网站首页的概念wordpress未收到验证码
概述
前文写了下 MinerU 的解析效果,收到不少读者催更,想利用 MinerU 替换 Deepdoc 的原始的解析器。
我认为,开发新功能基本可遵循能用-好用-用好这三个阶段:
-
能用:先通过脚本实现该功能,主打的是能用就行
-
好用:不仅能够满足需求,而且搭配简洁易操作的界面,方便用户无需编程也能操作
-
用好:考虑可拓展性,进一步满足日益变化的新需求。
本文借助 MinerU 和 Ragflow 的原生接口,实现 MinerU 对指定文件进行解析,批量插入解析块,先实现能用的阶段。
MinerU 解析文档接口
首先看一下 MinerU 的API文档,地址如下:
https://mineru.readthedocs.io/en/latest/user_guide/usage/api.html
翻译成中文注释,方便理解:
import os# 导入必要的模块和类
from magic_pdf.data.data_reader_writer import FileBasedDataWriter, FileBasedDataReader
from magic_pdf.data.dataset import PymuDocDataset
from magic_pdf.model.doc_analyze_by_custom_model import doc_analyze
from magic_pdf.config.enums import SupportedPdfParseMethod# 参数设置
pdf_file_name = "small_ocr.pdf" # 要处理的PDF文件路径,使用时替换为实际路径
name_without_suff = pdf_file_name.split(".")[0] # 去除文件扩展名# 准备环境
local_image_dir, local_md_dir = "output/images", "output" # 图片和输出目录
image_dir = str(os.path.basename(local_image_dir)) # 获取图片目录名# 创建输出目录(如果不存在)
os.makedirs(local_image_dir, exist_ok=True)# 初始化数据写入器
image_writer, md_writer = FileBasedDataWriter(local_image_dir), FileBasedDataWriter(local_md_dir
)# 读取PDF文件内容
reader1 = FileBasedDataReader("") # 初始化数据读取器
pdf_bytes = reader1.read(pdf_file_name) # 读取PDF文件内容为字节流# 处理流程
## 创建PDF数据集实例
ds = PymuDocDataset(pdf_bytes) # 使用PDF字节流初始化数据集## 推理阶段
if ds.classify() == SupportedPdfParseMethod.OCR:# 如果是OCR类型的PDF(扫描件/图片型PDF)infer_result = ds.apply(doc_analyze, ocr=True) # 应用OCR模式的分析## 处理管道pipe_result = infer_result.pipe_ocr_mode(image_writer) # OCR模式的处理管道else:# 如果是文本型PDFinfer_result = ds.apply(doc_analyze, ocr=False) # 应用普通文本模式的分析## 处理管道pipe_result = infer_result.pipe_txt_mode(image_writer) # 文本模式的处理管道### 绘制模型分析结果到每页PDF
infer_result.draw_model(os.path.join(local_md_dir, f"{name_without_suff}_model.pdf"))### 获取模型推理结果
model_inference_result = infer_result.get_infer_res()### 绘制布局分析结果到每页PDF
pipe_result.draw_layout(os.path.join(local_md_dir, f"{name_without_suff}_layout.pdf"))### 绘制文本块(span)分析结果到每页PDF
pipe_result.draw_span(os.path.join(local_md_dir, f"{name_without_suff}_spans.pdf"))### 获取Markdown格式的内容
md_content = pipe_result.get_markdown(image_dir) # 包含图片相对路径### 保存Markdown文件
