做简历比较好的网站叫什么关于旅行的网站怎样做
学习讲义Day14安排的内容:SHAP图的绘制
SHAP模型的基本概念
参考学习的帖子:SHAP 可视化解释机器学习模型简介_shap图-CSDN博客
以下为学习该篇帖子的理解记录:
Q. 什么是SHAP模型?它与机器学习模型的区别在哪儿?
机器学习模型仿若一个黑盒子,我们只能看到输入和输出,但至于“输入到输出之间发生了什么”我们是不知道的。这里让我联想到语言学家乔姆斯基在语言习得中提到的Black Box,可以与之关联理解。SHAP模型就可以让我们清楚地看到从输入到输出之间到底发生了什么(已知条件对最终预测结果起到了哪些影响,是正向还是负向)。
Q. SHAP的工作原理是什么?
帖子中写到“SHAP是一种模型事后解释的方法”。这里的“模型事后解释”指的是SHAP是在模型训练后,通过分析模型的行为来解释其预测的结果。比如:为什么模型会预测某个客户会违约?哪些特征对这个预测起了关键作用?
SHAP模型的工作原理就是计算特征对模型输出的边际贡献。
Q. 什么是“边际贡献”?

SHAP模型从全局和局部对“黑盒模型”进行解释,并构建了一个“加性的解释模型”。所有的特征都被视为“贡献者”(这样的话,我们就可以量化每个特征的作用。SHAP方法也确保了特征贡献的分配是公平的,即每个特征的贡献值是基于所有可能特征组合的平均边际贡献计算的)。
Q. 如何理解“全局和局部”?什么是“加性的解释模型”?



Q. SHAP可以解决哪些实际的问题?
模型调试,指导特征工程,指导数据采集,指导做决策,以及建立模型与人之间的信任。
Q. 为什么会生成shap_values数组?
截图自讲义文件


代码实现
首先还是运行预处理好的代码
# 先运行之前预处理好的代码
import pandas as pd
import pandas as pd #用于数据处理和分析,可处理表格数据。
import numpy as np #用于数值计算,提供了高效的数组操作。
import matplotlib.pyplot as plt #用于绘制各种类型的图表
import seaborn as sns #基于matplotlib的高级绘图库,能绘制更美观的统计图形。
import warnings
warnings.filterwarnings("ignore")# 设置中文字体(解决中文显示问题)
plt.rcParams['font.sans-serif'] = ['SimHei'] # Windows系统常用黑体字体
plt.rcParams['axes.unicode_minus'] = False # 正常显示负号
data = pd.read_csv('data.csv') #读取数据# 先筛选字符串变量
discrete_features = data.select_dtypes(include=['object']).columns.tolist()
# Home Ownership 标签编码
home_ownership_mapping = {'Own Home': 1,'Rent': 2,'Have Mortgage': 3,'Home Mortgage': 4
}
data['Home Ownership'] = data['Home Ownership'].map(home_ownership_mapping)# Years in current job 标签编码
years_in_job_mapping = {'< 1 year': 1,'1 year': 2,'2 years': 3,'3 years': 4,'4 years': 5,'5 years': 6,'6 years': 7,'7 years': 8,'8 years': 9,'9 years': 10,'10+ years': 11
}
data['Years in current job'] = data['Years in current job'].map(years_in_job_mapping)# Purpose 独热编码,记得需要将bool类型转换为数值
data = pd.get_dummies(data, columns=['Purpose'])
data2 = pd.read_csv("data.csv") # 重新读取数据,用来做列名对比
list_final = [] # 新建一个空列表,用于存放独热编码后新增的特征名
