公司想做网站2022年适合小学生的新闻
个人学习笔记,如有错误欢迎指正,也欢迎交流,其他笔记见个人空间
Auto-Encoder 是什么?
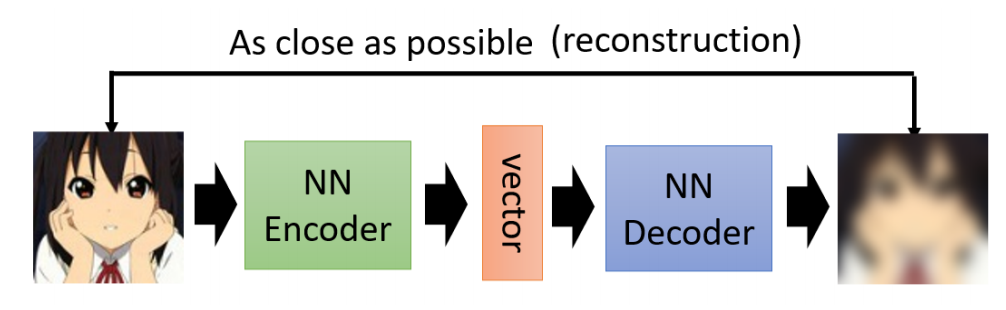
Auto-Encoder(自编码器)是一种典型的 Self-Supervised Learning(自监督学习) 方法,具有以下结构和目标:
-
结构:
-
包含两个网络:
Encoder和Decoder -
Encoder将输入数据压缩为低维表示 -
Decoder从低维表示重建原始数据
-
-
训练目标:
-
最小化输入与输出之间的重建误差
-
本质是“重建(Reconstruction)”,即让输出尽可能还原原始输入
-
-
无需标签:
-
Auto-Encoder 只依赖无标签数据,典型的 Unsupervised Learning,属于 Pre-Training 方法的一种
-
与其他模型的比较与联系
-
与 BERT、GPT 相比:BERT 做填空题、GPT 做文本续写,而 Auto-Encoder 做输入重建。尽管方式不同,但目标一致:从无标签数据中学习有效表示。
-
与 CycleGAN 的“Cycle Consistency”思想类似:期望“原始 → 中间 → 重建”的结果与原始尽可能一致
Auto-Encoder的原理
-
特征提取与降维(Dimension Reduction):
-
将高维图像压缩成低维向量(如将 100x100 的图像 → 10维或100维向量)
-
