unity做网站网上的推广
作业
自行学习参考如何使用kaggle平台,写下使用注意点,并对下述比赛提交代码
kaggle泰坦里克号人员生还预测
一、流程
思路概述
- 数据加载 :读取泰坦尼克号的训练集和测试集。
- 数据预处理 :处理缺失值、对分类变量进行编码、提取特征等。
- 模型训练 :选择合适的机器学习模型并在训练集上进行训练。
- 模型预测 :使用训练好的模型对测试集进行预测。
- 结果提交 :将预测结果保存为符合 Kaggle 要求的 CSV 文件。
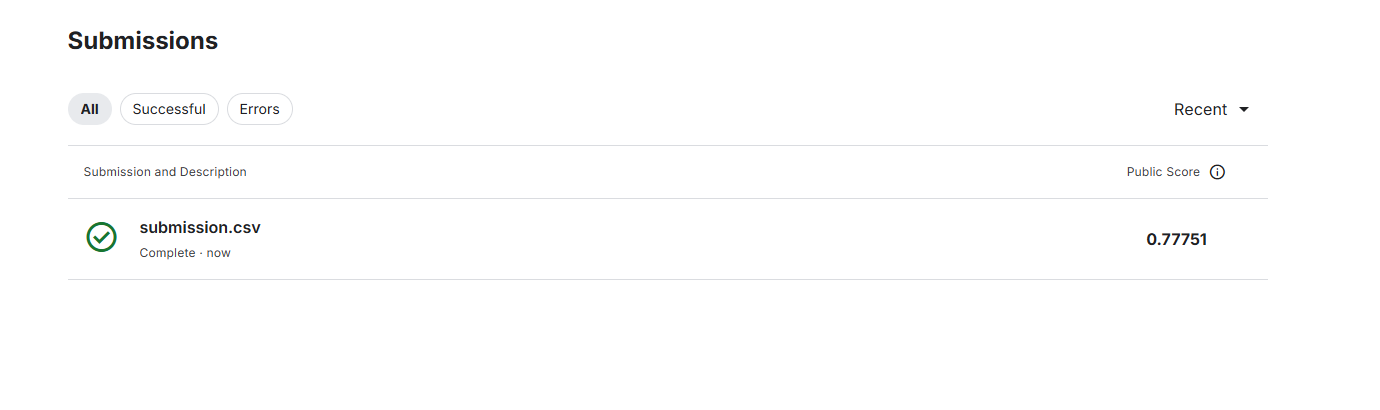
个人感觉kaggle竞赛平台是根据你自己交的.csv文件去和平台上完全正确的.csv文件进行比对。
从官网上下载数据集,判断每个特征的含义,以及数据类型,属性。
| 特征名称 | 中文含义 | 数据类型 | 详细解释 |
|---|---|---|---|
PassengerId | 乘客编号 | 整数 | 每个乘客独一无二的标识,用于区分不同乘客 |
Survived | 是否幸存 | 整数 | 目标变量,0 表示未幸存,1 表示幸存 |
Pclass | 客舱等级 | 整数 | 乘客所购船票对应的舱位等级,1 为一等舱,2 为二等舱,3 为三等舱。一般等级越高,乘客社会经济地位越高 |
Name | 乘客姓名 | 字符串 | 包含乘客的全名,可能包含头衔信息,如 Mr.、Miss. 等 |
Sex | 性别 | 字符串 | 乘客的性别,取值为 male(男性)或 female(女性) |
Age | 年龄 | 浮点数 | 乘客的年龄,部分数据存在缺失值。年龄可能影响生存概率,例如儿童和老人可能在救援中更受照顾 |
SibSp | 兄弟姐妹及配偶数量 | 整数 | 乘客在船上的兄弟姐妹和配偶的总数。反映乘客的家庭关系情况 |
Parch | 父母及子女数量 | 整数 | 乘客在船上的父母和子女的总数。同样反映乘客的家庭关系情况 |
Ticket | 船票编号 | 字符串 | 乘客所持船票的唯一编号,格式多样,可能包含字母和数字 |
Fare | 船票票价 | 浮点数 | 乘客购买船票所支付的费用,与客舱等级可能存在关联 |
Cabin | 客舱编号 | 字符串 | 乘客所在的客舱编号,大量数据存在缺失值。不同客舱位置可能影响乘客在灾难发生时逃生的难易程度 |
Embarked | 登船港口 | 字符串 | 乘客登船的港口,C 代表瑟堡(Cherbourg),Q 代表皇后镇(Queenstown),S 代表南安普顿(Southampton) |
二、解题代码
逻辑都写在注释里面了,参考别人的代码,不过可以看出来是很标准的机器学习训练及测试的代码。
import pandas as pd
from sklearn.ensemble import RandomForestClassifier
from sklearn.preprocessing import LabelEncoder
from sklearn.impute import SimpleImputer# 加载数据
train_data = pd.read_csv('./titanic/train.csv')
test_data = pd.read_csv('./titanic/test.csv')# 提取特征和标签
y = train_data["Survived"]features = ["Pclass", "Sex", "SibSp", "Parch", "Fare", "Embarked"]
X = train_data[features]
X_test = test_data[features]# 处理分类变量
label_encoders = {}
for col in ["Sex", "Embarked"]:le = LabelEncoder()# 处理训练集X[col] = le.fit_transform(X[col].astype(str))# 处理测试集X_test[col] = le.transform(X_test[col].astype(str))label_encoders[col] = le# 处理缺失值
imputer = SimpleImputer(strategy='median')
X = pd.DataFrame(imputer.fit_transform(X), columns=X.columns)
X_test = pd.DataFrame(imputer.transform(X_test), columns=X_test.columns)# 模型训练
model = RandomForestClassifier(n_estimators=100, max_depth=5, random_state=1)
model.fit(X, y)# 模型预测
predictions = model.predict(X_test)# 保存结果
output = pd.DataFrame({'PassengerId': test_data.PassengerId, 'Survived': predictions})
output.to_csv('submission.csv', index=False)