vps做自己的网站logo设计方案
1. 网页信息抽取
问题定义:对新闻网页(输入为HTML)提取结构化信息,包括标题、发布时间、作者、正文、图片等。
https://www.dailypolitical.com/2025/02/27/walter-public-investments-inc-purchases-3634-shares-of-msci-inc-nysemsci.html

通过页面看到发表时间(日期,或日期+时间)为:Feb 27th, 2025。
网页信息抽取主要方法:
- 基于规则的方法,根据特定的网页制定抽取规则(正则表达式规则或其他规则)
- 基于模板的方法,对新闻网页按照一定的模板进行分类,从而利用模板内各板块的配置进行抽取
- 基于视觉的方法,假想人去看网页,通过视觉信息可以快速定位标题、正文、时间等信息
- 基于大模型的方法,通过大模型去阅读网页,利用大模型的强大语义理解能力进行识别
2. GDELT事件时间
基于新闻(主要是境外新闻)网页URL可以关联到GDETL事件信息:
GlobalEventID|Day |EventCode|NumMentions|NumSources|NumArticles|AvgTone|Actor1Code|Actor1Name|Actor1CountryCode|Actor2Code|Actor2Name|Actor2CountryCode|ActionGeo_Type|ActionGeo_Type_Fullname|ActionGeo_CountryCode|ActionGeo_Lat|ActionGeo_Long|SOURCEURL |-------------±-------±--------±----------±---------±----------±------±---------±---------±----------------±---------±---------±----------------±-------------±----------------------±--------------------±------------±-------------±----------------------------------------------------------------------------------------------------------------------+
1229119384|20250227|10|10|1|10|1.89099|BUS|COMPANY | | | | | 4| |CA | 49.7833| -118.133|https://www.dailypolitical.com/2025/02/27/walter-public-investments-inc-purchases-3634-shares-of-msci-inc-nysemsci.html|
1229120306|20250227| 50| 10| 1| 10|1.89099|MNCUSA |MSCI INC |USA | | | | 4| |CA | 49.7833| -118.133|https://www.dailypolitical.com/2025/02/27/walter-public-investments-inc-purchases-3634-shares-of-msci-inc-nysemsci.html|
GDELT中事件主要包括事件类型、发生日期(年月日)、主体名称、主体国家等信息。
进一步可通过事件提到(event-mention)表查询事件时间和提到时间:event-time和event-mention-time。
3. 新闻时间抽取
3.1.基于GDELT事件时间
通过GDELT可以获取两个时间:event_time和mention_time,如上图所示,采用的UTC时间戳
转换一下:UTC(1740643200000) 即 Thu Feb 27 2025 16:00:00 GMT+0800 (China Standard Time)。
3.2.基于网页元数据
对网页进行分析,发现在标签中包含了发表时间:
可以看到有更为精确的时间:2025-02-27T07:32:48+0000,并且采用了UTC时间格式,非常方便解析。(注意!并不是所有网页都采用UTC格式)
这里采用的meta属性为“article:published_time”,在另外一些网页中属性为“og:datePublished”为了可靠性,我兼容了两个属性,并且不考虑属性的命名空间名。
几类时间比较
比较一下几种时间:
- 页面可视时间,可能不够精细(只到日,没有详细时间),且格式千差万别,容易抽取错误。例如,通过gne或Constor抽取的时间,出现了不少时间为2025-12-2,实际应该是2025-2-12。
- GDELT事件时间,不够准确。GDELT事件时间一般只到15分钟的粒度,对于有的网页与发布时间的差异可能达到半个小时。
- meta标签时间,这个是最准确的。不过对于早期的不规范的网页,可能没有meta信息。有的网页虽然存在meta标签,但没有新闻发布时间。
- LD-json。与meta作用类似,以一种结构化JSON数据提供,方便网页元数据共享,其中发布时间字段为datePublished。但对于很多网页可能没有提供。LD-json示例如下(https://www.telecomasia.net/news/mma/fedor-emelianenko-has-no-plans-to-fight-in-mcgregorundefineds-league/):
