:809451989@qq.com进行投诉反馈,一经查实,立即删除!