相应式网站网站建设云浪科技
thinking:做一个项目
1,业务背景,价值
2,方法,工具
3,实践(现有的代码,改写的代码)
cursor编程有个cursor settings ->privacy mode隐私模式,但是只要连上服务器就有隐私泄露风险
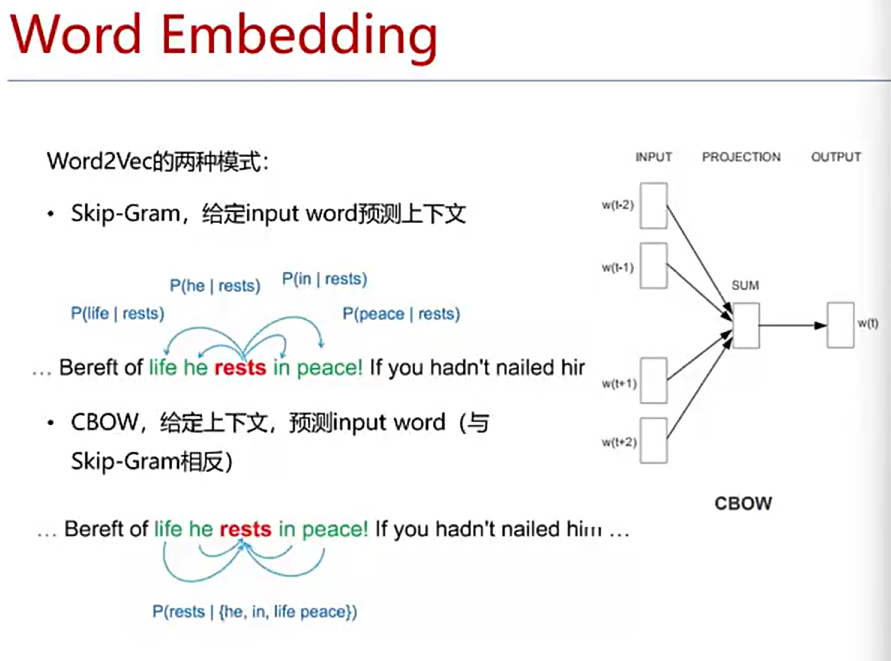
本章节主要围绕Embedding开始
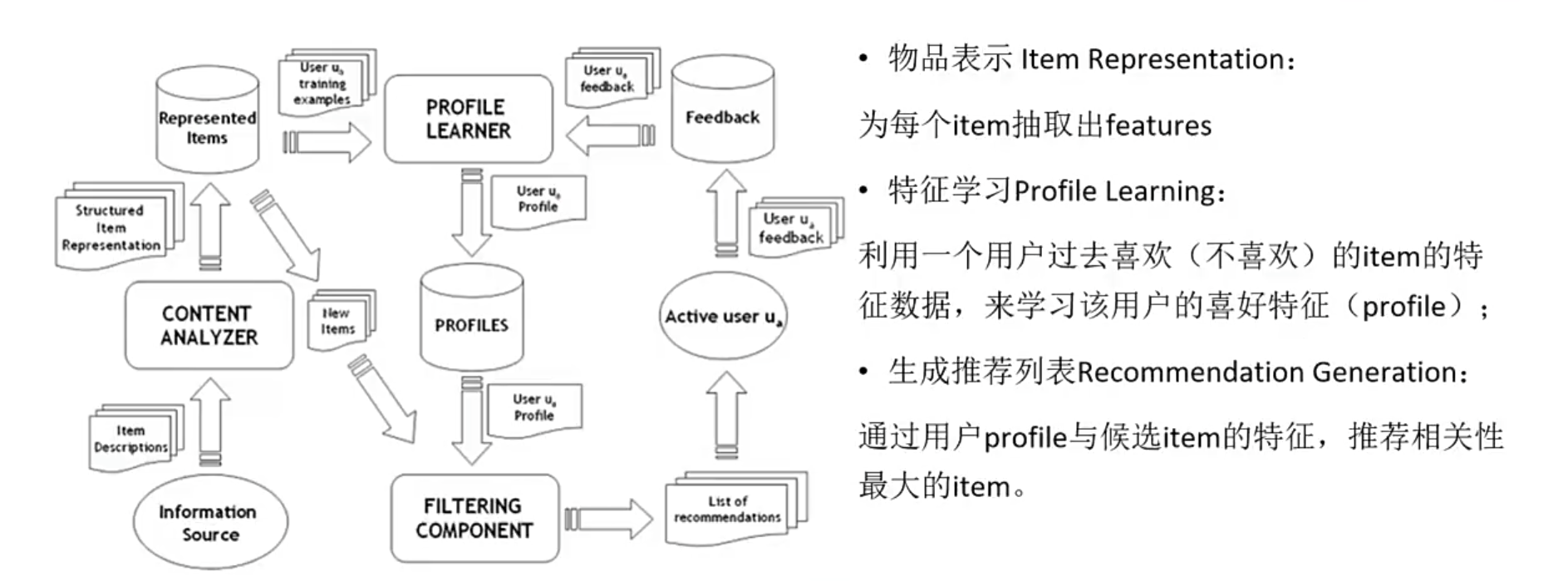
简述