<script type="application/ld+json">{"@context": "https:\/\/schema.org","@type": "NewsArticle","description": "Famous Russian mixed martial artist Fedor Emelianenko has no plans to participate in bare-knuckle fights.","mainEntityOfPage": {"@type": "WebPage","@id": "https:\/\/www.telecomasia.net\/news\/mma\/fedor-emelianenko-has-no-plans-to-fight-in-mcgregorundefineds-league\/"},"headline": "Fedor Emelianenko Has No Plans to Fight in McGregor's League","datePublished": "2025-02-17T10:53:31+03:00","dateModified": "2025-02-17T10:55:41+03:00","image": "https:\/\/www.telecomasia.net\/upload\/iblock\/1aa\/1aa24aa8e228aec85967fb45c607e666.jpg","author": {"@type": "Person","name": "Marina Magomedova","url": "https:\/\/www.telecomasia.net\/authors\/marina-magomedova\/"},"publisher": {"@type": "Organization","name": "Telecom Asia Sport","url": "https:\/\/www.telecomasia.net","logo": {"@type": "ImageObject","url": "https:\/\/www.telecomasia.net\/local\/templates\/main\/img\/logo-shema-ta.png","width": "1300","height": "300"}}
}</script>
时间统计
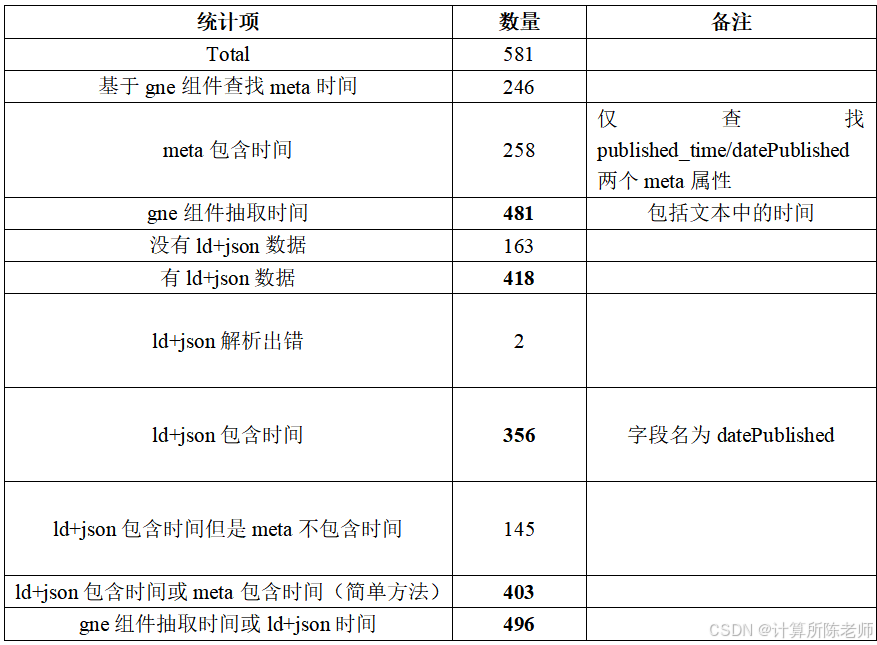
综合策略
综合上面几种情况,可以按照这个优先级顺序获取新闻发布时间:
- 首先查看meta时间。建议基于gne等组件,其内置了多个可能关于新闻发布时间的meta标签。下图中是gne采用的时间抽取xpath规则:
PUBLISH_TIME_META = [ # 部分特别规范的新闻网站,可以直接从 HTML 的 meta 数据中获得发布时间'//meta[starts-with(@property, "rnews:datePublished")]/@content','//meta[starts-with(@property, "article:published_time")]/@content','//meta[starts-with(@property, "og:published_time")]/@content','//meta[starts-with(@property, "og:release_date")]/@content','//meta[starts-with(@itemprop, "datePublished")]/@content','//meta[starts-with(@itemprop, "dateUpdate")]/@content','//meta[starts-with(@name, "OriginalPublicationDate")]/@content','//meta[starts-with(@name, "article_date_original")]/@content','//meta[starts-with(@name, "og:time")]/@content','//meta[starts-with(@name, "apub:time")]/@content','//meta[starts-with(@name, "publication_date")]/@content','//meta[starts-with(@name, "sailthru.date")]/@content','//meta[starts-with(@name, "PublishDate")]/@content','//meta[starts-with(@name, "publishdate")]/@content','//meta[starts-with(@name, "PubDate")]/@content','//meta[starts-with(@name, "pubtime")]/@content','//meta[starts-with(@name, "_pubtime")]/@content','//meta[starts-with(@name, "weibo: article:create_at")]/@content','//meta[starts-with(@pubdate, "pubdate")]/@content',
