纪检网站建设方案google play官网
1. 简介
- 开发背景: ClickHouse 由 Yandex 于 2016 年开源,目的是提供高性能的 OLAP 解决方案。
- 性能: ClickHouse 能够以极高的速度处理大量数据,每秒可以处理数亿到十亿多行数据。
- 架构: 它使用 C++ 编写,提供丰富的数据类型、数据库引擎和表引擎,支持多种数据压缩方式。
- 存储: 数据以列式存储,优化了读取部分列时的 I/O 效率,同时便于数据压缩。
- SQL 支持: ClickHouse 支持类似 SQL 的查询语言,允许实时生成分析数据报告。
- 特性: 支持数据分区、多核并行处理、索引、在线查询、近似计算等。
- 应用场景: 适用于大数据分析、数据仓库、BI 报表、监控系统等场景。
2. 基本概念
2.1 数据类型
2.2 数据库引擎
2.2.1 Ordinary
默认引擎,在绝大多数情况下我们都会使用默认引 擎,使用时无须刻意声明。在此数据库下可以使用任意类型的表引 擎。
2.2.2 Dictionary
字典引擎,此类数据库会自动为所有数据字典创 建它们的数据表。
2.2.3 Memory
内存引擎,用于存放临时数据。此类数据库下的数据 表只会停留在内存中,不会涉及任何磁盘操作,当服务重启后数据会 被清除。
2.2.4 Lazy
日志引擎,此类数据库下只能使用Log系列的表引擎,关 于Log表引擎的详细介绍会在第8章展开。
2.2.5 MySQL
MySQL引擎,此类数据库下会自动拉取远端MySQL中的数 据,并为它们创建MySQL表引擎的数据表。
2.3 表引擎
2.4 压缩算法
- 列式存储:重复的数据越多,压缩比例就越好。
3. 实践应用
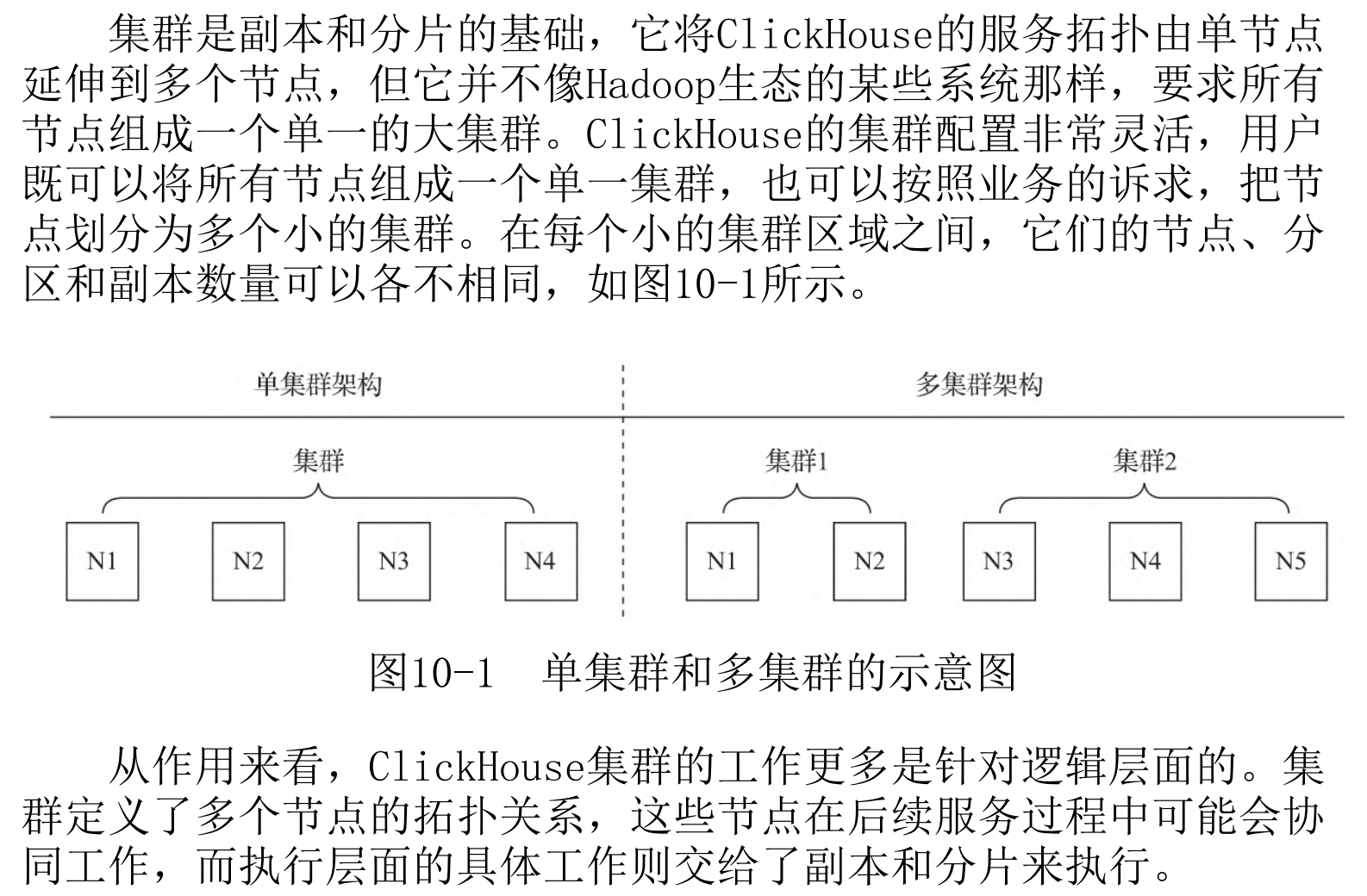
3.1 clickhouse 集群
ClickHouse 服务通过 Paxos 协议管理整个集群的状态,无需繁重的集群管理操作,自动管理各节点。与Hadoop生态的其他数 据库相比,ClickHouse更像一款“传统”MPP架构的数据库,它没有采 用Hadoop生态中常用的主从架构,而是使用了多主对等网络结构
3.2 数据同步和导入
4. 性能优化
4.1 索引
4.2 分片
数据分片是将数据进行横向切分,这是一种在面对海量数据的场 景下,解决存储和查询瓶颈的有效手段,是一种分治思想的体现。 ClickHouse支持分片,而分片则依赖集群。每个集群由1到多个分片组 成,而每个分片则对应了ClickHouse的1个服务节点。分片的数量上限 取决于节点数量(1个分片只能对应1个服务节点)。
4.3 分区
数据分区(partition)和数据分片(shard)是完全不同的两个 概念。数据分区是针对本地数据而言的,是数据的一种纵向切分。而 数据分片是数据的一种横向切分。

