中小微企业名录库上海野猪seo
在上一篇文章中,我们探讨了模型压缩与量化部署技术。本文将深入可解释性AI与特征可视化领域,揭示深度学习模型的决策机制,帮助开发者理解和解释模型的内部工作原理。
一、可解释性AI基础
1. 核心概念
-
特征重要性:识别输入特征对预测结果的贡献度
-
决策归因:追溯模型决策的关键依据
-
概念激活:识别模型学习的高级语义概念
2. 主要方法对比
| 方法类型 | 代表技术 | 适用场景 | 可视化粒度 |
|---|---|---|---|
| 基于梯度 | Saliency Map | 分类任务 | 像素级 |
| 基于扰动 | LIME | 任意模型 | 特征块级 |
| 类激活映射 | Grad-CAM | CNN模型 | 空间区域级 |
| 概念分析 | TCAV | 概念解释 | 语义概念级 |
二、PyTorch特征可视化实战
1. 特征重要性分析(Saliency Map)
import torch
import matplotlib.pyplot as plt
from torchvision import models, transforms
from PIL import Image
# 加载预训练模型
model = models.resnet50(weights='IMAGENET1K_V1').eval()
preprocess = transforms.Compose([transforms.Resize(256),transforms.CenterCrop(224),transforms.ToTensor(),transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]),
])
# 加载图片
def load_image(image_path):image = Image.open(image_path)image_tensor = preprocess(image)image_tensor = image_tensor.unsqueeze(0) return image_tensor
# 生成Saliency Map
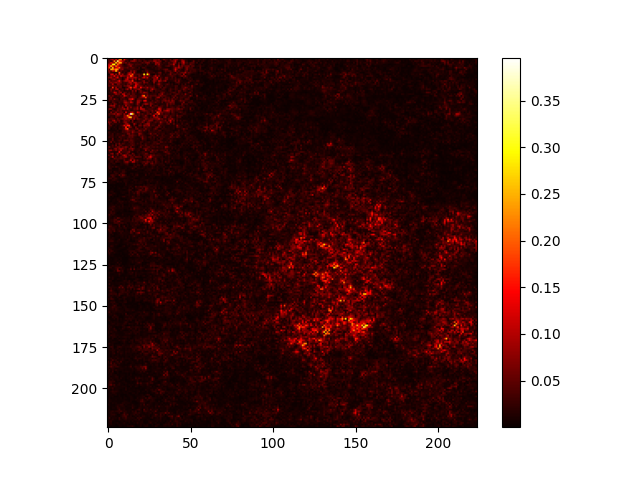
def generate_saliency(img_tensor, model):img_tensor.requires_grad_()output = model(img_tensor)output.max().backward()saliency = img_tensor.grad.data.abs().max(dim=1)[0]return saliency.squeeze().cpu().numpy()
# 可视化
img = load_image('cat.jpeg') # 自定义图像加载函数
saliency = generate_saliency(img, model)
plt.imshow(saliency, cmap='hot')
plt.colorbar()
plt.show()原图:

输出:
2. 类激活映射(Grad-CAM)
import torch
import torch.nn.functional as F
import matplotlib.pyplot as plt
import numpy as np
from torchvision import models, transforms
from PIL import Image
import cv2
import matplotlib.font_manager as fm
# 设置中文字体
plt.rcParams['font.sans-serif'] = ['SimHei'] # 使用黑体
plt.rcParams['axes.unicode_minus'] = False # 解决负号显示问题
class GradCAM:def __init__(self, model, target_layer):"""GradCAM类初始化Args:model: 目标模型target_layer: 要计算CAM的目标层"""self.model = modelself.gradients = None # 保存梯度self.activations = None # 保存激活值self.target_layer = target_layer# 注册前向和反向钩子self.target_layer.register_forward_hook(self.save_activations)self.target_layer.register_full_backward_hook(self.save_gradients)def save_activations(self, module, input, output):"""保存前向传播的激活值"""self.activations = output.detach() # 不计算梯度def save_gradients(self, module, grad_input, grad_output):"""保存反向传播的梯度"""self.gradients = grad_output[0].detach() # 不计算梯度def forward(self, x):"""前向传播"""return self.model(x)def __call__(self, x, class_idx=None):"""生成GradCAM热力图Args:x: 输入张量class_idx: 目标类别索引,None表示自动选择最高概率类别Returns:cam: 归一化的热力图class_idx: 使用的类别索引"""# 前向传播获取预测结果logits = self.forward(x)if class_idx