ASP.NET实用网站开发答案整站优化加盟
数据结构中的树结构常用来存储逻辑关系为 "一对多" 的数据。树结构可以细分为两类,分别是二叉树和非二叉树(普通树),存储它们的方案是不一样的:
- 二叉树的存储方案有 2 种,既可以用顺序表存储二叉树,也可以用链表存储二叉树;
- 普通树的存储方案有 3 种,分别叫做孩子表示法、双亲表示法和孩子兄弟表示法。
这篇文章篇幅较长,我会给大家详细介绍两种树结构的各个存储方法,并提供完整的 C 语言实现源码。

二叉树的存储
树是一种非线性存储结构,一棵树由多个逻辑关系为“一对多”的结点构成,这些结点之间的关系可以用父子、兄弟、表兄弟等称谓描述。
理论上,一棵树上的各个结点可以有任意个孩子。但是,如果一棵树具备以下两个特征:
- 本身是一棵有序树,即各个结点的孩子位置不能改变;
- 树中各个结点的度(子树个数)不能超过 2,即只能是 0、1 或者 2。
同时具备这 2 个特征的树就称为「二叉树」。
例如下图画了两棵有序树,图 1a) 是二叉树,而图 1b) 不是,因为它的根结点的度为 3,不具备第 2 个特征。

图 1 二叉树示意图
1) 二叉树的顺序存储结构
二叉树的顺序存储,指的是使用顺序表(数组)存储二叉树。对的,你没有看错,虽然树是非线性存储结构,但也可以用顺序表存储。
需要注意的是,顺序存储只适用于完全二叉树。对于普通的二叉树,必须先将其转化为完全二叉树,才能存储到顺序表中。
满二叉树也是完全二叉树,可以直接用顺序表存储。
一棵普通二叉树转化为完全二叉树的方法很简单,只需要给二叉树额外添加一些结点,就可以把它"拼凑"成完全二叉树。如图 1 所示:
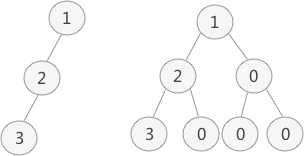
图 1 普通二叉树的转化
图 1 左侧是普通二叉树,右侧是转化后的完全(满)二叉树。解决了二叉树的转化问题,接下来学习如何顺序存储完全(满)二叉树。
所谓顺序存储完全二叉树,就是从树的根结点开始,按照层次将树中的结点逐个存储到数组中。
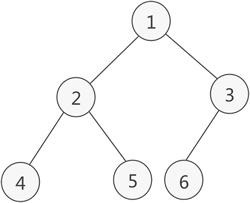
图 2 完全二叉树示意图
例如存储图 2 中的完全二叉树,各个结点在顺序表中的存储状态如图 3 所示:

图 3 完全二叉树存储状态示意图
存储由普通二叉树转化来的完全二叉树也是如此,比如将图 1 中的普通二叉树存储到顺序表中,树中结点的存储状态如图 4 所示:

图 4 普通二叉树的存储状态
由此就实现了完全二叉树的顺序存储。
二叉树的顺序存储结构用 C 语言表示为:
#define NODENUM 7 //二叉树中的结点数量
#define ElemType int //结点值的类型
//自定义 BiTree 类型,表示二叉树
typedef ElemType BiTree[MaxSize];下面是用 BiTree 存储图 1 中二叉树的 C 语言代码:
/**
* 快速入门数据结构 https://xiecoding.cn/ds/
**/
#include <stdio.h>
#define NODENUM 7
#define ElemType int
//自定义 BiTree 类型,表示二叉树
typedef ElemType BiTree[NODENUM];//存储二叉树
void InitBiTree(BiTree T) {ElemType node;int i = 0;printf("按照层次从左往右输入树中结点的值,0 表示空结点,# 表示输入结束:");while (scanf("%d", &node)){T[i] = node;i++;}
}
//查找某个结点的双亲结点的值
ElemType Parent(BiTree T, ElemType e) {int i;if (T[0] == 0) {printf("存储的是一棵空树\n");}else{if (T[0] == e) {printf("当前结点是根节点,没有双亲结点\n");return 0;}for (i = 1; i < NODENUM; i++) {if (T[i] == e) {//借助各个结点的标号(数组下标+1),找到双亲结点的存储位置return T[(i + 1) / 2 - 1];}}printf("二叉树中没有指定结点\n");}return -1;
}//查找某个结点的左孩子结点的值
ElemType LeftChild(BiTree T, ElemType e) {int i;if (T[0] == 0) {printf("存储的是一棵空树\n");}else{for (i = 1; i < NODENUM; i++) {if (T[i] == e) {//借助各个结点的标号(数组下标+1),找到左孩子结点的存储位置if (((i + 1) * 2 < NODENUM) && (T[(i + 1) * 2 - 1] != 0)) {return T[(i + 1) * 2 - 1];}else{printf("当前结点没有左孩子\n");return 0;}}}printf("二叉树中没有指定结点\n");}return -1;
}//查找某个结点的右孩子结点的值
ElemType RightChild(BiTree T, ElemType e) {int i;if (T[0] == 0) {printf("存储的是一棵空树\n");}else{for (i = 1; i < NODENUM; i++) {if (T[i] == e) {//借助各个结点的标号(数组下标+1),找到左孩子结点的存储位置if (((i + 1) * 2 + 1 < NODENUM) && (T[(i + 1) * 2] != 0)) {return T[(i + 1) * 2];}else{printf("当前结点没有右孩子\n");return 0;}}}printf("二叉树中没有指定结点\n");}return -1;
}int main() {int res;BiTree T = { 0 };InitBiTree(T);res = Parent(T, 3);if (res != 0 && res != -1) {printf("结点3的双亲结点的值为 %d\n", res);}res = LeftChild(T, 2);if (res != 0 && res != -1) {printf("结点2的左孩子的值为 %d\n", res);}res = RightChild(T, 2);if (res != 0 && res != -1) {printf("结点2的右孩子的值为 %d\n", res);}return 0;
}执行结果是:
按照层次从左往右输入树中结点的值,0 表示空结点,# 表示输入结束:1 2 0 3 #
结点3的双亲结点的值为 2
结点2的左孩子的值为 3
当前结点没有右孩子
程序中实现查找某个结点的双亲结点和孩子结点,用到了完全二叉树具有的性质:将树中节点按照层次并从左到右依次标号 1、2、3、...(程序中用数组下标+1 表示),若节点 i 有左右孩子,则其左孩子节点的标号为 2*i,右孩子节点的标号为 2*i+1。
2) 二叉树的链式存储结构
上一节介绍了二叉树的顺序存储结构,通过学习你会发现,其实二叉树并不适合用顺序表存储,因为并不是每个二叉树都是完全二叉树,普通二叉树使用顺序表存储或多或多会存在内存浪费的情况。
本节我们学习二叉树的链式存储结构。

图 1 普通二叉树示意图
所谓二叉树的链式存储,其实就是用链表存储二叉树,具体的存储方案是:从树的根节点开始,将各个节点及其左右孩子使用链表存储。例如图 1 是一棵普通的二叉树,如果选择用链表存储,各个结点的存储状态如下图所示:

图 2 二叉树链式存储结构示意图
由图 2 可知,采用链式存储二叉树时,树中的结点由 3 部分构成(如图 3 所示):
- 指向左孩子节点的指针(Lchild);
- 节点存储的数据(data);
- 指向右孩子节点的指针(Rchild);

图 3 二叉树节点结构
表示节点结构的 C 语言代码为:
typedef struct BiTNode{TElemType data;//数据域struct BiTNode *lchild,*rchild;//左右孩子指针
}BiTNode,*BiTree;用链表存储图 2 所示的二叉树,对应的 C 语言程序为:
/**
* 快速入门数据结构 https://xiecoding.cn/ds/
**/
#include <stdio.h>
#include <stdlib.h>
#define TElemType inttypedef struct BiTNode {TElemType data;//数据域struct BiTNode* lchild, * rchild;//左右孩子指针
}BiTNode, * BiTree;void CreateBiTree(BiTree* T) {*T = (BiTNode*)malloc(sizeof(BiTNode));(*T)->data = 1;(*T)->lchild = (BiTNode*)malloc(sizeof(BiTNode));(*T)->lchild->data = 2;(*T)->rchild = (BiTNode*)malloc(sizeof(BiTNode));(*T)->rchild->data = 3;(*T)->rchild->lchild = NULL;(*T)->rchild->rchild = NULL;(*T)->lchild->lchild = (BiTNode*)malloc(sizeof(BiTNode));(*T)->lchild->lchild->data = 4;(*T)->lchild->rchild = NULL;(*T)->lchild->lchild->lchild = NULL;(*T)->lchild->lchild->rchild = NULL;
}//后序遍历二叉树,释放树占用的内存
void DestroyBiTree(BiTree T) {if (T) {DestroyBiTree(T->lchild);//销毁左孩子DestroyBiTree(T->rchild);//销毁右孩子free(T);//释放结点占用的内存}
}int main() {BiTree Tree;CreateBiTree(&Tree);printf("根节点的左孩子结点为:%d\n", Tree->lchild->data);printf("根节点的右孩子结点为:%d\n", Tree->rchild->data);DestroyBiTree(Tree);return 0;
}程序输出结果:
根节点的左孩子结点为:2
根节点的右孩子结点为:3
实际上,二叉树的链式存储结构远不止图 2 所示的这一种。某些实际场景中,可能会在树中做类似 "查找某节点的父节点" 的操作,可以在节点结构中再添加一个指针域,用于各个节点指向它的父亲节点,如图 4 所示:

图 4 自定义二叉树的链式存储结构
这样的链表结构,通常称为三叉链表。
利用图 4 所示的三叉链表,可以很轻松地找到各节点的父节点。因此,在解决实际问题时,构建合适的链表结构存储二叉树,可以起到事半功倍的效果。
非二叉树(普通树)的存储
前面用大量的篇幅讲解了二叉树,从本节开始带领大家研究普通的树存储结构。

图 1 普通树存储结构
如图 1 所示,这是一棵普通的树,该如何存储呢?通常,存储具有普通树结构数据的方法有 3 种:
- 双亲表示法;
- 孩子表示法;
- 孩子兄弟表示法;
1) 树的双亲表示法
双亲表示法采用顺序表(也就是数组)存储普通树,其实现的核心思想是:顺序存储各个节点的同时,给各节点附加一个记录其父节点位置的变量。
注意,根节点没有父节点(父节点又称为双亲节点),因此根节点记录父节点位置的变量通常置为 -1。
例如,采用双亲表示法存储图 1 中普通树,其存储状态如图 2 所示:

图 2 双亲表示法存储普通树示意图
图 2 存储普通树的过程转化为 C 语言代码为:
#define MAX_SIZE 20 //树中结点的最大数量
typedef char ElemType; //数据的类型
typedef struct Snode //结点结构
{ElemType data;int parent;
}PNode;
typedef struct //树结构
{PNode tnode[MAX_SIZE];int r, n; //树根的位置下标和结点数
}PTree;以图 1 中的树结构为例,采用双亲表示法存储它的 C 语言实现代码为:
/**
* 快速入门数据结构 https://xiecoding.cn/ds/
**/
#include<stdio.h>
#include<stdlib.h>
#include<string.h>
#define MAX_SIZE 20 //树中结点的最大数量
typedef char ElemType; //数据的类型
typedef struct Snode //结点结构
{ElemType data;int parent;
}PNode;typedef struct //树结构
{PNode tnode[MAX_SIZE];int r, n; //树根的位置下标和结点数
}PTree;void InitPNode(PTree* tree)
{int i, j;char ch;printf("请输出节点个数:\n");scanf("%d", &((*tree).n));printf("请输入结点的值其双亲位于数组中的位置下标:\n");for (i = 0; i < (*tree).n; i++){getchar();scanf("%c %d", &ch, &j);if (j == -1) {(*tree).r = i;}(*tree).tnode[i].data = ch;(*tree).tnode[i].parent = j;}
}
//找某个结点的父结点
void FindParent(PTree tree)
{char a;int isfind = 0, i, ad;printf("请输入孩子结点的值:\n");scanf("%*[^\n]"); scanf("%*c");//清空输入缓冲区scanf("%c", &a);for (i = 0; i < tree.n; i++) {if (tree.tnode[i].data == a) {isfind = 1;ad = tree.tnode[i].parent;printf("%c 的父节点为 %c,存储位置下标为 %d\n", a, tree.tnode[ad].data, ad);break;}}if (isfind == 0) {printf("树中无此节点\n");}
}
//找某个结点的孩子结点
void FindChilds(PTree tree)
{char a;int i, j;int isfind = 0;printf("请输入要父亲结点的值:\n");scanf("%*[^\n]"); scanf("%*c");//清空输入缓冲区scanf("%c", &a);for (i = 0; i < tree.n; i++) {if (tree.tnode[i].data == a) {for (j = 0; j < tree.n; j++) {if (tree.tnode[j].parent == i) {isfind = 1;printf("%c 是 %c 的孩子\n", tree.tnode[j].data, a);}}if (isfind == 0) {printf("%c没有孩子结点\n", a);}}}
}int main()
{PTree tree;memset(&tree, 0, sizeof(PTree));InitPNode(&tree);FindParent(tree);FindChilds(tree);return 0;
}运行结果为:
请输出节点个数: 10 请输入结点的值其双亲位于数组中的位置下标: R -1 A 0 B 0 C 0 D 1 E 1 F 3 G 6 H 6 K 6 请输入孩子结点的值: C C 的父节点为 R,存储位置下标为 0 请输入要父亲结点的值: F G 是 F 的孩子 H 是 F 的孩子 K 是 F 的孩子
2) 树的孩子表示法
前面学习了如何用双亲表示法存储普通树,本节再学习一种存储普通树的方法——孩子表示法。
孩子表示法存储普通树采用的是 "顺序表+链表" 的组合结构,其存储过程是:从树的根节点开始,使用顺序表依次存储树中各个节点。需要注意,与双亲表示法不同的是,孩子表示法会给各个节点配备一个链表,用于存储各节点的孩子节点位于顺序表中的位置。
如果节点没有孩子节点(叶子节点),则该节点的链表为空链表。
例如,使用孩子表示法存储图 1a) 中的普通树,则最终存储状态如图 1b) 所示:

图 1 孩子表示法存储普通树示意图
图 1 所示转化为 C 语言代码为:
/**
* 快速入门数据结构 https://xiecoding.cn/ds/
**/
#include<stdio.h>
#include<stdlib.h>
#define MAX_SIZE 20
#define TElemType char
//孩子表示法
typedef struct CTNode {int child;//链表中每个结点存储的不是数据本身,而是数据在数组中存储的位置下标struct CTNode* next;
}ChildPtr;
typedef struct {TElemType data;//结点的数据类型ChildPtr* firstchild;//孩子链表的头指针
}CTBox;
typedef struct {CTBox nodes[MAX_SIZE];//存储结点的数组int n, r;//结点数量和树根的位置
}CTree;
//孩子表示法存储普通树
void initTree(CTree* tree) {int i, num;printf("从根结点开始输入各个结点的值:\n");for (i = 0; i < tree->n; i++) {printf("--输入第 %d 个节点的值:", i + 1);scanf("%c", &(tree->nodes[i].data));tree->nodes[i].firstchild = NULL;printf("----输入节点 %c 的孩子节点数量:", tree->nodes[i].data);scanf("%d", &num);if (num != 0) {tree->nodes[i].firstchild = (ChildPtr*)malloc(sizeof(ChildPtr));tree->nodes[i].firstchild->next = NULL;printf("------输入第 1 个孩子结点在顺序表中的位置:");scanf("%d", &(tree->nodes[i].firstchild->child));ChildPtr* p = tree->nodes[i].firstchild;for (int j = 1; j < num; j++) {ChildPtr* newEle = (ChildPtr*)malloc(sizeof(ChildPtr));newEle->next = NULL;printf("------输入第 %d 个孩子节点在顺序表中的位置:", j + 1);scanf("%d", &(newEle->child));p->next = newEle;p = p->next;}}scanf("%*[^\n]"); scanf("%*c");}
}
//找某个结点的孩子
void findKids(CTree tree, char a) {int i, hasKids = 0;for (i = 0; i < tree.n; i++) {if (tree.nodes[i].data == a) {ChildPtr* p = tree.nodes[i].firstchild;while (p) {hasKids = 1;printf("%c ", tree.nodes[p->child].data);p = p->next;}break;}}if (hasKids == 0) {printf("此节点为叶子节点");}
}
//释放各个链表占用的内存
void deleteTree(CTree tree) {int i;//逐个遍历链表for (i = 0; i < tree.n; i++) {ChildPtr* p = tree.nodes[i].firstchild;//释放链表中的各个结点while (p) {ChildPtr* next = p;p = p->next;free(next);}}
}
int main()
{CTree tree = { 0 };tree.n = 10;tree.r = 0;initTree(&tree);printf("找出节点 F 的所有孩子节点:");findKids(tree, 'F');deleteTree(tree);return 0;
}程序运行结果为:
从根结点开始输入各个结点的值: --输入第 1 个节点的值:R ----输入节点 R 的孩子节点数量:3 ------输入第 1 个孩子结点在顺序表中的位置:1 ------输入第 2 个孩子节点在顺序表中的位置:2 ------输入第 3 个孩子节点在顺序表中的位置:3 --输入第 2 个节点的值:A ----输入节点 A 的孩子节点数量:2 ------输入第 1 个孩子结点在顺序表中的位置:4 ------输入第 2 个孩子节点在顺序表中的位置:5 --输入第 3 个节点的值:B ----输入节点 B 的孩子节点数量:0 --输入第 4 个节点的值:C ----输入节点 C 的孩子节点数量:1 ------输入第 1 个孩子结点在顺序表中的位置:6 --输入第 5 个节点的值:D ----输入节点 D 的孩子节点数量:0 --输入第 6 个节点的值:E ----输入节点 E 的孩子节点数量:0 --输入第 7 个节点的值:F ----输入节点 F 的孩子节点数量:3 ------输入第 1 个孩子结点在顺序表中的位置:7 ------输入第 2 个孩子节点在顺序表中的位置:8 ------输入第 3 个孩子节点在顺序表中的位置:9 --输入第 8 个节点的值:G ----输入节点 G 的孩子节点数量:0 --输入第 9 个节点的值:H ----输入节点 H 的孩子节点数量:0 --输入第 10 个节点的值:K ----输入节点 K 的孩子节点数量:0 找出节点 F 的所有孩子节点:G H K
使用孩子表示法存储的树结构,正好和双亲表示法相反,查找孩子结点的效率很高,而不擅长做查找父结点的操作。
我们还可以将双亲表示法和孩子表示法合二为一,那么图 1a) 中普通树的存储效果如图 2 所示:

图 2 双亲孩子表示法
使用图 2 结构存储普通树,既能快速找到指定节点的父节点,又能快速找到指定节点的孩子节点。该结构的实现方法很简单,只需整合这两节的代码即可,这里不再赘述。
3) 树的孩子兄弟表示法
前面讲解了存储普通树的双亲表示法和孩子表示法,本节来讲解最后一种常用方法——孩子兄弟表示法。

图 1 普通树示意图
在树结构中,同一层的节点互为兄弟节点。例如图 1 的普通树中,节点 A、B 和 C 互为兄弟节点,而节点 D、E 和 F 也互为兄弟节点。
所谓孩子兄弟表示法,指的是用将整棵树用二叉链表存储起来,具体实现方案是:从树的根节点开始,依次存储各个结点的孩子结点和兄弟结点。
在二叉链表中,各个结点包含三部分内容(如图 2 所示):
- 节点的值;
- 指向孩子结点的指针;
- 指向兄弟结点的指针;

图 2 结点结构示意图
用 C 语言代码表示结点结构为:
#define ElemType char
typedef struct CSNode{ElemType data;struct CSNode * firstchild,*nextsibling;
}CSNode,*CSTree;以图 1 为例,使用孩子兄弟表示法进行存储的结果如图 3 所示:

图 3 孩子兄弟表示法示意图
由图 3 可以看到,节点 R 无兄弟节点,其孩子节点是 A;节点 A 的兄弟节点分别是 B 和 C,其孩子节点为 D,依次类推。
在以孩子兄弟表示法构建的二叉链表中,如果要查找结点 x 的所有孩子,则只要根据该结点的 firstchild 指针找到它的第一个孩子,然后沿着孩子结点的 nextsibling 指针不断地找它的兄弟结点,就可以找到结点 x 的所有孩子。
实现图 3 中的 C 语言实现代码也很简单,根据图中链表的结构即可轻松完成链表的创建和使用,因此不再给出具体代码。
观察图 1 和图 3。图 1 为原普通树,图 3 是由图 1 经过孩子兄弟表示法转化而来的一棵树,确切地说图 3 是一棵二叉树。因此可以得出这样一个结论,即通过孩子兄弟表示法,任意一棵普通树都可以相应转化为一棵二叉树,它们是一一对应的。
因此,孩子兄弟表示法可以作为将普通树转化为二叉树的最有效方法,通常又被称为"二叉树表示法"或"二叉链表表示法"。