]
- 看是否有LD-json时间。gne组件目前未考虑LD-json元数据。因为需要按照JSON进行数据解析,相比meta增加了解析JSON和查找JSON中特定字段的时间。
- 基于一组可能的网页标签。通过xpath或css匹配可能为新闻发布时间的标签,提取其文本内容。虽然标签查找很高效,但存在未命中或抽取内容非时间的可能,后者可进一步结合规则进行判断。
- 基于新闻文本。对网页新闻文章区域的文本进行时间识别。如果确定文章区域比较困难,则可使用网页body作为候选。gne通过xpath
//*[@class="article__content"]确定文章区域,通过一组日期时间的正则表达式抽取发布时间,规则如下图所示。不过可以看出,有一些典型英语国家表达的时间格式是不支持的,例如3rd March 2025, 22:18 GMT+11,需要进一步补充规则。另外,文本中出现的时间可能不一定是新闻发布时间,而是某个事件发生的语义时间,这种情况可能需要对时间时间所在上下文进行判断。
DATETIME_PATTERN = ["(\d{4}[-|/|.]\d{1,2}[-|/|.]\d{1,2}\s*?[0-1]?[0-9]:[0-5]?[0-9]:[0-5]?[0-9])","(\d{4}[-|/|.]\d{1,2}[-|/|.]\d{1,2}\s*?[2][0-3]:[0-5]?[0-9]:[0-5]?[0-9])","(\d{4}[-|/|.]\d{1,2}[-|/|.]\d{1,2}\s*?[0-1]?[0-9]:[0-5]?[0-9])","(\d{4}[-|/|.]\d{1,2}[-|/|.]\d{1,2}\s*?[2][0-3]:[0-5]?[0-9])","(\d{4}[-|/|.]\d{1,2}[-|/|.]\d{1,2}\s*?[1-24]\d时[0-60]\d分)([1-24]\d时)","(\d{2}[-|/|.]\d{1,2}[-|/|.]\d{1,2}\s*?[0-1]?[0-9]:[0-5]?[0-9]:[0-5]?[0-9])","(\d{2}[-|/|.]\d{1,2}[-|/|.]\d{1,2}\s*?[2][0-3]:[0-5]?[0-9]:[0-5]?[0-9])","(\d{2}[-|/|.]\d{1,2}[-|/|.]\d{1,2}\s*?[0-1]?[0-9]:[0-5]?[0-9])","(\d{2}[-|/|.]\d{1,2}[-|/|.]\d{1,2}\s*?[2][0-3]:[0-5]?[0-9])","(\d{2}[-|/|.]\d{1,2}[-|/|.]\d{1,2}\s*?[1-24]\d时[0-60]\d分)([1-24]\d时)","(\d{4}年\d{1,2}月\d{1,2}日\s*?[0-1]?[0-9]:[0-5]?[0-9]:[0-5]?[0-9])","(\d{4}年\d{1,2}月\d{1,2}日\s*?[2][0-3]:[0-5]?[0-9]:[0-5]?[0-9])","(\d{4}年\d{1,2}月\d{1,2}日\s*?[0-1]?[0-9]:[0-5]?[0-9])","(\d{4}年\d{1,2}月\d{1,2}日\s*?[2][0-3]:[0-5]?[0-9])","(\d{4}年\d{1,2}月\d{1,2}日\s*?[1-24]\d时[0-60]\d分)([1-24]\d时)","(\d{2}年\d{1,2}月\d{1,2}日\s*?[0-1]?[0-9]:[0-5]?[0-9]:[0-5]?[0-9])","(\d{2}年\d{1,2}月\d{1,2}日\s*?[2][0-3]:[0-5]?[0-9]:[0-5]?[0-9])","(\d{2}年\d{1,2}月\d{1,2}日\s*?[0-1]?[0-9]:[0-5]?[0-9])","(\d{2}年\d{1,2}月\d{1,2}日\s*?[2][0-3]:[0-5]?[0-9])","(\d{2}年\d{1,2}月\d{1,2}日\s*?[1-24]\d时[0-60]\d分)([1-24]\d时)","(\d{1,2}月\d{1,2}日\s*?[0-1]?[0-9]:[0-5]?[0-9]:[0-5]?[0-9])","(\d{1,2}月\d{1,2}日\s*?[2][0-3]:[0-5]?[0-9]:[0-5]?[0-9])","(\d{1,2}月\d{1,2}日\s*?[0-1]?[0-9]:[0-5]?[0-9])","(\d{1,2}月\d{1,2}日\s*?[2][0-3]:[0-5]?[0-9])","(\d{1,2}月\d{1,2}日\s*?[1-24]\d时[0-60]\d分)([1-24]\d时)","(\d{4}[-|/|.]\d{1,2}[-|/|.]\d{1,2})","(\d{2}[-|/|.]\d{1,2}[-|/|.]\d{1,2})","(\d{4}年\d{1,2}月\d{1,2}日)","(\d{2}年\d{1,2}月\d{1,2}日)","(\d{1,2}月\d{1,2}日)"
]
对于上述从文本内容中抽取的新闻发布时间,要跟事件时间、当前时间进行对比,避免或过滤出现的明显无效结果。如果可以牺牲一定程度的准确度,则可直接使用事件时间,不过需要注意新闻发布时间应该早于GDELT时间时间。