is None:class_idx = logits.argmax() # 自动选择最高概率类别# 反向传播计算梯度self.model.zero_grad()logits[0, class_idx].backward(retain_graph=True)# 计算权重(全局平均池化梯度)weights = self.gradients.mean(dim=(2, 3), keepdim=True)# 计算类激活图cam = (weights * self.activations).sum(dim=1, keepdim=True)cam = F.relu(cam) # 只保留正激活cam = F.interpolate(cam, x.shape[2:], mode='bilinear', align_corners=False) # 上采样到输入尺寸# 归一化到[0,1]范围cam_min, cam_max = cam.min(), cam.max()cam = (cam - cam_min) / (cam_max - cam_min + 1e-8) # 避免除以零return cam.squeeze().cpu().numpy(), class_idx.item()
# 图像预处理流程
preprocess = transforms.Compose([transforms.Resize(256), # 调整大小transforms.CenterCrop(224), # 中心裁剪transforms.ToTensor(), # 转为张量transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]), # ImageNet标准化
])
def load_image(image_path):"""加载并预处理图像Args:image_path: 图像路径Returns:image_tensor: 预处理后的张量original_image: 原始PIL图像"""image = Image.open(image_path).convert('RGB') # 确保RGB格式image_tensor = preprocess(image)image_tensor = image_tensor.unsqueeze(0) # 添加批次维度return image_tensor, image
def visualize_gradcam(image, heatmap, alpha=0.5):"""可视化GradCAM结果Args:image: 原始PIL图像heatmap: GradCAM生成的热力图alpha: 热力图透明度Returns:superimposed_img: 叠加后的图像"""# 转换图像为numpy数组并调整大小img = np.array(image)img = cv2.resize(img, (224, 224))# 调整热力图大小并应用颜色映射heatmap = cv2.resize(heatmap, (img.shape[1], img.shape[0]))heatmap = np.uint8(255 * heatmap) # 转为0-255范围heatmap = cv2.applyColorMap(heatmap, cv2.COLORMAP_JET) # 应用Jet颜色# 叠加热力图和原始图像superimposed_img = heatmap * alpha + img * (1 - alpha)superimposed_img = np.clip(superimposed_img, 0, 255).astype(np.uint8) # 限制范围return superimposed_img
# 主程序
if __name__ == "__main__":# 加载预训练ResNet50模型model = models.resnet50(weights='IMAGENET1K_V1').eval()try:# 加载图像img_tensor, original_image = load_image('cat.jpeg')# 设置目标层(ResNet50最后一个卷积层)target_layer = model.layer4[-1].conv3grad_cam = GradCAM(model, target_layer)# 生成热力图heatmap, class_idx = grad_cam(img_tensor)# 可视化结果fig, ax = plt.subplots(1, 3, figsize=(15, 5))# 原始图像ax[0].imshow(original_image)ax[0].set_title('原始图像')ax[0].axis('off')# 热力图ax[1].imshow(heatmap, cmap='jet')ax[1].set_title('GradCAM热力图')ax[1].axis('off')# 叠加效果superimposed = visualize_gradcam(original_image, heatmap)ax[2].imshow(superimposed)ax[2].set_title(f'可视化结果 (类别: {class_idx})')ax[2].axis('off')plt.tight_layout()plt.savefig('gradcam_results.png', bbox_inches='tight', dpi=300)plt.show()except FileNotFoundError:print("错误:未找到'cat.jpeg'文件,请确保图像存在")except Exception as e:print(f"发生错误: {e}")输出为:
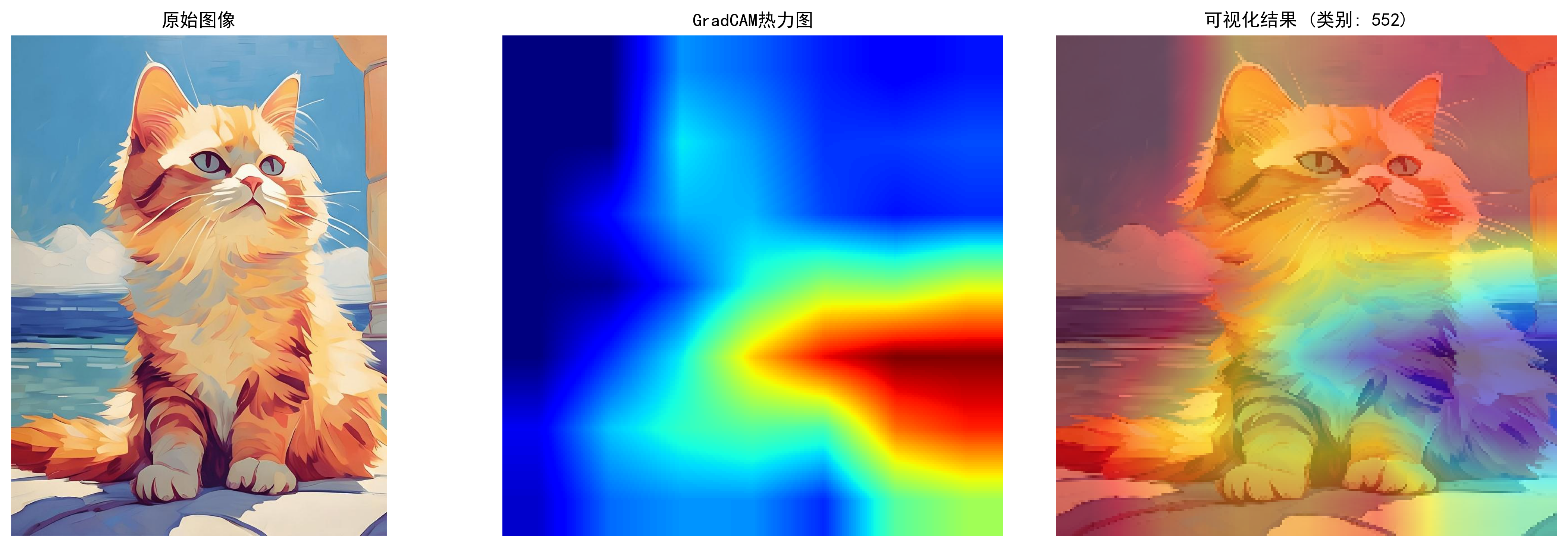