for i in data.columns:if i not in data2.columns:list_final.append(i) # 这里打印出来的就是独热编码后的特征名
for i in list_final:data[i] = data[i].astype(int) # 这里的i就是独热编码后的特征名# Term 0 - 1 映射
term_mapping = {'Short Term': 0,'Long Term': 1
}
data['Term'] = data['Term'].map(term_mapping)
data.rename(columns={'Term': 'Long Term'}, inplace=True) # 重命名列
continuous_features = data.select_dtypes(include=['int64', 'float64']).columns.tolist() #把筛选出来的列名转换成列表# 连续特征用中位数补全
for feature in continuous_features: mode_value = data[feature].mode()[0] #获取该列的众数。data[feature].fillna(mode_value, inplace=True) #用众数填充该列的缺失值,inplace=True表示直接在原数据上修改。# 最开始也说了 很多调参函数自带交叉验证,甚至是必选的参数,你如果想要不交叉反而实现起来会麻烦很多
# 所以这里我们还是只划分一次数据集
from sklearn.model_selection import train_test_split
X = data.drop(['Credit Default'], axis=1) # 特征,axis=1表示按列删除
y = data['Credit Default'] # 标签
# 按照8:2划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42) # 80%训练集,20%测试集基准模型
from sklearn.ensemble import RandomForestClassifier #随机森林分类器from sklearn.metrics import accuracy_score, precision_score, recall_score, f1_score # 用于评估分类器性能的指标
from sklearn.metrics import classification_report, confusion_matrix #用于生成分类报告和混淆矩阵
import warnings #用于忽略警告信息
warnings.filterwarnings("ignore") # 忽略所有警告信息
# --- 1. 默认参数的随机森林 ---
# 评估基准模型,这里确实不需要验证集
print("--- 1. 默认参数随机森林 (训练集 -> 测试集) ---")
import time # 这里介绍一个新的库,time库,主要用于时间相关的操作,因为调参需要很长时间,记录下会帮助后人知道大概的时长
start_time = time.time() # 记录开始时间
rf_model = RandomForestClassifier(random_state=42)
rf_model.fit(X_train, y_train) # 在训练集上训练
rf_pred = rf_model.predict(X_test) # 在测试集上预测
end_time = time.time() # 记录结束时间print(f"训练与预测耗时: {end_time - start_time:.4f} 秒")
print("\n默认随机森林 在测试集上的分类报告:")
print(classification_report(y_test, rf_pred))
print("默认随机森林 在测试集上的混淆矩阵:")
print(confusion_matrix(y_test, rf_pred))SHAP模型的代码实现
import shap
import matplotlib.pyplot as plt# 初始化 SHAP 解释器
explainer = shap.TreeExplainer(rf_model)# 计算 SHAP 值(基于测试集),这个shap_values是一个numpy数组,表示每个特征对每个样本的贡献值