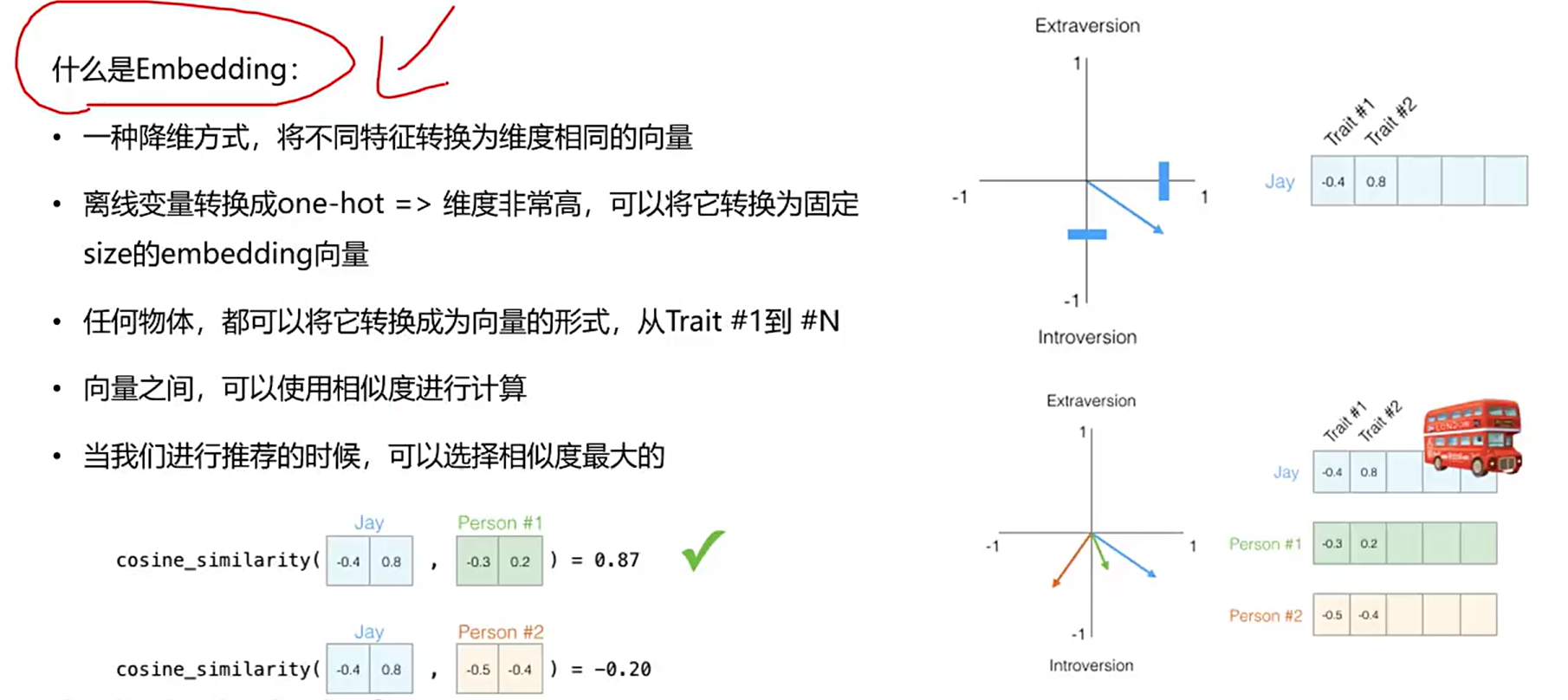
什么是Embedding
CASE:基于内容的推荐
什么是N-Gram
余弦相似度计算
为酒店建立内容推荐系统
Word Embedding
什么事Embedding
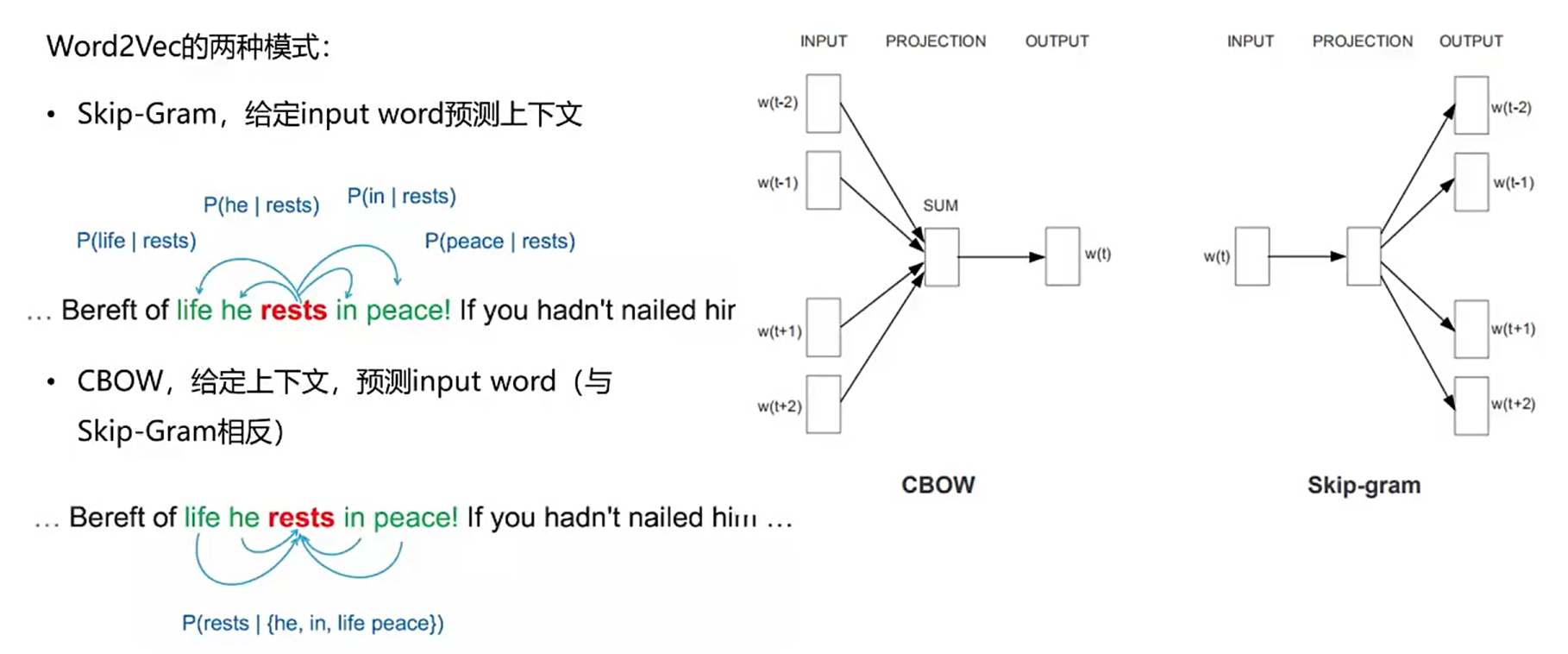
Word2Vec进行词向量训练
向量数据库
什么是向量库
FAISS(Facebook开源),Milvus,Pinecone的特点
向量数据库与传统数据库的对比
Embedding
基于内容的推荐:依赖性低,不需要动态的用户行为,只要有内容就可以进行推荐
系统不同阶段都可以应用:
系统冷启动,内容是任何系统天生的属性,可以从中挖掘到特征,实现推荐系统的冷启动,一个复杂的推荐系统是从基于内容的推荐成长起来的。
商品冷启动,不论什么阶段,总会有新的物品加入,这时只要有内容信息,就可以帮它进行推荐
了解Embedding可以从了解物体的特征表达开始
Thinking:如果一个用户点击了某个酒店,我们怎么给这个用户推荐其他类似的酒店?