三、高级可视化技术
1. 特征反演(Feature Inversion)
import torch
import torch.nn.functional as F
from torch import optim
from torchvision import models
import matplotlib.pyplot as pltdef invert_features(model, target_features, input_size=(3, 224, 224),num_iterations=300, lr=0.1, show_progress=True):"""通过优化随机输入来反演生成与目标特征匹配的图像参数:model (nn.Module): 特征提取模型(需要返回目标层的特征)target_features (Tensor): 目标特征图(形状需与model输出一致)input_size (tuple): 生成图像的尺寸(channels, height, width)num_iterations (int): 优化迭代次数lr (float): 学习率show_progress (bool): 是否显示优化过程返回:Tensor: 反演生成的图像(1, C, H, W)"""# 1. 初始化随机输入(使用正态分布)synthetic_img = torch.randn(1, *input_size,requires_grad=True,device=target_features.device)# 2. 设置优化器(Adam + 学习率衰减)optimizer = optim.Adam([synthetic_img], lr=lr)scheduler = optim.lr_scheduler.StepLR(optimizer, step_size=100, gamma=0.5)# 3. 优化循环losses = []best_img = Nonebest_loss = float('inf')for i in range(num_iterations):optimizer.zero_grad()# 前向传播获取当前特征current_features = model(synthetic_img)# 计算MSE损失 + 正则项(图像总变分正则化)mse_loss = F.mse_loss(current_features, target_features)tv_loss = total_variation(synthetic_img) * 1e-6 # 总变分正则化loss = mse_loss + tv_loss# 反向传播loss.backward()optimizer.step()scheduler.step()# 数值截断(保持合理范围)synthetic_img.data = torch.clamp(synthetic_img, -2.5, 2.5)# 记录最佳结果if loss.item() < best_loss:best_loss = loss.item()best_img = synthetic_img.detach().clone()losses.append(loss.item())# 打印进度if show_progress and (i % 50 == 0 or i == num_iterations - 1):print(f'Iter [{i + 1}/{num_iterations}], Loss: {loss.item():.4f}')# 4. 后处理并返回最佳结果final_img = post_process(best_img)# 可视化结果if show_progress:visualize_results(losses, final_img)return final_imgdef total_variation(img):"""计算图像的总变分(平滑性正则化)"""batch_size = img.size(0)height_var = torch.sum(torch.abs(img[:, :, 1:, :] - img[:, :, :-1, :]))width_var = torch.sum(torch.abs(img[:, :, :, 1:] - img[:, :, :, :-1]))return (height_var + width_var) / batch_sizedef post_process(img_tensor):"""后处理生成图像"""# 1. 反归一化(假设输入是ImageNet标准化后的)mean = torch.tensor([0.485, 0.456, 0.406]).view(1, 3, 1, 1).to(img_tensor.device)std = torch.tensor([0.229, 0.224, 0.225]).view(1, 3, 1, 1).to(img_tensor.device)img = img_tensor * std + mean# 2. 裁剪到[0,1]范围img = torch.clamp(img, 0, 1)return imgdef visualize_results(losses, img_tensor):"""可视化优化过程和结果"""plt.figure(figsize=(12, 4))# 1. 绘制损失曲线plt.subplot(1, 2, 1)plt.plot(losses)plt.title('Optimization Loss')plt.xlabel('Iteration')plt.ylabel('Loss')# 2. 绘制生成图像plt.subplot(1, 2, 2)img = img_tensor.squeeze().permute(1, 2, 0).cpu().numpy()plt.imshow(img)plt.title('Generated Image')plt.axis('off')plt.tight_layout()plt.show()# 使用示例
