永年网站制作谷歌官方网站
🌟【技术大咖愚公搬代码:全栈专家的成长之路,你关注的宝藏博主在这里!】🌟
📣开发者圈持续输出高质量干货的"愚公精神"践行者——全网百万开发者都在追更的顶级技术博主!
👉 江湖人称"愚公搬代码",用七年如一日的精神深耕技术领域,以"挖山不止"的毅力为开发者们搬开知识道路上的重重阻碍!
💎【行业认证·权威头衔】
✔ 华为云天团核心成员:特约编辑/云享专家/开发者专家/产品云测专家
✔ 开发者社区全满贯:CSDN博客&商业化双料专家/阿里云签约作者/腾讯云内容共创官/掘金&亚马逊&51CTO顶级博主
✔ 技术生态共建先锋:横跨鸿蒙、云计算、AI等前沿领域的技术布道者
🏆【荣誉殿堂】
🎖 连续三年蝉联"华为云十佳博主"(2022-2024)
🎖 双冠加冕CSDN"年度博客之星TOP2"(2022&2023)
🎖 十余个技术社区年度杰出贡献奖得主
📚【知识宝库】
覆盖全栈技术矩阵:
◾ 编程语言:.NET/Java/Python/Go/Node…
◾ 移动生态:HarmonyOS/iOS/Android/小程序
◾ 前沿领域:物联网/网络安全/大数据/AI/元宇宙
◾ 游戏开发:Unity3D引擎深度解析
每日更新硬核教程+实战案例,助你打通技术任督二脉!
💌【特别邀请】
正在构建技术人脉圈的你:
👍 如果这篇推文让你收获满满,点击"在看"传递技术火炬
💬 在评论区留下你最想学习的技术方向
⭐ 点击"收藏"建立你的私人知识库
🔔 关注公众号获取独家技术内参
✨与其仰望大神,不如成为大神!关注"愚公搬代码",让坚持的力量带你穿越技术迷雾,见证从量变到质变的奇迹!✨ |
文章目录
- 🚀前言
- 🚀一、Scrapy 文件下载
- 🔎1.下载京东外设商品图片
- 🦋1.1 创建 Scrapy 项目
- 🦋1.2 编写爬虫
- 🦋1.3 配置 Pipeline
- 🦋1.4 在 settings.py 中激活 Pipeline
- 🦋1.5 启动爬虫
🚀前言
在前面的章节中,我们已经系统地学习了 Scrapy 框架的基础应用和一些进阶技巧,本篇文章将重点讲解如何使用 Scrapy 实现 文件下载,让你能够抓取网页中的各类文件,如图片、PDF、音视频等。
在爬虫开发中,文件下载是一个非常常见的需求,尤其是在进行图片爬取、资料抓取等项目时,我们需要考虑如何高效地下载和存储文件。Scrapy 提供了非常强大的文件下载支持,能够帮助我们轻松应对这些任务。
在本篇文章中,我们将探讨:
- Scrapy 文件下载的基本原理:了解 Scrapy 如何处理文件下载,掌握文件下载的基本流程。
- 如何配置文件下载功能:通过配置
FILES_STORE等参数,实现文件的下载和存储。 - 下载不同类型的文件:不仅是图片,还可以是各种类型的文件,如PDF、音频、视频等,如何处理不同格式的文件。
- 文件下载的优化与扩展:如何通过 Scrapy 中的中间件和其他组件对文件下载进行优化,以提升下载效率和稳定性。
通过本篇文章的学习,你将能够熟练掌握 Scrapy 文件下载的实现方式,为你的爬虫项目增添更多实用功能。如果你正在处理文件抓取任务,或者希望了解如何更高效地下载和存储文件,那么本篇教程将为你提供全面的解决方案。
🚀一、Scrapy 文件下载
Scrapy 提供了专门处理文件下载的 Pipeline(项目管道),包括 Files Pipeline(文件管道)和 Images Pipeline(图像管道)。两者的使用方式相同,区别在于 Images Pipeline 还支持将所有下载的图片格式转换为 JPEG/RGB 格式,并且可以设置缩略图。
以下以继承 ImagesPipeline 类为例,重写三个方法:
-
file_path():该方法用于返回文件下载的路径,
request参数是当前下载对应的 request 对象。 -
get_media_requests():该方法的第一个参数是
item对象,可以通过 item 获取 URL,并将 URL 加入请求队列进行下载。 -
item_completed():当单个 item 下载完成后调用,用于处理下载失败的图片。
results参数包含该 item 对应的下载结果,包括成功或失败的信息。
🔎1.下载京东外设商品图片
🦋1.1 创建 Scrapy 项目
在命令行窗口中,通过以下命令创建一个名为 imagesDemo 的 Scrapy 项目:
scrapy startproject imagesDemo
接着,在该项目的 spiders 文件夹内创建 imagesSpider.py 爬虫文件,并在 items.py 文件中定义存储商品名称和图片地址的 Field() 对象:
import scrapyclass ImagesDemoItem(scrapy.Item):wareName = scrapy.Field() # 存储商品名称imgPath = scrapy.Field() # 存储商品图片地址