特征:价格,位置,距离,描述(高端,wifi,游泳池)
这些特征方式可以用向量做表达,假设一个酒店有10个特征[x1,x2...x10],推荐另个酒店[y1,y2...y10],用俩个向量的夹角余弦值度量他们的相似性

举个例子


others:python中文库jieba用来分词,RAG检索增强
1)向量特征只是做词频重复度,但是没考虑词序,所以为了捕捉语义词序的位置引出了N-Gram

一般采用1~4元的语法=>如果N-gram中N很大,那么特征数量就会特别多=>就会让我们的矩阵大小特别大,维度会爆炸,
1-4元语法,是累加1到4的概念,
代码里先进性英语停用词枚举避免高频率且意义不大的词汇带来影响,希望去除掉
N元语法特征表示方式,作用是对酒店内容的特征提取,1元+2元+3元的特征量,数量=3347维向量表达,会有很多为0情况,
CountVectorizer:
将文本中的词语转换为词频矩阵
fit_transform:计算各个词语出现的次数
get_feature_names:可获得所有文本的关键
toarray():查看词频矩阵的结果

基于内容的推荐:
Step1,对酒店描述(Desc)进行特征提取
N-Gram,提取N个连续字集合,作为特征
TF-IDF,按照(min_df,max_df)提取关键词,并生成TFIDF矩阵
Step2,计算酒店之间的相似矩阵
余弦相似度
Step3,对于指定的酒店,选择相似度最大的Top-K个酒店进行输出
2)N-Gram+TF-IDF的特征表达会让特征矩阵非常系数,计算量大,有没有更适合的方式?
特征压缩 Embedding,可以想象成一床棉被被压缩到行李箱里面
Embedding is all you need!=>万事万物都可以用Embedding进行向量表达很多的语料,喂给了机器,让机器从中间学习这些单词的特征=>得到Embedding
现在有很多大模型的embedding维度都是1000+
谷歌的Word2Vec,自监督学习
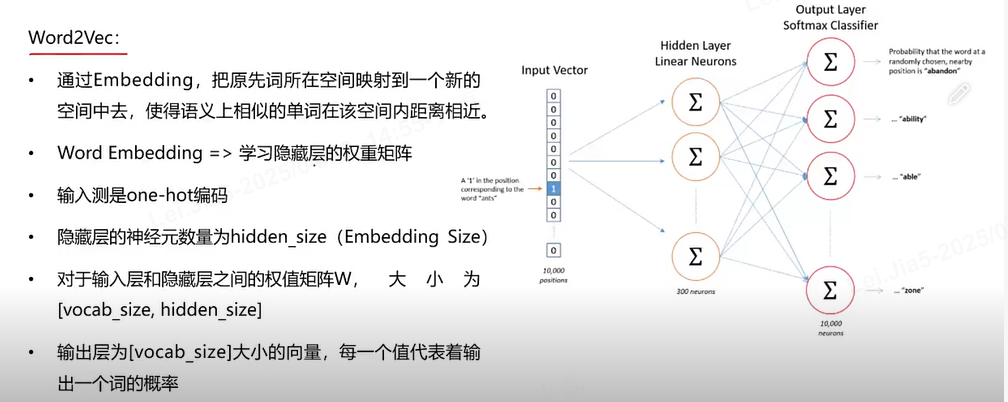
万事万物向量化,我们让AI学到的是word embedding,给它原始的input和output,原始的input是英文的百科全书,output是标记(这个单词在周边出现的概率)
i love eating apple
apple俩边单词的概率是多少?key类似查字典得出单词的多维特征向量维度(维度=特征个数)
banana俩边单词的概率是多少?