if __name__ == "__main__":# 示例用法(需要实际模型和目标特征)model = models.resnet50(pretrained=True).eval()target_features = torch.randn(1, 2048, 7, 7) # 模拟ResNet50最后一层特征# 提取中间层特征(需要修改模型forward)class FeatureExtractor(torch.nn.Module):def __init__(self, model):super().__init__()self.model = modelself.features = None# 注册钩子获取layer4输出model.layer4.register_forward_hook(self.save_features)def save_features(self, module, input, output):self.features = output.detach()def forward(self, x):_ = self.model(x) # 标准前向传播return self.featuresfeature_model = FeatureExtractor(model)# 运行特征反演generated_img = invert_features(model=feature_model,target_features=target_features,num_iterations=300,lr=0.05,show_progress=True)输出为:
Iter [1/300], Loss: 1.6159
Iter [51/300], Loss: 1.2094
Iter [101/300], Loss: 1.2376
Iter [151/300], Loss: 1.1462
Iter [201/300], Loss: 1.1278
Iter [251/300], Loss: 1.1206
Iter [300/300], Loss: 1.1194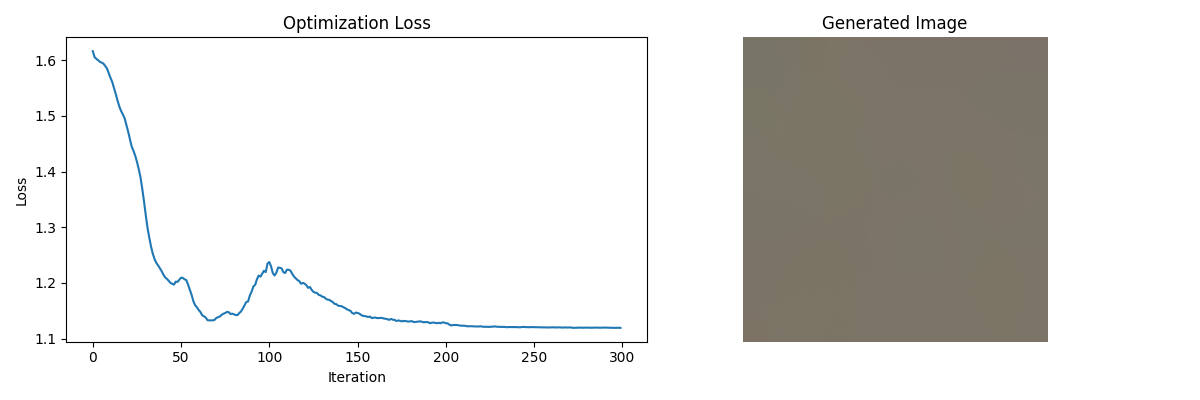
2. 概念激活向量(TCAV)
import torch
import numpy as np
from sklearn.linear_model import LogisticRegression
from tqdm import tqdm
from typing import List, Tuple
from torchvision.transforms import functional as F # 直接使用functional接口
class TCAV:def __init__(self, model: torch.nn.Module, layer_name: str):"""TCAV初始化Args:model: 目标神经网络模型layer_name: 要分析的目标层名称(如'layer4')"""self.model = modelself.layer_output = Noneself.hook = self._register_hook(layer_name)self.device = next(model.parameters()).devicedef _register_hook(self, layer_name: str):"""注册前向钩子到指定层"""def hook_fn(module, input, output):self.layer_output = output.detach()return self.model._modules[layer_name].register_forward_hook(hook_fn)def compute_concept_sensitivity(self, concept_imgs: List[torch.Tensor], random_imgs: List[torch.Tensor],n_splits: int = 5) -> Tuple[float, np.ndarray]:"""计算概念敏感度"""concept_features = self._extract_features(concept_imgs)random_features = self._extract_features(random_imgs)X = torch.cat([concept_features, random_features]).cpu().numpy()y = np.concatenate([np.ones(len(concept_features)), np.zeros(len(random_features))])accuracies, cavs = [], []for _ in range(n_splits):idx = np.random.permutation(len(X))lr = LogisticRegression(penalty='l2', C=0.01, max_iter=1000)lr.fit(X[idx], y[idx])accuracies.append(lr.score(X[idx], y[idx]))cavs.append(lr.coef_[0])return np.mean(accuracies), np.mean(cavs, axis=0)def _extract_features(self, imgs: List[torch.Tensor]) -> torch.Tensor:"""直接处理张量输入"""features = []for img in tqdm(imgs, desc='Extracting features'):if img.dim() == 3:img = img.unsqueeze(0).to(self.device)self.model(img)features.append(self.layer_output.flatten())return torch.stack(features)def __del__(self):self.hook.remove()
