手机网站静态动态拉新app推广平台排名
目录
0 环境准备
1 安装tesseract-ocr引擎
1.1 下载安装包
1.2 安装tesseract-ocr
1.2.1 选择语言
1.2.2 开始安装
1.2.3 同意安装协议
1.2.4 选择安装用户
1.2.5 选择安装组件
1.2.6 选择安装路径
1.2.7 系统安装tesseract-ocr
1.2.8 完成安装
1.2.9 结束安装
1.3 设置环境变量
1.4 验证是否安装成功
1.5 安装简体中文语言包
1.5.1 下载简体中文语言包
1.5.2 放置简体中文语言包
1.5.3 查看简体中文语言包是否安装成功
2 创建项目python环境
2.1 conda创建python环境
2.2 在pycharm中创建项目
2.3 激活python环境
2.4 安装项目依赖包
3 程序逻辑实现
3.1 导入依赖包
3.2 定义PDFOCR类
3.3 定义初始化方法
3.4 定义pdf转换成照片方法
3.5 定义OCR识别照片方法
3.6 定义清楚缓存资源方法
3.7 实现main方法
4 测试验证
5 完整代码
附录
附录一:项目结构
附录二: 可能存在的问题
问题一:找不到tesseract路径
0 环境准备
- 已安装miniconda环境
- 具备科学上网条件
1 安装tesseract-ocr引擎
Python读取扫描版PDF文件的详细解决方案,结合OCR技术和PyMuPDF库实现,代码需兼容中英文识别。OCR技术需要安装tesseract-ocr引擎,本章节将介绍在windows环境下如何安装tesseract-ocr引擎。
1.1 下载安装包
windows环境访问以下地址下载tesseract-ocr安装包,需要科学上网。
windows下载地址:Home · UB-Mannheim/tesseract Wiki · GitHub
1.2 安装tesseract-ocr
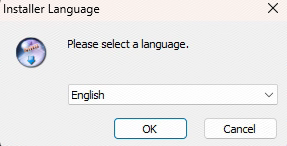
1.2.1 选择语言
选择英语,点击ok。
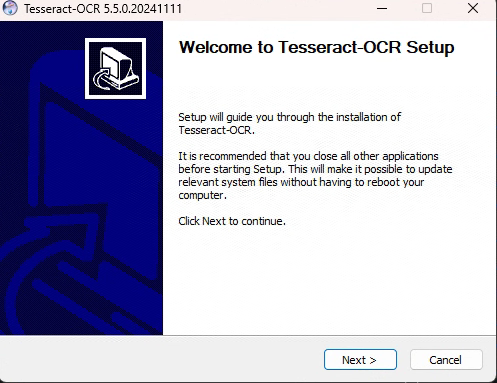
1.2.2 开始安装
点击next开始安装。
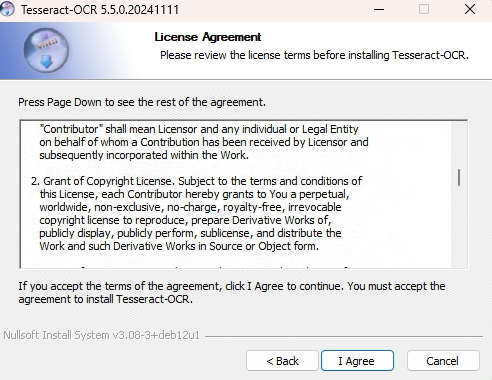
1.2.3 同意安装协议
点击I Agree。
1.2.4 选择安装用户
选择Install for anyone using this compoter。点击next。

1.2.5 选择安装组件
这里直接点击next
1.2.6 选择安装路径
注意选择不要带有空格、中文、特殊字符的安装路径。防止使用过程出现莫名其妙的问题。安装路径选择完成后点击next。
1.2.7 系统安装tesseract-ocr
这里直接点击install。
1.2.8 完成安装
这里直接点击next。
1.2.9 结束安装
这里直接点击finish。
1.3 设置环境变量
在系统环境变量Path中添加tesseract-ocr目录

1.4 验证是否安装成功