维度大,准确度大,相似度大,但矩阵运算耗费资源,存储也一样

举例说明这个Word2Vec工具
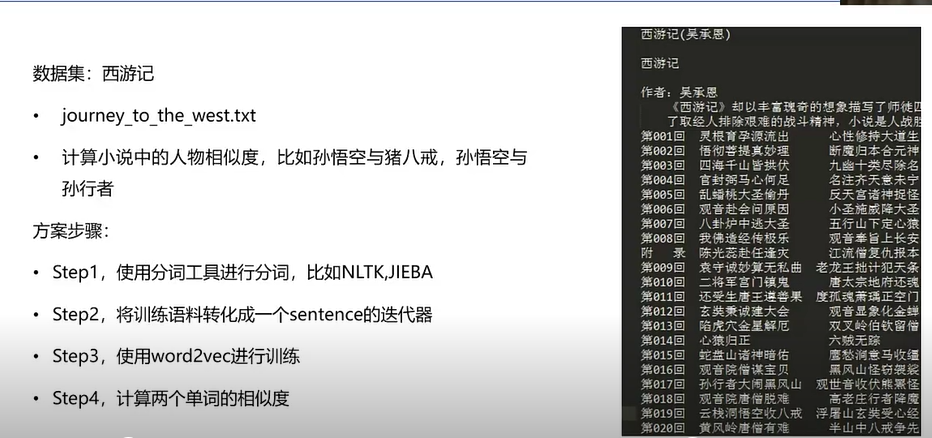
先分割:
后计算相似度:
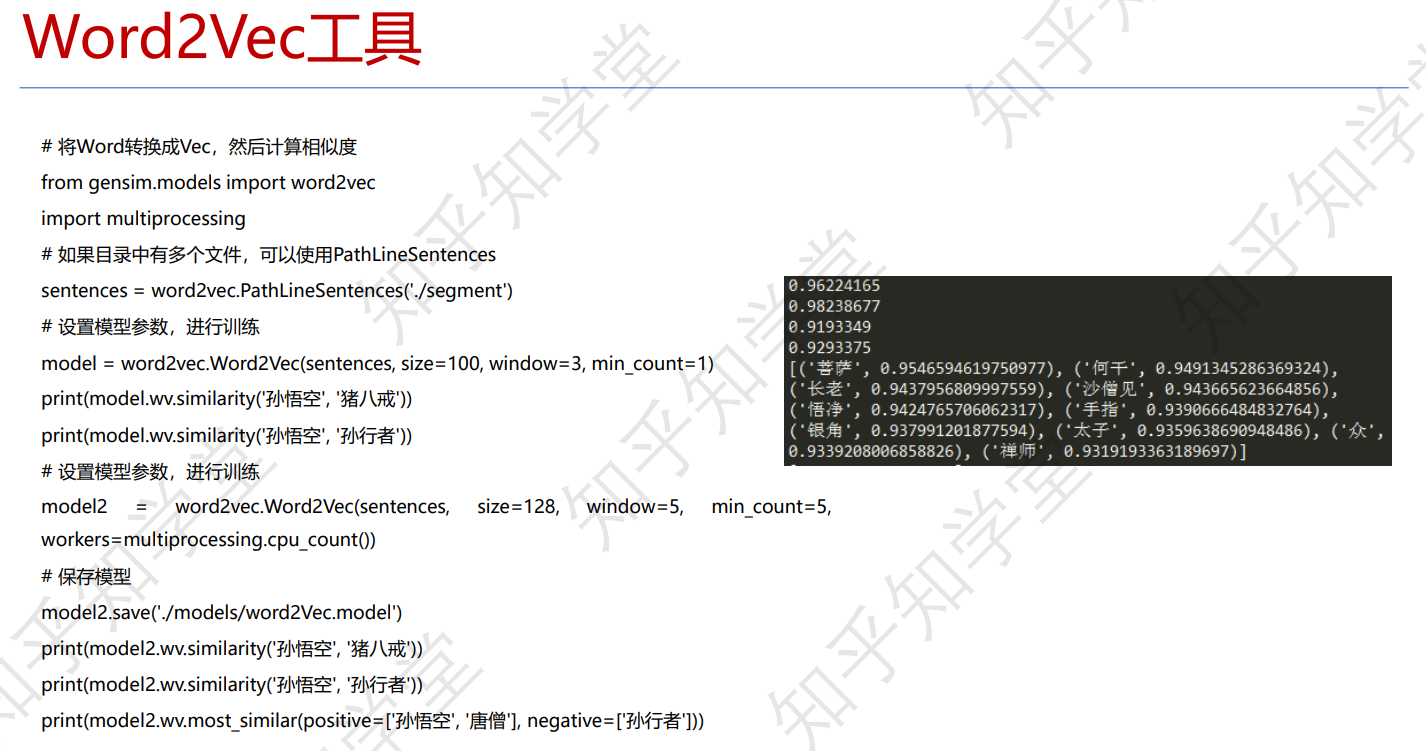
Thinking:得到了特征表达(item representation),有什么用?
基于内容的推荐:
• 将你看的item,相似的item推荐给你
• 通过物品表示Item Representation => 抽取特征
TF-IDF => 返回给某个文本的“关键词-TF-IDF值”的词数对
TF-IDF可以帮我们抽取文本的重要特征,做成item embedding
Thinking:如何使用事物的特征表达,进行相似推荐?
• 计算item之间的相似度矩阵
• 对于指定的item,选择相似度最大的Top-K个进行输出
如果缺少jieba或者gensim工具箱,在命令行cmd模式下运行
pip install jieba -i htttps://pypi.tuna.tsinghua.edu.cn/simple
pip install gensim -i htttps://pypi.tuna.tsinghua.edu.cn/simple
1)推理大模型=>我们给它prompt,他们给response
CherryStudio
deepseek:是推理大模型
2)语义理解模型(嵌入模型,Embedding模型)帮你找相似片段的类似
bgem3是语义模型对语义进行向量化
Embedding排行榜,语义理解
可以在huggingface.co外网有huggingface.co/spaces/mteb/leaderboard
3)视觉大模型,dino