# 正确的预处理函数
def preprocess_tensor(img_tensor: torch.Tensor) -> torch.Tensor:"""直接对张量进行预处理"""# 1. 调整大小和裁剪img_tensor = F.resize(img_tensor, [256])img_tensor = F.center_crop(img_tensor, [224, 224])# 2. 标准化 (使用ImageNet统计量)mean = torch.tensor([0.485, 0.456, 0.406]).view(3, 1, 1)std = torch.tensor([0.229, 0.224, 0.225]).view(3, 1, 1)return (img_tensor - mean) / std
if __name__ == "__main__":import torchvision# 1. 加载模型model = torchvision.models.resnet18(weights='IMAGENET1K_V1').eval()# 2. 生成模拟数据 (直接创建预处理后的张量)def create_mock_batch(batch_size=10):imgs = torch.clamp(torch.randn(batch_size, 3, 256, 256)*0.5 + 0.5, 0, 1)return torch.stack([preprocess_tensor(img) for img in imgs])concept_imgs = create_mock_batch() # 10张概念图像random_imgs = create_mock_batch() # 10张随机图像# 3. 运行TCAVtcav = TCAV(model, 'layer4')accuracy, cav = tcav.compute_concept_sensitivity(concept_imgs=concept_imgs,random_imgs=random_imgs)print(f"分类准确率: {accuracy:.3f}")print(f"CAV维度: {cav.shape}, 范数: {np.linalg.norm(cav):.3f}")输出为:
Extracting features: 100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 10/10 [00:00<00:00, 45.63it/s]
Extracting features: 100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 10/10 [00:00<00:00, 48.76it/s]
分类准确率: 1.000
CAV维度: (25088,), 范数: 0.220四、可视化工具集成
1. Captum库实践
import torch
import numpy as np
import matplotlib.pyplot as plt
from captum.attr import IntegratedGradients, LayerGradCam, visualization as viz
from torchvision import models, transforms
from PIL import Image
import cv2 # 用于调整热力图尺寸
# 1. 加载预训练模型
model = models.resnet50(weights=models.ResNet50_Weights.IMAGENET1K_V1).eval()
# 2. 图像预处理
def preprocess_image(image_path):preprocess = transforms.Compose([transforms.Resize(256),transforms.CenterCrop(224),transforms.ToTensor(),transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]),])img = Image.open(image_path).convert('RGB')return preprocess(img).unsqueeze(0) # 添加batch维度