在命令行中输入tesseract -v 查看是否能正常看到tesseract的版本信息,如下图
tesseract -v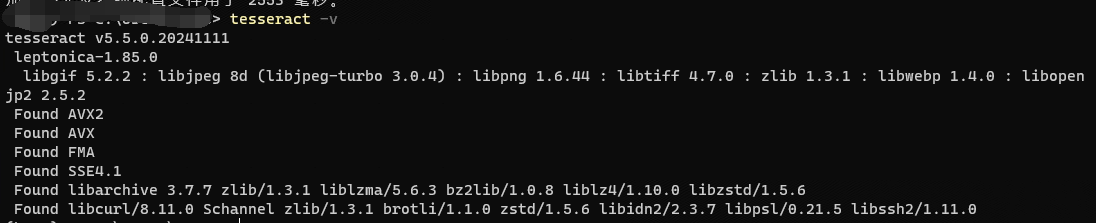
1.5 安装简体中文语言包
Tesseract 默认不支持中文,若要识别中文,需要下载相应的语言包。
1.5.1 下载简体中文语言包
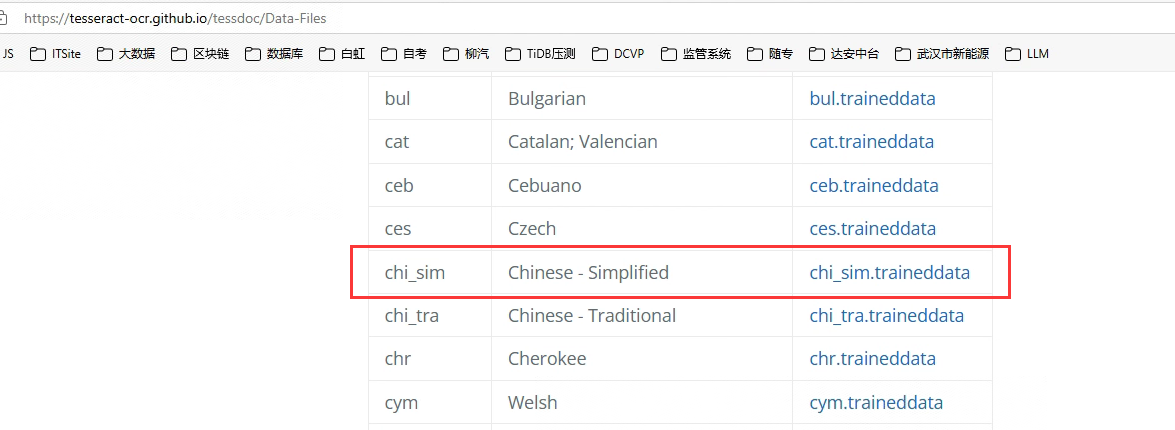
可以从以下地址下载简体中文语言包:
官网下载:Traineddata Files for Version 4.00 + | tessdoc ,找到 Chinese - Simplified 对应的语言包下载。需要科学上网。
1.5.2 放置简体中文语言包
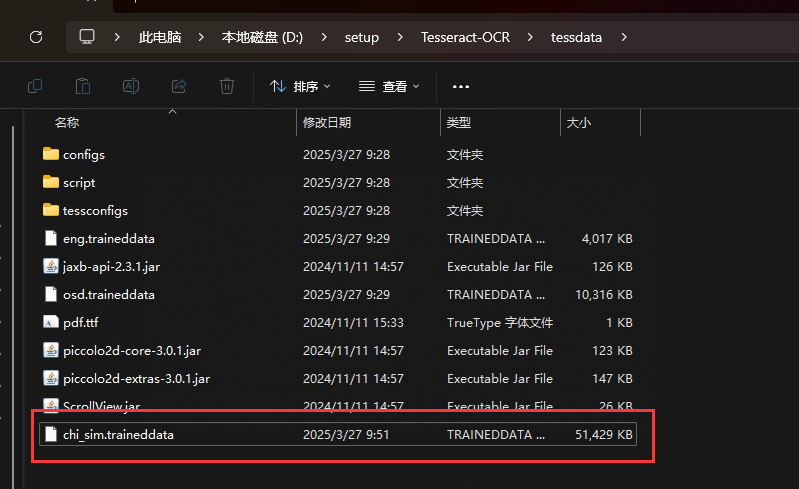
将下载的chi_sim.traineddata文件放置到Tesseract-OCR的数据目录,本机是D:\setup\Tesseract-OCR\tessdata。请修改成自己的安装地址。
1.5.3 查看简体中文语言包是否安装成功
输入查询支持语言命令,可以看到安装的chi_sim语言,如下图:
tesseract --list-langs
2 创建项目python环境
2.1 conda创建python环境
conda create -n pdf_ocr_demo python=3.102.2 在pycharm中创建项目
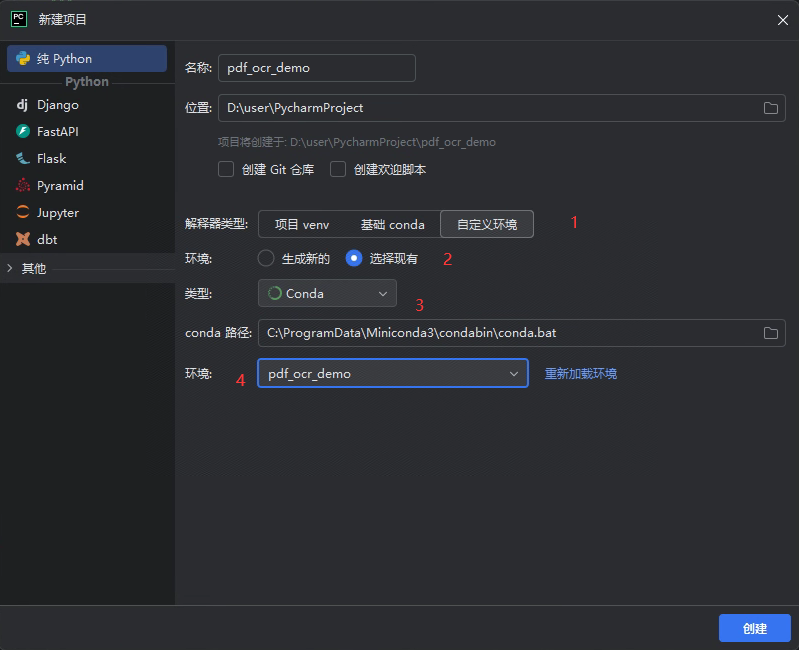
- 解释器类型:选择自定义环境
- 环境:选择现有
- 类型:选择conda
- 环境:选择上一步创建的pdf_ocr_demo环境
2.3 激活python环境
conda activate pdf_ocr_demo2.4 安装项目依赖包
pip install PyMuPDF pytesseract pillow3 程序逻辑实现
3.1 导入依赖包
import osimport fitz
import pytesseractfrom PIL import Image3.2 定义PDFOCR类
class PDFOCR:3.3 定义初始化方法
def __init__(self, file_path, output_txt):self.file_path = file_pathself.output_txt = output_txtself.temp_img_dir = 'temp_imgs'os.makedirs(self.temp_img_dir, exist_ok=True)3.4 定义pdf转换成照片方法
def _pdf_to_images(self, zoom=3):"""将PDF每页转换为高清图片"""doc = fitz.open(self.file_path)for page_num in range(len(doc)):page = doc.load_page(page_num)# 设置缩放参数提升分辨率mat = fitz.Matrix(zoom, zoom)pix = page.get_pixmap(matrix=mat, alpha=False)p_index = page_num + 1p_index = str(p_index).zfill(5)img_path = os.path.join(self.temp_img_dir, f'page_{p_index}.png')pix.save(img_path)print(f"已完成 {img_path} 存储")doc.close()3.5 定义OCR识别照片方法