例如下面这个图,对于影像来说,并不是所有 3×3 的矩阵都是图片,图片的变化其实是有限的,例如图片或许只是左对角线和左下方块组成。
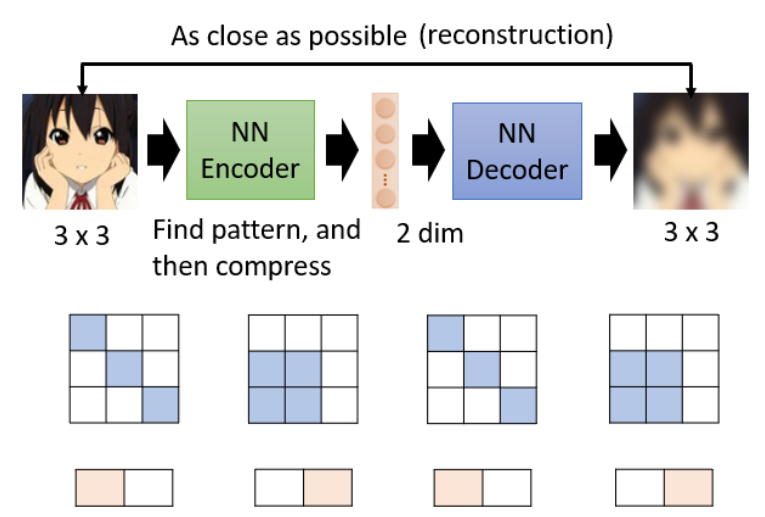
- 中间的低维表示即“瓶颈层(Bottleneck)”,是一种压缩/编码的过程
-
用途:
-
将低维向量用于分类、回归等下游任务
-
训练少量数据时更高效,因为特征已被抽象化表达
-
De-noising Auto-Encoder
-
给原始输入加噪声,再训练 Auto-Encoder 恢复原始未扰动数据
-
增强模型鲁棒性,强迫 Encoder 学会提取关键特征并忽略无关扰动
-
与 BERT 的做法非常类似,BERT 可看作文本的 De-noising Auto-Encoder
-
如 BERT 的 Mask 操作就相当于对输入加噪声
-
其他作用
Feature Disentanglement(特征解纠缠)
核心概念:
-
Auto-Encoder 输出的向量(Code / Embedding)往往混合了多个因素,如内容、风格、身份等。
-
Feature Disentangle 旨在将不同类型的信息分开编码(如前50维表示“内容”,后50维表示“语者”)。
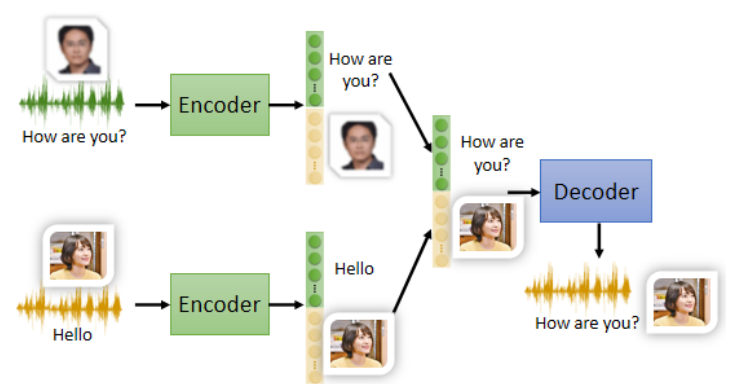
应用实例:Voice Conversion(语者转换)
-
用于将一个人说话的“内容”用另一个人的“声音特征”说出来,这就是变声器。
优势:
-
不再需要配对的训练数据(不同人说相同句子)。
-
适用于语音、图像、文本的风格迁移、身份替换等任务。