# 3. 可解释性分析函数
def explain_model(image_path, target_class=None):# 预处理输入input_tensor = preprocess_image(image_path)input_tensor.requires_grad = True# 获取预测类别with torch.no_grad():output = model(input_tensor)pred_class_idx = output.argmax().item() if target_class is None else target_class# 综合梯度分析ig = IntegratedGradients(model)ig_attr = ig.attribute(input_tensor, target=pred_class_idx,n_steps=50,return_convergence_delta=False)# 分层GradCAMtarget_layer = model.layer4[-1].conv3layer_gc = LayerGradCam(model, target_layer)gc_attr = layer_gc.attribute(input_tensor, target=pred_class_idx,relu_attributions=True)# 转换为适合可视化的格式input_img = np.transpose(input_tensor.squeeze().cpu().detach().numpy(), (1, 2, 0))ig_attr = np.transpose(ig_attr.squeeze().cpu().detach().numpy(), (1, 2, 0))# 处理Grad-CAM属性gc_attr = gc_attr.squeeze().cpu().detach().numpy()gc_attr = np.maximum(gc_attr, 0) # 只保留正激活gc_attr = (gc_attr - gc_attr.min()) / (gc_attr.max() - gc_attr.min() + 1e-8) # 归一化return input_img, ig_attr, gc_attr, pred_class_idx
# 4. 可视化函数
def visualize_attributions(input_img, ig_attr, gc_attr, class_idx, class_names=None):fig, ax = plt.subplots(1, 3, figsize=(18, 6))# 原始图像orig_img = input_img * np.array([0.229, 0.224, 0.225]) + np.array([0.485, 0.456, 0.406])orig_img = np.clip(orig_img, 0, 1)ax[0].imshow(orig_img)# 安全获取类别名称class_name = "unknown"if class_names is not None and class_idx in class_names:class_name = class_names[class_idx]elif class_names is None:class_name = str(class_idx)ax[0].set_title(f'Original Image\nPredicted: {class_name}')ax[0].axis('off')# 综合梯度viz.visualize_image_attr(ig_attr, orig_img,method='blended_heat_map',sign='absolute_value',show_colorbar=True,title='Integrated Gradients',plt_fig_axis=(fig, ax[1]))# Grad-CAM 可视化# 将7x7的热力图放大到224x224heatmap = cv2.resize(gc_attr, (orig_img.shape[1], orig_img.shape[0]))heatmap = np.uint8(255 * heatmap)heatmap = cv2.applyColorMap(heatmap, cv2.COLORMAP_JET)heatmap = cv2.cvtColor(heatmap, cv2.COLOR_BGR2RGB) / 255.0 # 转换为RGB并归一化# 叠加热力图和原始图像superimposed = heatmap * 0.5 + orig_img * 0.5ax[2].imshow(superimposed)ax[2].set_title('Layer Grad-CAM')ax[2].axis('off')plt.tight_layout()plt.savefig('model_explanations.png', bbox_inches='tight', dpi=300)plt.show()
# 5. 使用示例
if __name__ == "__main__":# 定义猫类别(可选)cat_classes = {281: "Egyptian_cat",282: "tabby_cat",283: "tiger_cat",284: "Persian_cat",285: "Siamese_cat"}# 分析示例图像image_path = 'cat.jpeg' # 替换为你的图像路径input_img, ig_attr, gc_attr, pred_class = explain_model(image_path)# 可视化结果visualize_attributions(input_img, ig_attr, gc_attr, pred_class, cat_classes)输出为:
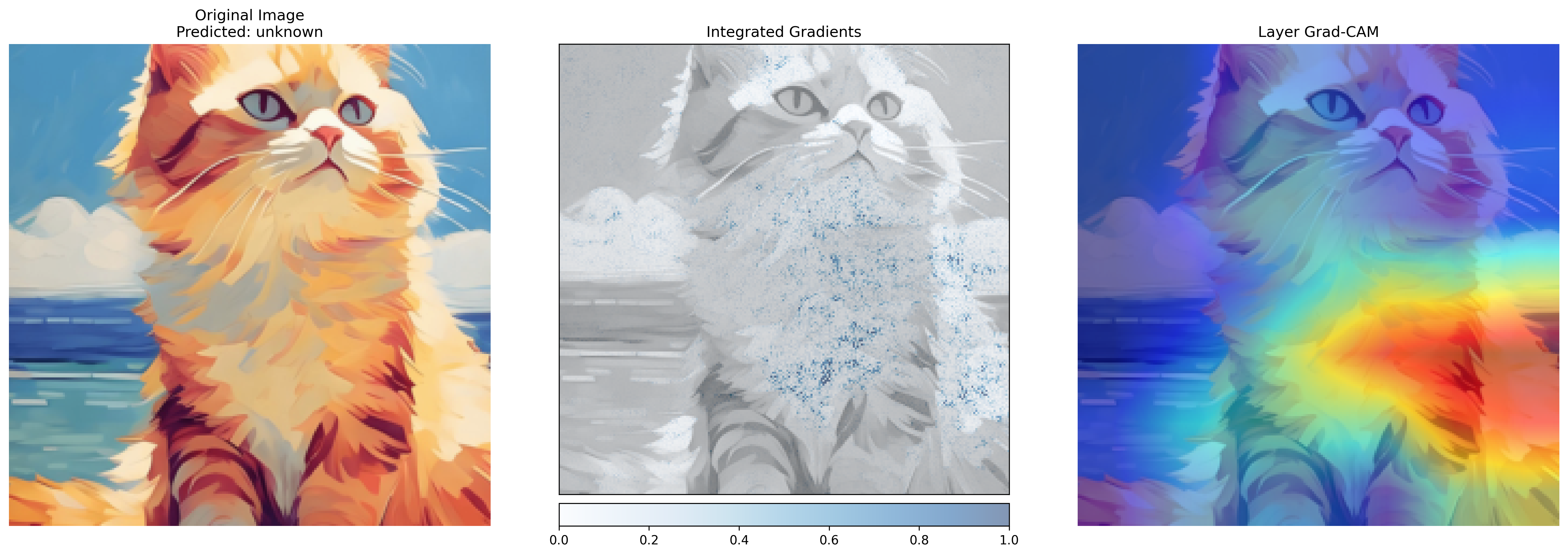
2. 交互式可视化(PyTorch+Plotly)
import numpy as np
import plotly.express as px
import plotly.graph_objects as go
from torchvision import models, transforms
from PIL import Image