def _ocr_images(self):"""对转换后的图片进行OCR识别"""with open(self.output_txt, 'w', encoding='utf-8') as f:for img_file in sorted(os.listdir(self.temp_img_dir)):img_path = os.path.join(self.temp_img_dir, img_file)# 图像预处理img = Image.open(img_path).convert('L') # 转为灰度图# OCR识别text = pytesseract.image_to_string(img, lang='chi_sim+eng') # 简体中文f.write(text + '\n')print(f"已完成 {img_file} 识别")3.6 定义清楚缓存资源方法
def _cleanup(self):"""清理临时文件"""for img_file in os.listdir(self.temp_img_dir):os.remove(os.path.join(self.temp_img_dir, img_file))os.rmdir(self.temp_img_dir)print("清理完成")3.7 实现main方法
if __name__ == '__main__':processor = PDFOCR('./in_pdf/617336.pdf', './out/output.txt')try:processor._pdf_to_images(zoom=3)processor._ocr_images()finally:processor._cleanup()4 测试验证
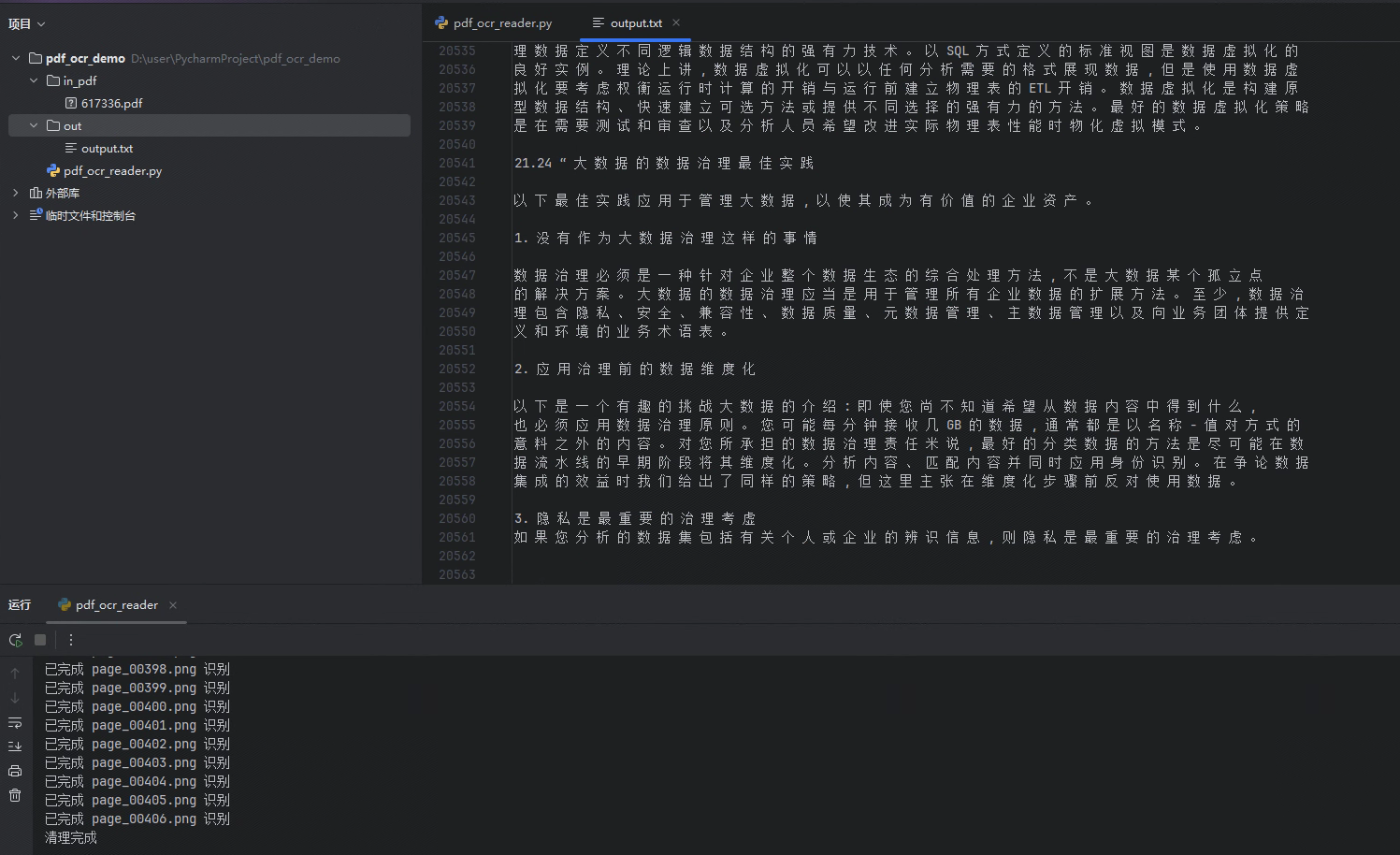
找一个扫描版PDF文件,放入in_pdf文件夹,修改main方法中pdf文件名,运行pdf_ocr_reader.py,可以看到执行结果如下图:
5 完整代码
import osimport fitz
import pytesseractfrom PIL import Imageclass PDFOCR:def __init__(self, file_path, output_txt):self.file_path = file_pathself.output_txt = output_txtself.temp_img_dir = 'temp_imgs'os.makedirs(self.temp_img_dir, exist_ok=True)def _pdf_to_images(self, zoom=3):"""将PDF每页转换为高清图片"""doc = fitz.open(self.file_path)for page_num in range(len(doc)):page = doc.load_page(page_num)# 设置缩放参数提升分辨率mat = fitz.Matrix(zoom, zoom)pix = page.get_pixmap(matrix=mat, alpha=False)p_index = page_num + 1p_index = str(p_index).zfill(5)img_path = os.path.join(self.temp_img_dir, f'page_{p_index}.png')pix.save(img_path)print(f"已完成 {img_path} 存储")doc.close()def _ocr_images(self):"""对转换后的图片进行OCR识别"""with open(self.output_txt, 'w', encoding='utf-8') as f:for img_file in sorted(os.listdir(self.temp_img_dir)):img_path = os.path.join(self.temp_img_dir, img_file)# 图像预处理img = Image.open(img_path).convert('L') # 转为灰度图# OCR识别text = pytesseract.image_to_string(img, lang='chi_sim+eng') # 简体中文f.write(text + '\n')print(f"已完成 {img_file} 识别")def _cleanup(self):"""清理临时文件"""for img_file in os.listdir(self.temp_img_dir):os.remove(os.path.join(self.temp_img_dir, img_file))os.rmdir(self.temp_img_dir)print("清理完成")if __name__ == '__main__':processor = PDFOCR('./in_pdf/617336.pdf', './out/output.txt')try:processor._pdf_to_images(zoom=3)processor._ocr_images()finally:processor._cleanup()附录
附录一:项目结构

附录二: 可能存在的问题
问题一:找不到tesseract路径
pytesseract.pytesseract.TesseractNotFoundError: tesseract is not installed or it's not in your PATH. See README file for more information.解决办法:
请确认环境变量Path中是否配置tesseract的路径,参考章节1.3。如果确认已配置,则重启pycharm,重新运行程序。