Discrete Latent Representation(离散隐变量表示)
传统方式:Auto-Encoder 中的 Code 通常是连续的向量(如浮点数)。
新思路:尝试使用离散编码(如Binary或One-hot 向量),让模型的表示更具可解释性或可控性。
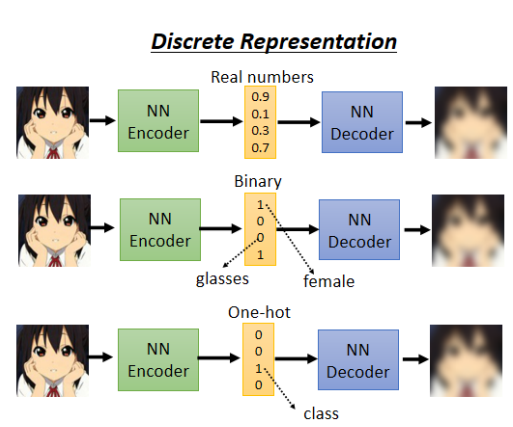
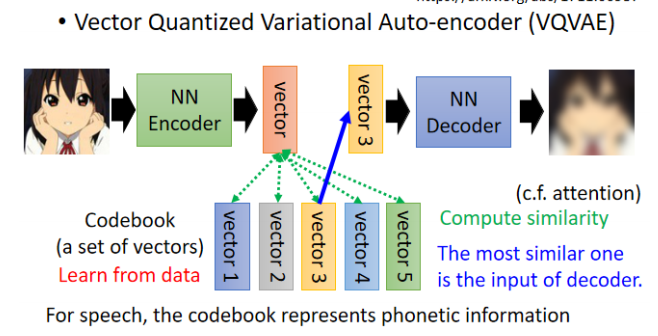
典型技术:VQ-VAE(Vector Quantized Variational Autoencoder)
-
用离散 Codebook 替代连续向量。
-
Encoder 输出 → 与 Codebook 中的向量匹配 → Decoder 重建。
-
类似 Self-Attention 中 Query 与 Key 匹配。
-
可自动学出类似“音标单位”或图像“形状组件”等离散特征。
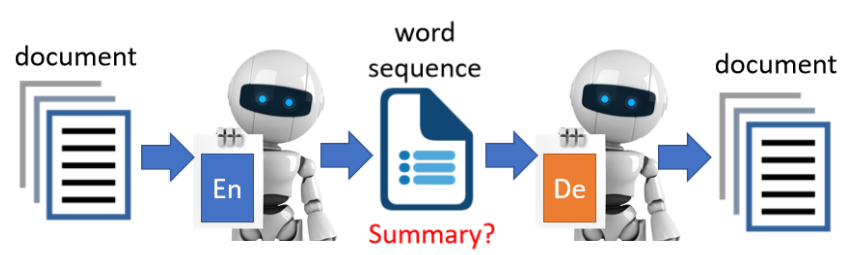
Text as Representation(用文字作为中间表达)
问题:向量不易解读,能否把中间表示变成“文字”?
方案:
-
构建一个“Seq2seq Auto-Encoder”:将长文本编码为一句摘要,再还原为原文。
-
Encoder 输入长文,输出一段文字(摘要),Decoder 从这段文字还原原文。
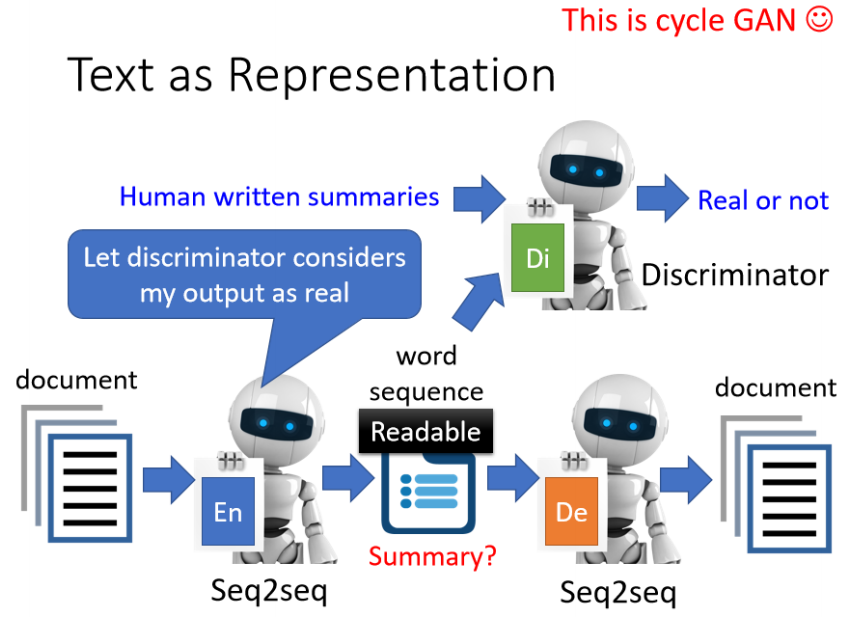
挑战:
-
模型可能发明“乱码密码”作为摘要,人类无法读懂。
解决方法:引入 Discriminator(判别器)