pipe_result.dump_md(md_writer, f"{name_without_suff}.md", image_dir)### 获取内容列表(JSON格式)
content_list_content = pipe_result.get_content_list(image_dir)### 保存内容列表到JSON文件
pipe_result.dump_content_list(md_writer, f"{name_without_suff}_content_list.json", image_dir)### 获取中间JSON格式数据
middle_json_content = pipe_result.get_middle_json()### 保存中间JSON数据
pipe_result.dump_middle_json(md_writer, f'{name_without_suff}_middle.json')
输出的output文件夹中一共会输出以下几个文件:
- images: 存储提取出来图像信息
- *.md:合成的md文件
- *_content_list.json: 切块信息
- *_middle.json:ocr之后的中间状态,里面包含了每个内容块的bbox、score等信息
- *_model.pdf:模型分析结果,具体分析哪些是图、哪些是表、哪些是文本信息
- *_layout.pdf:布局分析结果,分析哪些部分是真正需要被解析的
- *_spans.pdf: 文本块(span)分析结果
在测试时,发现MinerU会自动将论文的页眉和页脚进行剔除,对于标题和正文也会有单独区分,这得益于布局分析的结果,这意味着content_list.json本身包含的就是较为纯净的文本块信息,无需再进行复杂的数据清洗。

Ragflow 添加解析块接口
本系列的第5篇文章对 Ragflow 的 python API 接口进行解析,其中,有个接口可以直接向指定知识库的文档手动添加解析快内容:
from ragflow_sdk import RAGFlowapi_key = "ragflow-I0NmRjMWNhMDk3ZDExZjA5NTA5MDI0Mm"
base_url = "http://localhost"
knowledge_base_name = "测试知识库"
doc_id = "a2fb5b7a144e11f0918b0242ac120006"rag_object = RAGFlow(api_key=api_key, base_url=base_url)
dataset = rag_object.list_datasets(name=knowledge_base_name)
dataset = dataset[0]
doc = dataset.list_documents(id=doc_id)
doc = doc[0]
chunk = doc.add_chunk(content="xxxxxxx")
其中,api_key需要从设置中"API"菜单中获取,knowledge_base_name为添加的知识库名称,doc_id为添加块的文档id,从url中可以获取。
MinerU解析脚本
现在两个接口都准备好了,只需要将其对上,就能实现对文件的解析,并添加进解析块。
首先需要在待添加的知识库中创建一个空文档:
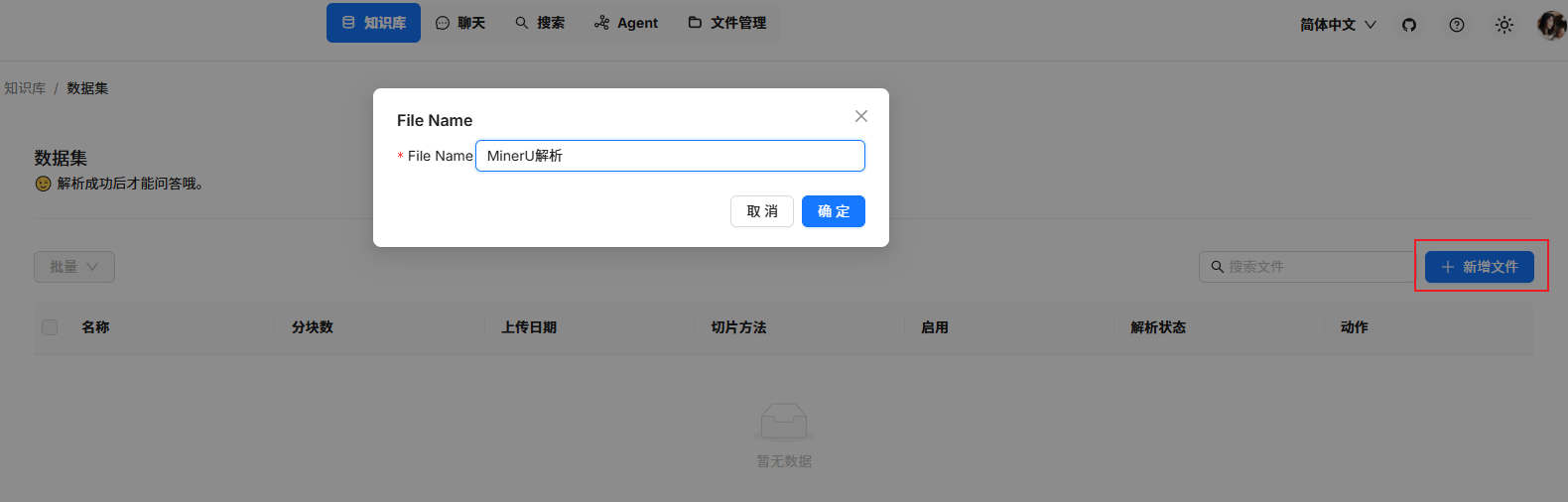
之后运行脚本,接口参数需要自行调整:
import json
import os
from ragflow_sdk import RAGFlow
from magic_pdf.data.data_reader_writer import FileBasedDataWriter, FileBasedDataReader
from magic_pdf.data.dataset import PymuDocDataset
from magic_pdf.model.doc_analyze_by_custom_model import doc_analyze
from magic_pdf.config.enums import SupportedPdfParseMethoddef process_pdf(pdf_file_path):"""处理PDF文件并返回内容列表"""# 参数设置name_without_suff = pdf_file_path.split(".")