def interactive_heatmap(attr, original_img):"""生成交互式热力图可视化参数:attr: 归因图 (H,W)或(H,W,1)original_img: 原始图像 (H,W,3)"""# 确保attr是2维的if attr.ndim == 3:attr = attr.squeeze()
# 创建热力图fig = px.imshow(attr,color_continuous_scale='RdBu',range_color=[-np.abs(attr).max(), np.abs(attr).max()],zmin=-3, # 标准化显示范围zmax=3,title="Interactive Attribution Heatmap")
# 添加原始图像半透明叠加fig.add_trace(go.Image(z=(original_img * 255).astype(np.uint8),opacity=0.5))
# 优化布局fig.update_layout(width=800,height=600,coloraxis_showscale=True,hovermode='closest',xaxis_showgrid=False,yaxis_showgrid=False)
# 添加滑块控制透明度fig.update_layout(sliders=[{'steps': [{'method': 'restyle','args': ['opacity', [val]],'label': f'{val:.1f}'} for val in np.arange(0.1, 1.1, 0.1)],'active': 4,'currentvalue': {'prefix': 'Opacity: '}}])
# 添加热力图/原始图切换按钮fig.update_layout(updatemenus=[{'buttons': [{'method': 'update','args': [{'visible': [True, False]},{'title': 'Heatmap Only'}],'label': 'Heatmap'},{'method': 'update','args': [{'visible': [False, True]},{'title': 'Original Only'}],'label': 'Original'},{'method': 'update','args': [{'visible': [True, True]},{'title': 'Combined View'}],'label': 'Combined'}],'direction': 'down','showactive': True,}])import osprint(os.getcwd())fig.write_html("interactive_heatmap.html")fig.show()
# 使用示例
if __name__ == "__main__":# 1. 加载模型和图像model = models.resnet50(weights=models.ResNet50_Weights.IMAGENET1K_V1).eval()preprocess = transforms.Compose([transforms.Resize(256),transforms.CenterCrop(224),transforms.ToTensor(),transforms.Normalize(mean=[0.485, 0.456, 0.406],std=[0.229, 0.224, 0.225]),])
# 2. 加载示例图像img_path = 'cat.jpeg'img = Image.open(img_path).convert('RGB')img_tensor = preprocess(img).unsqueeze(0)
# 3. 生成归因图 (示例使用随机数据)original_img = np.array(img.resize((224, 224))) / 255.0attr = np.random.randn(224, 224) * 2 # 模拟归因图
# 4. 交互式可视化interactive_heatmap(attr, original_img)输出为:

五、多模态解释实践
1. 视觉-语言联合解释
import torch
import numpy as np
import matplotlib.pyplot as plt
from PIL import Image
from transformers import ViTImageProcessor, ViTModel
import torch.nn.functional as F
import plotly.graph_objects as go
from plotly.subplots import make_subplots# 初始化ViT模型和特征提取器
feature_extractor = ViTImageProcessor.from_pretrained('google/vit-base-patch16-224')
vit = ViTModel.from_pretrained('google/vit-base-patch16-224', output_attentions=True)