结构化数据库 MySQL =>存储量 结构化的Excel数据=>检索的是精确的检索;
SELECT*FROM ... where...
向量数据库=>存储的向量 更加高效

常见的数据库

向量数据库与传统数据库的对比
| 传统数据库 | 向量数据库 | |
| 数据类型 | 存储结构化数据(如表格,行,列) | 存储高维向量数据,适合非结构化数据 |
| 查询方式 | 依赖精确匹配(如=,<,>) | 基于相似度或距离度量(如欧几里得距离,余弦相似度) |
| 应用场景 | 适合事务记录和结构化信息管理 | 适合语义搜索,内容推荐等需求相似性计算的场景 |
传统数据库的检索=>一般是检索确定的信息,比如查找XX工号的XXX信息
向量数据库=>不是检索确定的信息,而是语义上类似的内容
例如:用户提问:XXX故障如何处理
1)如果你知道故障的代码=>结构化数据,很精确的查找
Text2SQL
2)向量数据库=>召回多个相似的信息(比如5个详细的内容)
RAG
如果有10亿信息
1)模糊查询like=>速度很慢
2)faiss =>300ms
pip install faiss-cpu
pip install faiss-gpu
用向量数据库来存储
数据库是用于存储和检索数据的,更像是外挂的知识库
大模型是用于推理的,大模型通过数据训练,对知识有一些了解
向量库的呈现方式是怎样的?
向量库的呈现方式是怎样的
word embedding =>会用3072个维度进行表达(在gemini-embedding)
chunk(切片会有很多的文字,比如500字)=>3072维
chunk1 500字=>3072
chunk2 100字=>3072
chunk3 10字=>3072 因为chunk最小的存储单元
1)原始文本chunk 500字
2)原始文本对应的embedding语义理解3072维