-
判别器负责区分“人类写的句子”与“模型生成的句子”。
-
Encoder 需输出“人类可读的文字”,以欺骗判别器。
-
使用强化学习(RL)优化训练过程。
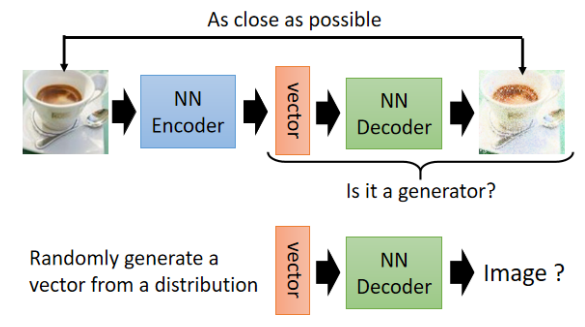
Generator
-
将 Decoder 独立出来使用,即变为一个生成器(类似 GAN 或 VAE)。
-
从高斯分布中采样 latent 向量,丢入 Decoder,生成图像/语音。

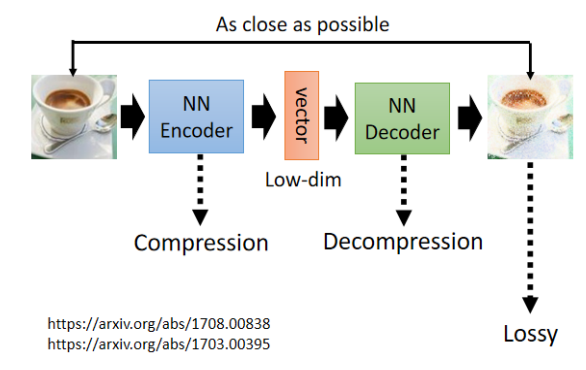
Compression(压缩编码)
-
Encoder → 将图像压缩为低维表示。
-
Decoder → 解压重建原图。
-
属于 lossy 压缩(如 JPEG),可用于数据压缩场景。
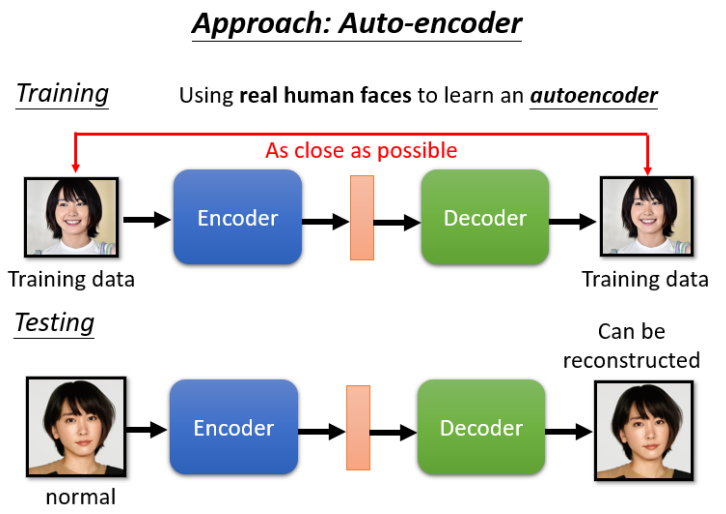
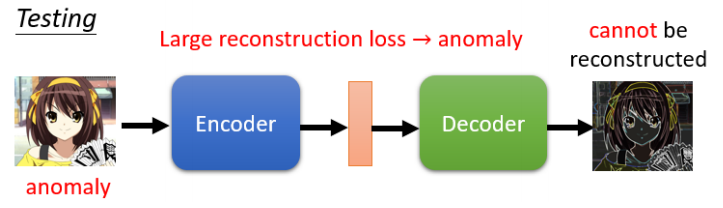
Anomaly Detection(异常检测)
-
应用场景:欺诈侦测、网络入侵检测、医学图像分析等。来了一笔新的资料,它到底跟我们之前在训练资料裡面看过的资料,相不相似?看起来不像是训练资料裡面的 Data,就说它是异常的。
-
流程:
-
使用大量正常数据训练 Auto-Encoder。
-
测试时比较输入与重建图像之间的误差(Reconstruction Loss)。
-
大误差 → 异常,小误差 → 正常。
-
-
适用于 One-Class Learning 问题:仅有正常样本,缺少异常样本。