patch_size = 16 # ViT-base的默认patch大小def visualize_attention(img_path, layer_index=-1, head_index=None):"""可视化ViT的注意力图参数:img_path: 图像路径layer_index: 要可视化的层索引(-1表示最后一层)head_index: 特定注意力头索引(None表示平均所有头)"""# 1. 图像预处理img = Image.open(img_path).convert('RGB')inputs = feature_extractor(images=img, return_tensors="pt")# 2. 前向传播获取注意力with torch.no_grad():outputs = vit(**inputs)# 3. 处理注意力图attentions = outputs.attentions[layer_index] # 获取指定层的注意力if head_index is not None:attn = attentions[0, head_index] # 选择特定头 [1, num_heads, num_patches, num_patches]else:attn = attentions.mean(dim=1)[0] # 平均所有头 [1, num_patches, num_patches]# 聚焦于CLS token对其他patch的关注 (位置0是CLS token)cls_attn = attn[0, 1:] # 忽略CLS token自身的注意力# 4. 重塑并上采样注意力图grid_size = int(np.sqrt(cls_attn.shape[-1]))cls_attn = cls_attn.reshape(grid_size, grid_size)cls_attn = F.interpolate(cls_attn[None, None],size=img.size[1], # 假设是正方形图像mode='bicubic')[0, 0].numpy()# 5. 可视化fig = make_subplots(rows=1, cols=2, subplot_titles=("Original Image", "Attention Heatmap"))# 原始图像fig.add_trace(go.Image(z=np.array(img)),row=1, col=1)# 注意力热力图fig.add_trace(go.Heatmap(z=cls_attn,colorscale='jet',showscale=True,opacity=0.7),row=1, col=2)# 叠加图fig.add_trace(go.Heatmap(z=cls_attn,colorscale='jet',showscale=False,opacity=0.5),row=1, col=1)# 布局调整fig.update_layout(title_text=f"ViT Attention Visualization (Layer {layer_index})",height=500,width=1000,hovermode='closest')# 添加滑块选择不同层if len(outputs.attentions) > 1:steps = []for i in range(len(outputs.attentions)):steps.append({'method': 'update','args': [{'z': [None, process_attn(outputs.attentions[i])]},{'title': f"ViT Attention (Layer {i})"}],'label': f'Layer {i}'})fig.update_layout(sliders=[{'active': layer_index if layer_index >= 0 else len(outputs.attentions) - 1,'steps': steps,'currentvalue': {'prefix': 'Selected Layer: '}}])fig.show()return cls_attndef process_attn(attention, head_index=None):"""处理注意力矩阵的辅助函数"""if head_index is not None:attn = attention[0, head_index]else:attn = attention.mean(dim=1)[0]cls_attn = attn[0, 1:]grid_size = int(np.sqrt(cls_attn.shape[-1]))cls_attn = cls_attn.reshape(grid_size, grid_size)cls_attn = F.interpolate(cls_attn[None, None],size=224,mode='bicubic')[0, 0].numpy()return cls_attn# 使用示例
if __name__ == "__main__":# 可视化最后一层的平均注意力attention_map = visualize_attention(img_path="cat.jpeg", # 替换为你的图片路径layer_index=-1, # 最后一层head_index=None # 平均所有头)# 也可以保存注意力图plt.imsave("attention_heatmap.png", attention_map, cmap='jet')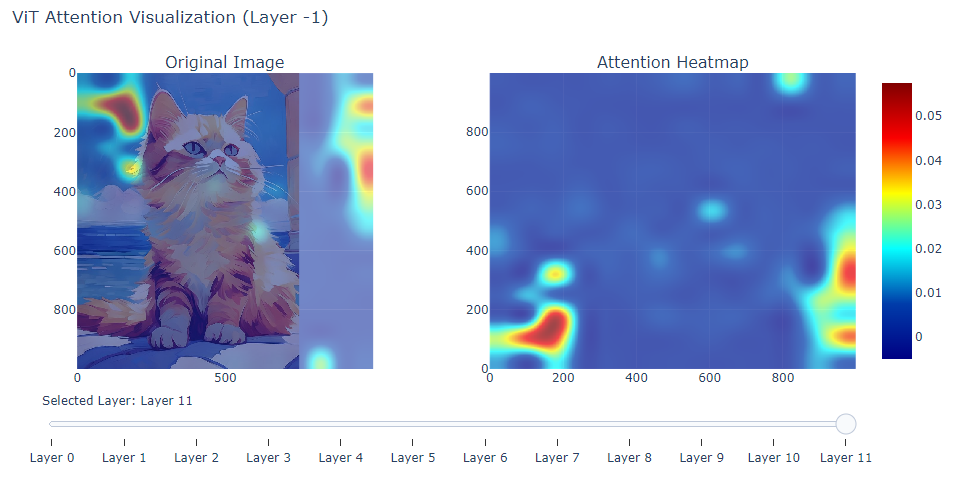
六、总结与展望
本文介绍了以下核心技术:
-
基础可视化方法:Saliency Map、Grad-CAM
-
高级解释技术:特征反演、概念激活分析
-
工具链集成:Captum、Plotly交互可视化
-
多模态解释:视觉-语言联合注意力机制
在下一篇文章《多模态学习与CLIP模型》中,我们将探索如何联合理解视觉和语言信息。
关键工具推荐:
pip install captum torchcam tf-explain应用建议:
-
模型调试阶段使用Grad-CAM定位错误原因
-
产品部署时集成LIME生成局部解释
-
伦理审查时采用TCAV验证公平性