5. 常见问题解答
5.1 ClickHouse为什么快?
很多用户心中一直会有这样的疑问,为什么ClickHouse这么快? 前面的介绍对这个问题已经做出了科学合理的解释。比方说,因为 ClickHouse是列式存储数据库,所以快;也因为ClickHouse使用了向量化引擎,所以快。这些解释都站得住脚,但是依然不能消除全部的 疑问。因为这些技术并不是秘密,世面上有很多数据库同样使用了这 些技术,但是依然没有ClickHouse这么快。所以我想从另外一个角度 来探讨一番ClickHouse的秘诀到底是什么。
5.2 ClickHouse为什么不使用B+树?
ClickHouse 是一款列式存储数据库,它的设计和数据存储结构与基于 B+ 树的数据库系统有着本质的不同。以下是 ClickHouse 不使用 B+ 树的几个原因:
-
列式存储的优势: ClickHouse 采用列式存储,这意味着数据是按列而不是按行存储的。这种方式对于 OLAP(在线分析处理)场景非常有效,因为它允许数据库只读取查询中需要的列,从而减少了 I/O 操作和提高了查询效率。相比之下,B+ 树是一种基于行的数据结构,适合于 OLTP(在线事务处理)场景,其中行的完整性和事务操作更为重要。
-
数据压缩: 列式存储天然适合数据压缩,因为同一列中的数据类型相同,可以应用更高效的压缩算法。ClickHouse 利用这一特性,通过压缩同一列的数据来减少存储空间和提高 I/O 效率。而 B+ 树结构通常不支持列压缩,因为它是为行级存储设计的。
-
高性能的聚合操作: ClickHouse 专为快速的数据分析和聚合操作而设计,列式存储使得这些操作更加高效,因为相关的列可以被快速加载和处理。B+ 树则更适合于执行基于主键的快速查找和更新操作。
-
数据分区和分片: ClickHouse 支持数据的自动分区和分片,这有助于管理大规模数据集并提高查询性能。B+ 树虽然也可以在数据库中实现分区,但它本身并不直接支持这一功能,通常需要数据库系统层面的支持。
-
数据合并和更新策略: ClickHouse 的 MergeTree 引擎支持数据的后台合并和净化操作,这有助于保持数据的整洁和高效查询。B+ 树则需要更复杂的操作来维护数据的一致性和性能。
-
数据加载和查询模式: ClickHouse 设计用于处理大量数据的批量加载和复杂查询,其数据加载和查询模式与 B+ 树索引的行级操作不同。
总的来说,ClickHouse 的设计目标是为了优化分析型工作负载,特别是那些涉及大量数据和复杂查询的场景。而 B+ 树更适合于事务型工作负载,其中数据的一致性和行级操作更为关键。因此,ClickHouse 选择了列式存储和专门的表引擎,如 MergeTree,来满足其性能和效率的要求,而不是使用 B+ 树这种传统的索引结构。
6. 原理解读
6.1 LSM树
LSM树也是一种非常流行的索引结构,发源于Google的BigTable,现在最具代表性的使用LSM树索引结构的系统是HBase。LSM本 质上可以看作将原本的一棵大树拆成了许多棵小树,每一批次写入的 数据都会经历如下过程。首先,会在内存中构建出一棵小树,构建完毕即算写入成功(这里会通过预写日志的形式,防止因内存故障而导 致的数据丢失)。写入动作只发生在内存中,不涉及磁盘操作,所以极大地提升了数据写入性能。其次,小树在构建的过程中会进行排 序,这样就保证了数据的有序性。最后,当内存中小树的数量达到某 个阈值时,就会借助后台线程将小树刷入磁盘并生成一个小的数据 段。在每个数据段中,数据局部有序。也正因为数据有序,所以能够 进一步使用稀疏索引来优化查询性能。