[0] # 去除文件扩展名# 准备环境local_image_dir, local_md_dir = "output/images", "output" # 图片和输出目录image_dir = str(os.path.basename(local_image_dir)) # 获取图片目录名# 初始化数据写入器image_writer, md_writer = FileBasedDataWriter(local_image_dir), FileBasedDataWriter(local_md_dir)# 读取PDF文件内容reader1 = FileBasedDataReader("") # 初始化数据读取器pdf_bytes = reader1.read(pdf_file_path) # 读取PDF文件内容为字节流# 处理流程## 创建PDF数据集实例ds = PymuDocDataset(pdf_bytes) # 使用PDF字节流初始化数据集## 推理阶段if ds.classify() == SupportedPdfParseMethod.OCR:# 如果是OCR类型的PDF(扫描件/图片型PDF)infer_result = ds.apply(doc_analyze, ocr=True) # 应用OCR模式的分析## 处理管道pipe_result = infer_result.pipe_ocr_mode(image_writer) # OCR模式的处理管道else:# 如果是文本型PDFinfer_result = ds.apply(doc_analyze, ocr=False) # 应用普通文本模式的分析## 处理管道pipe_result = infer_result.pipe_txt_mode(image_writer) # 文本模式的处理管道### 获取内容列表(JSON格式)content_list = pipe_result.get_content_list(image_dir)return content_listdef add_chunks_to_ragflow(content_list, api_key, base_url, knowledge_base_name, doc_id):"""将内容添加到RAGFlow知识库中"""rag_object = RAGFlow(api_key=api_key, base_url=base_url)dataset = rag_object.list_datasets(name=knowledge_base_name)dataset = dataset[0]doc = dataset.list_documents(id=doc_id)doc = doc[0]# 遍历内容列表,找出没有text_level的文本内容added_count = 0for item in content_list:if item.get('type') == 'text' and 'text_level' not in item:content = item.get('text', '')if content:chunk = doc.add_chunk(content=content)print(f"已添加内容: {content[:30]}...")added_count += 1print(f"总共添加了 {added_count} 个文本块")return added_countdef main():# 配置参数pdf_file_name = "small_ocr.pdf"api_key = "ragflow-I0NmRjMWNhMDk3ZDExZjA5NTA5MDI0Mm"base_url = "http://localhost"knowledge_base_name = "测试知识库"doc_id = "a2fb5b7a144e11f0918b0242ac120006"# 处理PDF并获取内容列表content_list_content = process_pdf(pdf_file_name)# 将内容添加到RAGFlowadd_chunks_to_ragflow(content_list_content, api_key, base_url, knowledge_base_name, doc_id)if __name__ == "__main__":main()
这个脚本实现了将"small_ocr.pdf"文件进行解析,并添加进指定文档。

在此基础上,可以再利用新建文档的接口,文档更名的接口,实现对更多文件的批量解析并重命名,这里不作拓展。
chunk大小的思考
目前,这种方式并未对chunk大小进行限制,对于每个chunk,实际是文章中的每个自然段。
之前看到群友问过“chunk大小是否会影响知识库检索?”这一点,可能需要更多的实践和经验验证。
下一步计划
已经满足“能用”的标准,下一步要考虑“好用”的阶段。看到有人提出,想将 MinerU 直接接进去作为一个选项,我对此持不同看法。
我觉得让用户上传文件始终是一种充满“风险”的行为,因为用户很有可能操作不当,上传过多的文件,造成存储压力。
下一步考虑禁止“普通用户”上传文件,构建私有知识库,因为对普通用户而言,并没有耐心等待解析完成,构建知识库交给管理员就好了,普通用户能直接用就行。