做网站需要资质如何网站推广
一、服务器配置
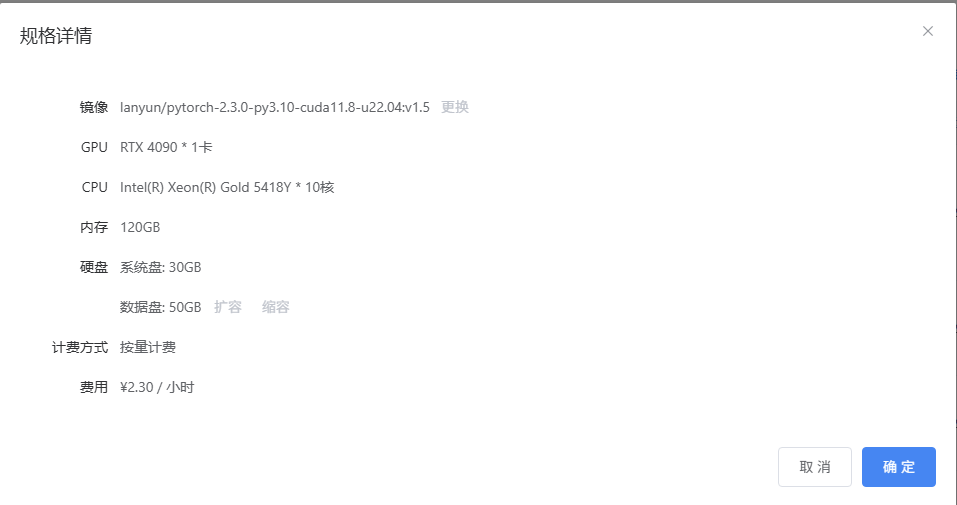
二、安装Anaconda3
进入云服务器后删除minconda文件夹
官网: https://repo.anaconda.com/archive/
在里面找到自己系统的安装包,然后右击复制链接安装。
一定要选择Anaconda,因为很多依赖问题用Minconda容易报错。
wget https://repo.anaconda.com/archive/Anaconda3-2024.10-1-Linux-x86_64.sh
进入到存放 Anaconda3-2024.10-1-Linux-x86_64.sh的文件下解压
bash Anaconda3-2024.10-1-Linux-x86_64.sh
创建和激活虚拟环境,建议用python3.10,因为我们用的最新版本的框架,不然会遇到如下报错。
conda create -n ppstructureV3 python=3.10 -y
conda activate ppstructureV3
 这是由 Python 3.8 的类型注解限制 导致的。在Python 3.9之前的版本中,原生类型(如list、dict)不能直接使用下标语法(如list[int]),必须使用typing模块中的泛型类型(如List[int])
这是由 Python 3.8 的类型注解限制 导致的。在Python 3.9之前的版本中,原生类型(如list、dict)不能直接使用下标语法(如list[int]),必须使用typing模块中的泛型类型(如List[int])
三、安装paddlepaddle
参考安装官网:
使用教程 - PaddleOCR 文档
安装 - PaddleOCR 文档
3.1 查看系统最高支持的cuda版本
nvidia-smi
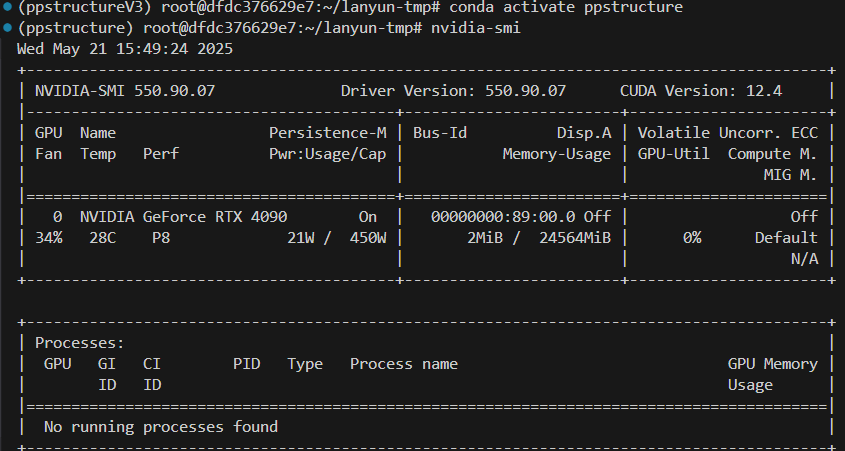
我的系统cuda支持最高版本12.4,cuda可以向下兼容,所以选择11.8版本的,不能选12.6
我们去官网开始使用_飞桨-源于产业实践的开源深度学习平台下载最新的3.0的版本paddlepaddle,一定要下载3.0的才有最新的ppstructureV3
python -m pip install paddlepaddle-gpu==3.0.0 -i https://www.paddlepaddle.org.cn/packages/stable/cu118/
3.2 安装paddleocr最新版(目前是3.0)
python -m pip install paddleocr # 默认是最新的
或者从源码安装(默认为开发分支):
python -m pip install "git+https://github.com/PaddlePaddle/PaddleOCR.git"
3.3 检测是否安装好相关环境
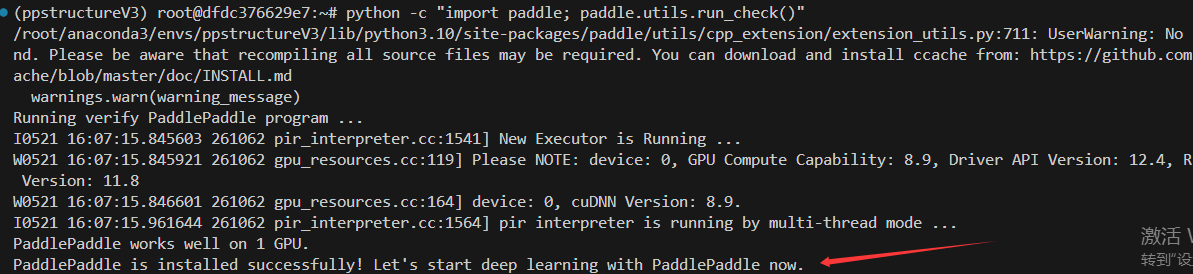
python -c "import paddle; paddle.utils.run_check()"
PaddlePaddle is installed successfully! Let's start deep learning with PaddlePaddle now. 说明 paddlepaddle-gpu安装成功。
四、图片测试
4.1 一行代码快速测试
paddleocr pp_structurev3 -i https://paddle-model-ecology.bj.bcebos.com/paddlex/imgs/demo_image/pp_structure_v3_demo.png
https://paddle-model-ecology.bj.bcebos.com/paddlex/imgs/demo_image/pp_structure_v3_demo.png
测试图片原图
 识别效果:
识别效果:

4.2 python角本测试本地的带框表格图片
新建3.py 和 png 文件保存图片
from paddleocr import PPStructureV3
import time # 新增导入time模块
# 初始化模型(此步骤耗时不计入推理时间)
pipeline = PPStructureV3(device="gpu")
# 开始计时(精确到微秒级)
start_time = time.perf_counter() # 网页1/网页2/网页5推荐的高精度计时方式
# 执行推理
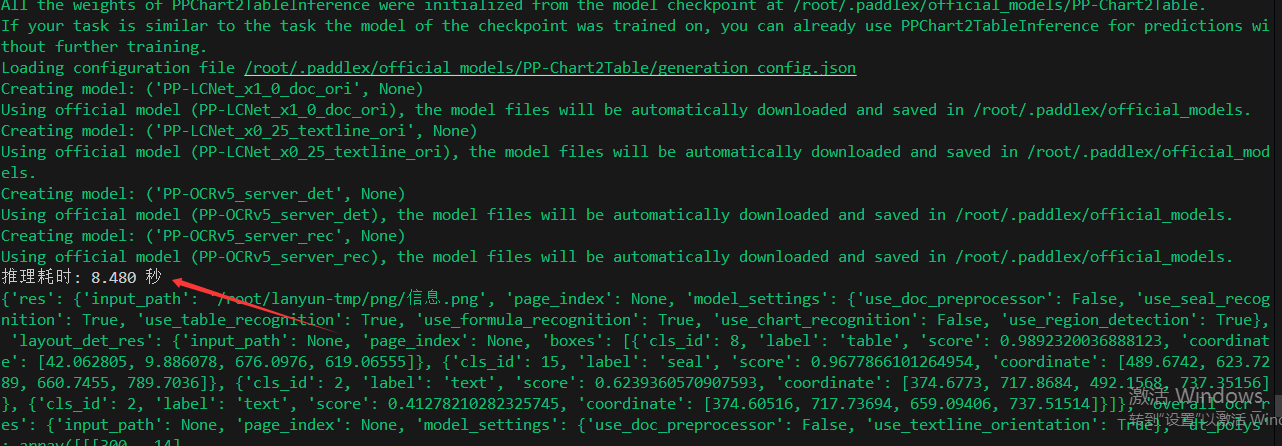
output = pipeline.predict(r"/root/lanyun-tmp/png/信息.png")
# 结束计时并计算差值
elapsed = time.perf_counter() - start_time # 网页6提到的精度控制方法
# 打印三位小数秒数(格式化为xxx.xxx秒)
print(f"推理耗时: {elapsed:.3f} 秒") # 网页6中.3f实现三位小数
# 结果处理
for res in output:
res.print()
res.save_to_json(save_path="/root/lanyun-tmp/output")
res.save_to_markdown(save_path="/root/lanyun-tmp/output")
测试图片:

输出结果:

用md工具打开那个文件可以看到,识别的准确度很高,仅仅序号7识别错了,但是印章信息还是不能识别,后续可能要用专门的印章识别工具。

推理用时:8.48秒 速度很慢,相比ppocr同用文字识别的0.5s
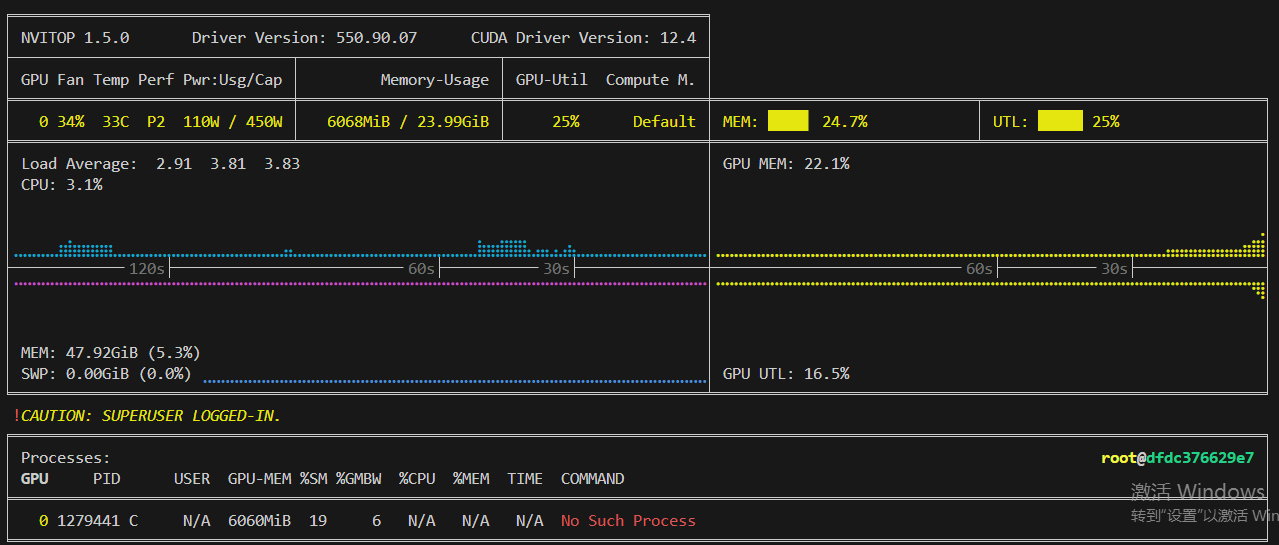
资源使用情况:峰值 5 G (可以新开一个终端 pip install nvitop下载一个资源监控包,如何新的终端运行nvitop专门做资源检测终端)
4.3 测试4.1的非洲图片识别效果

4.4 测试公式图片
原图:

测试输出的md格式:

4.5 测试无框的身份证信息图片
测试图片:

