知识体系_统计学_05_参数估计
1 样本统计量
为了推断总体的某些特征(如总体均值、总体比例、总体方差),需要采用一定抽样技术从总体中抽取若干个体,所抽取的部分个体称为样本,样本中所包含个体的数量称为样本量。例如研究某城市居民家庭收入时,随机抽取1000户进行调查,这1000户就是一个样本,样本量是1000,以这1000个个体的收入来推断总体的居民家庭收入,可靠性如何?正是抽样分布要研究的问题。
统计量:设是从总体中抽取的样本量为n的一个样本,由此样本构造一个函数
,不依赖于任何未知的参数,则称函数
为统计量,也称“样本统计量”,当获得一个具体的样本后,将样本的具体观测值
代入统计量,则可以计算得到一个具体值,称为统计量值。
⚠️统计量是推断统计的基础,对于推断统计的重要性,就相当于随机变量在概率论中的地位。
常用统计量:
| 统计量 | 函数 |
| 样本均值 | |
| 样本方差 | |
| 样本变异系数 | |
| 样本偏度 | |
| 样本峰度 |
2 参数估计
参数估计包括点估计和区间估计两种。
2.1 点估计
为了估计总体参数,计算相应的样本特征--样本统计量(如样本均值、样本标准差、样本比率)等直接作为总体参数的估计值,因此称为“点估计”。我们常分别用样本均值、样本标准差、样本比率作为总体均值、总体标准差、总体比率的点估计量,根据一个具体抽取的样本计算出来估计量的值称为点估计值。
案例:


注:案例源自《商务与经济统计学》 第7章 7.2 点估计
从案例可以看出,根据样本的点估计值与总体参数是有差异的,当然这个差异是可预见的,因为样本只是总体的一个子集。(当利用样本去推断总体时,应该确保所设计的研究中抽样总体与目标总体是高度一致的)
⚠️当用样本推断总体时,要先保证样本的无偏,也就是样本要对总体具有代表性(如果样本有偏,那么计算的样本均值、样本方差、样本比例作为对总体参数的估计也会不准确)
2.2 抽样分布
在概率和概率分布中,我们把随机变量定义为对试验结果的数值描述。如果把每次从总体简单随机抽样,抽取容量为n的样本当作一次实验,每次得到的样本的统计量当作实验结果,那么样本平均值、样本标准差、样本比率都可以看作一个随机变量,那么关于这些随机变量的概率分布即为抽样分布
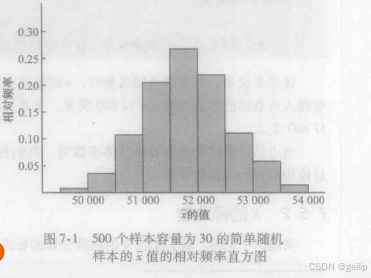
案例一:500个样本容量为30的简单随机样本的的分布
案例二:500个样本容量为30的简单随机样本的比率p的分布

⚠️在实践中,我们只从总体中抽取一个简单随机样本,以上两个案例中抽样过程进行了500次,仅仅是为了说明可能取得不同的样本,从而得到的样本统计量的值也不同,所以样本统计量是随机变量,而抽样分布正是研究样本统计量的概率分布。
研究样本统计量的抽样分布可以让我们对样本统计量与总体参数的接近程度做一个概率度量
2.2.1 样本均值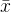 的抽样分布
的抽样分布
样本均值是一个随机变量,它的概率分布为抽样分布,具有以下性质:
(1)数学期望