shap_values = explainer.shap_values(X_test) shap_values # 每一行代表一个样本,每一列代表一个特征,值表示该特征对该样本的预测结果的影响程度。正值表示该特征对预测结果有正向影响,负值表示负向影响。输出:
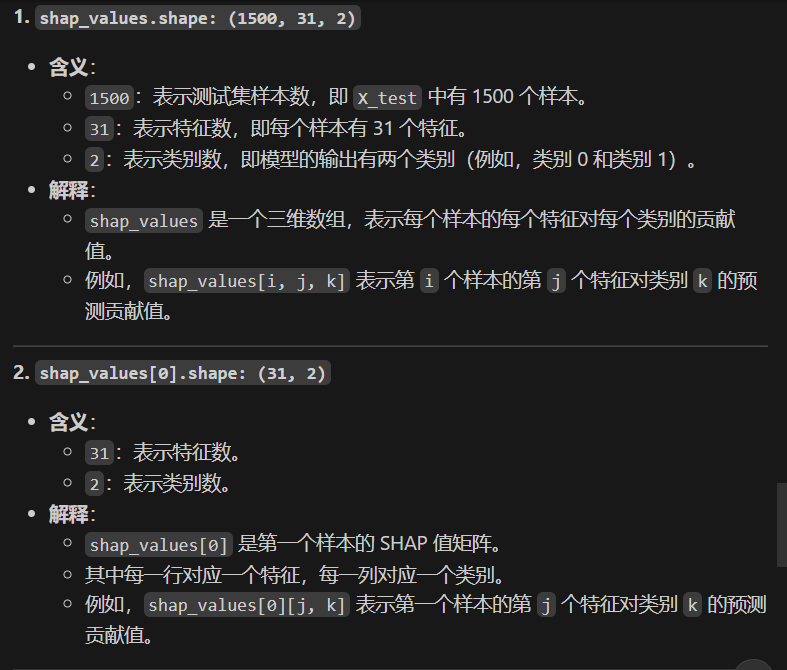
array([[[ 9.07465700e-03, -9.07465700e-03],[ 7.21456498e-03, -7.21456498e-03],[ 4.55189444e-02, -4.55189444e-02],...,[ 7.12857198e-05, -7.12857198e-05],[ 4.67733508e-05, -4.67733508e-05],[ 1.61298135e-04, -1.61298135e-04]],[[-1.02606871e-02, 1.02606871e-02],[ 1.85572634e-02, -1.85572634e-02],[-1.64992848e-02, 1.64992848e-02],...,[ 2.00070852e-04, -2.00070852e-04],[ 5.11798841e-05, -5.11798841e-05],[ 1.02827796e-04, -1.02827796e-04]],[[ 3.21529115e-03, -3.21529115e-03],[ 1.28184070e-02, -1.28184070e-02],[ 1.02124914e-01, -1.02124914e-01],...,[ 1.73012306e-04, -1.73012306e-04],[ 4.74133256e-05, -4.74133256e-05],[ 1.26753231e-04, -1.26753231e-04]],...,[[ 1.15222741e-03, -1.15222741e-03],[-1.71843266e-02, 1.71843266e-02],[-3.04994337e-02, 3.04994337e-02],...,[ 1.44859329e-04, -1.44859329e-04],[ 1.80111014e-05, -1.80111014e-05],[ 1.30107512e-04, -1.30107512e-04]],[[ 1.29249120e-03, -1.29249120e-03],[ 5.66948438e-03, -5.66948438e-03],[ 2.49050264e-02, -2.49050264e-02],...,[ 2.50590715e-06, -2.50590715e-06],[ 4.68839113e-05, -4.68839113e-05],[ 1.15002997e-05, -1.15002997e-05]],[[-1.12640555e-03, 1.12640555e-03],[ 1.42648293e-02, -1.42648293e-02],[ 4.74790019e-02, -4.74790019e-02],...,[ 6.19451775e-05, -6.19451775e-05],[ 3.30996384e-05, -3.30996384e-05],[ 4.45219920e-05, -4.45219920e-05]]])shap_values.shape # 第一维是样本数,第二维是特征数,第三维是类别数输出:(1500,31,2)
print("shap_values shape:", shap_values.shape)
print("shap_values[0] shape:", shap_values[0].shape)
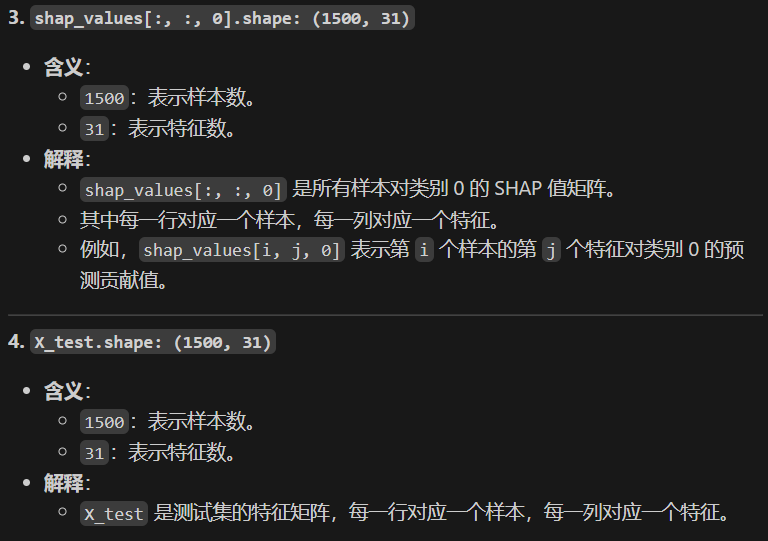
print("shap_values[:, :, 0] shape:", shap_values[:, :, 0].shape)
print("X_test shape:", X_test.shape)输出:
shap_values shape: (1500, 31, 2)
shap_values[0] shape: (31, 2)
shap_values[:, :, 0] shape: (1500, 31)
X_test shape: (1500, 31)现在对这个输出结果通过AI进行理解学习:

今日学习到这里。明日继续这部分SHAP图绘制的学习。加油!!!@浙大疏锦行