输出的md格式:
推理耗时: 6.980 秒
可以看到,输出的内容模糊的还是看不到,但是比ppocr的输出结果好一点,至少输出内容语义没有断开。
五、PDF文件识别
参考官方代码修改得到下面代码
# 导入必要的模块
from pathlib import Path # 用于处理文件路径
from paddleocr import PPStructureV3 # PaddleOCR的V3版文档结构分析模型
import time # 新增导入time模块(当前代码中未使用,可能计划用于性能计时)
# 设置输入文件路径和输出目录
input_file = r"/root/lanyun-tmp/png/your_pdf.pdf" # 需要处理的PDF文件路径
output_path = Path("/root/lanyun-tmp/output_pdf") # 输出目录的Path对象
# 初始化PPStructureV3文档分析流水线
pipeline = PPStructureV3()
start_time = time.perf_counter() # 记录推理开始时间
# 对输入文件进行结构化分析,获取包含文本和布局信息的输出结果
output = pipeline.predict(r"/root/lanyun-tmp/png/your_pdf.pdf")
end_time = time.perf_counter() # 记录推理结束时间
# 打印推理耗时(单位:秒,保留3位小数)
print(f"\n[推理耗时] {end_time - start_time:.3f} 秒\n")
# 初始化存储Markdown内容和图片的列表
markdown_list = [] # 存储各页面的Markdown信息
markdown_images = [] # 存储各页面的图片数据
# 遍历处理每个页面的分析结果
for res in output:
# 获取当前页面的Markdown格式信息
md_info = res.markdown
markdown_list.append(md_info) # 将Markdown信息添加到列表
# 提取当前页面的图片数据(如果有的话),并添加到图片列表
markdown_images.append(md_info.get("markdown_images", {}))
print(markdown_list) # 测试有没有每一页的md信息
# 将多页的Markdown内容合并为完整的文档
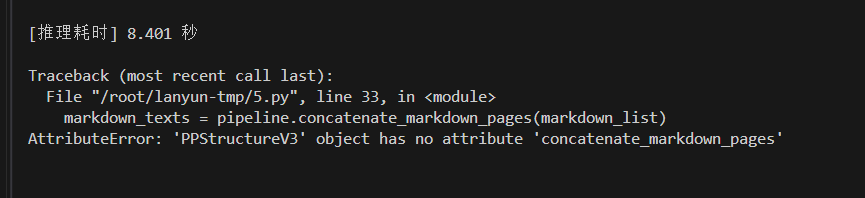
# markdown_texts = pipeline.concatenate_markdown_pages(markdown_list)
# 手动合并多页Markdown内容
markdown_texts = "\n\n".join([
page_res["markdown_text"]
for page_res in markdown_list
if page_res.get("markdown_text")
])
# 构建输出Markdown文件路径(保持与原文件同名,后缀改为.md)
mkd_file_path = output_path / f"{Path(input_file).stem}.md"
mkd_file_path.parent.mkdir(parents=True, exist_ok=True) # 确保输出目录存在
# 将合并后的Markdown内容写入文件
with open(mkd_file_path, "w", encoding="utf-8") as f:
f.write(markdown_texts)
# 处理并保存文档中的图片
for item in markdown_images:
if item: # 检查是否存在图片数据
for path, image in item.items(): # 遍历图片路径和图片对象
file_path = output_path / path # 构建完整图片保存路径
file_path.parent.mkdir(parents=True, exist_ok=True) # 创建图片存储目录
image.save(file_path) # 保存图片到指定路径
注意 # markdown_texts = pipeline.concatenate_markdown_pages(markdown_list),我们最新版的也会出现下面的报错,应该是移除了这个函数。所以注释掉官方代码,重新写一个。
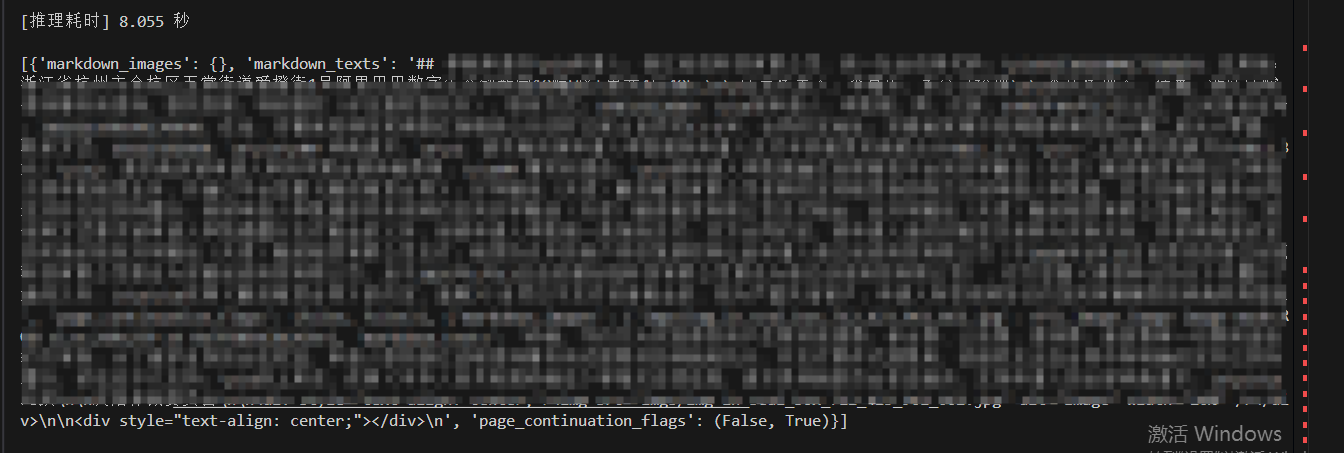
识别效果:时间8.055秒
资源使用情况:
六、总结
1. PP-StructureV3 的效果还可以尤其是对版面信息、有框图表格的识别效果。
2. 推理时间较长,后续看看百度的加速推理框架。
3. 对于身份证、营业执照等信息的抽取还是不行、后续看看 PP-Structure的kie模块。