🦋1.2 编写爬虫
在 imagesSpider.py 文件中,首先导入 json 模块,并重写 start_requests() 方法来获取 JSON 数据。然后在 parse() 方法中提取商品名称和图片地址。
# -*- coding: utf-8 -*-
import scrapy # 导入scrapy模块
import json # 导入json模块
# 导入ImagesdemoItem类
from imagesDemo.items import ImagesdemoItem
class ImgesspiderSpider(scrapy.Spider):name = 'imgesSpider' # 爬虫名称allowed_domains = ['ch.jd.com'] # 域名列表start_urls = ['http://ch.jd.com/'] # 网络请求初始列表def start_requests(self):url = 'http://ch.jd.com/hotsale2?cateid=686' # 获取json信息的请求地址yield scrapy.Request(url, self.parse) # 发送网络请求def parse(self, response):data = json.loads(response.text) # 将返回的json信息转换为字典products = data['products'] # 获取所有数据信息for image in products: # 循环遍历信息item = ImagesdemoItem() # 创建item对象item['wareName'] = image.get('wareName').replace('/','') # 存储商品名称# 存储商品对应的图片地址item['imgPath'] = 'http://img12.360buyimg.com/n1/s320x320_' + image.get('imgPath')yield item# 导入CrawlerProcess类
from scrapy.crawler import CrawlerProcess
# 导入获取项目设置信息
from scrapy.utils.project import get_project_settings# 程序入口
if __name__ == '__main__':# 创建CrawlerProcess类对象并传入项目设置信息参数process = CrawlerProcess(get_project_settings())# 设置需要启动的爬虫名称process.crawl('imgesSpider')# 启动爬虫process.start()
🦋1.3 配置 Pipeline
在 pipelines.py 文件中,导入 ImagesPipeline 类,继承该类并重写 file_path() 和 get_media_requests() 方法。
from scrapy.pipelines.images import ImagesPipeline # 导入ImagesPipeline类
import scrapy # 导入scrapy
class ImagesdemoPipeline(ImagesPipeline): # 继承ImagesPipeline类# 设置文件保存的名称def file_path(self, request, response=None, info=None):file_name = request.meta['name']+'.jpg' # 将商品名称设置为图片名称return file_name # 返回文件名称# 发送获取图片的网络请求def get_media_requests(self, item, info):# 发送网络请求并传递商品名称yield scrapy.Request(item['imgPath'],meta={'name':item['wareName']})# def process_item(self, item, spider):# return item
🦋1.4 在 settings.py 中激活 Pipeline
在 settings.py 文件中激活 ITEM_PIPELINES 配置,并指定图片下载后的保存路径。
ITEM_PIPELINES = {'imagesDemo.pipelines.ImagesDemoPipeline': 300,
}IMAGES_STORE = './images' # 图片保存的文件夹路径
🦋1.5 启动爬虫
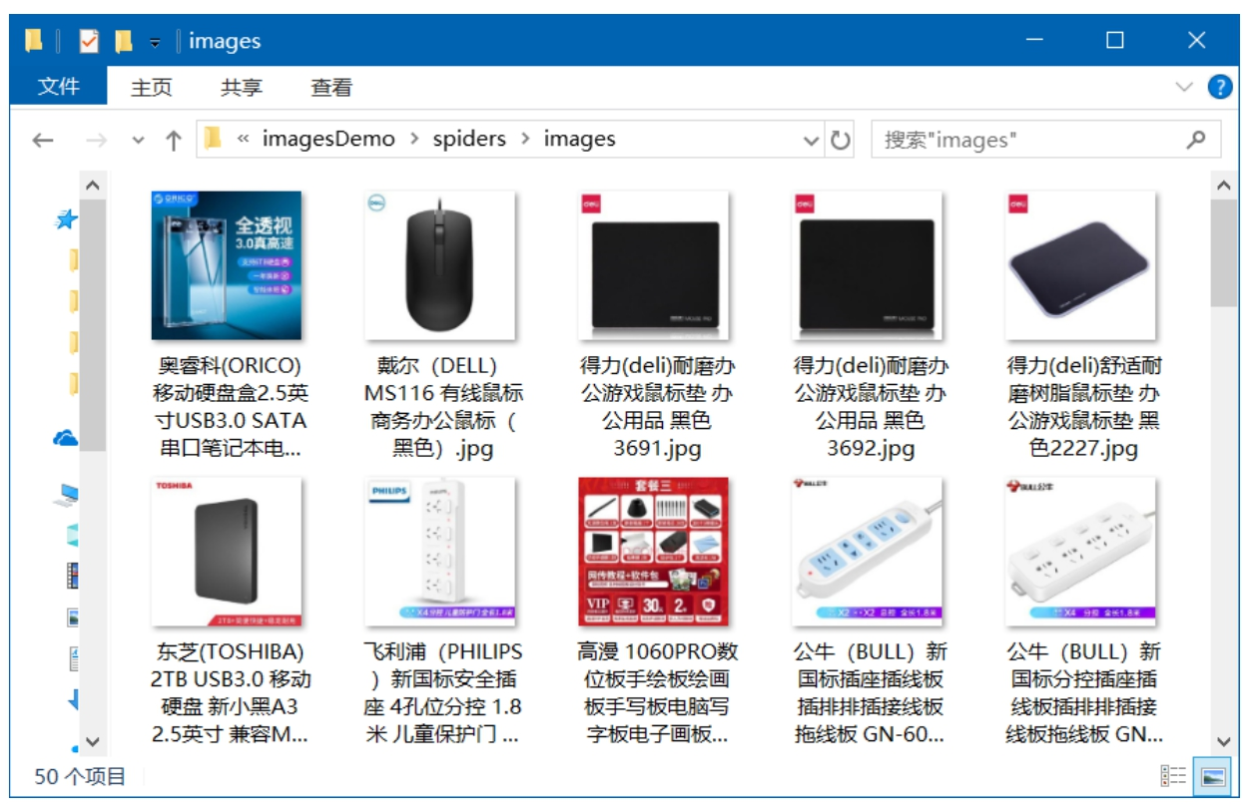
启动 imagesSpider 爬虫,下载完成后,打开项目结构中的 images 文件夹,可以查看下载的商品图片。