太原专业制作网站广州短视频代运营
D3D12有 计算、3D 和复制 三大引擎,3D图形已作了基本的介绍,本章讲计算着色器,通过GPU实现两个矩阵相加的例子来介绍计算引擎。与以往不同的是
- 项目工程使用vs2022来让编写代码。
- Shader.hlsl程序用vs来编译,弃用D3DCompileFromFile编译
- 一些通用的操作封装成一个基类,子类继承方式
两个矩阵相加: 矩阵A+矩阵B= 矩阵C ,矩阵结构如下
struct MatrixBuffer{XMFLOAT4X4 atrix;float padding[48];};MatrixBuffer m_MatrixA;MatrixBuffer m_MatrixB;MatrixBuffer m_MatrixC;
CD3D12ComputeShader::CD3D12ComputeShader()
{random_device rd; mt19937 gen(rd()); uniform_int_distribution<int> dist(1, 9);float f1 = 1;for (int i = 0; i < 4; i++){for (int j = 0; j < 4; j++){m_MatrixA.atrix.m[i][j] = f1++;//dist(gen); // f1++;//}}f1 = 1;for (int i = 0; i < 4; i++){for (int j = 0; j < 4; j++){m_MatrixB.atrix.m[i][j] = (f1++ )*100;//dist(gen);// f1++;}}for (int i = 0; i < 4; i++){for (int j = 0; j < 4; j++){m_MatrixC.atrix.m[i][j] = m_MatrixA.atrix.m[i][j] + m_MatrixB.atrix.m[i][j];}}
}
最后 矩阵C与回读堆的矩阵比较
void CD3D12ComputeShader::ComputeCommandLists()
{....bool bResultMatrix = true;for (int i = 0; i < 4 && bResultMatrix; i++){for (int j = 0; j < 4 && bResultMatrix; j++){if (m_pOutputMatrixData->atrix.m[i][j] != m_MatrixC.atrix.m[i][j]){bResultMatrix = false;break;}}}if (bResultMatrix){wstring str = L"\r\n" + MatrixToString(m_MatrixA.atrix);OutputDebugString(str.c_str());str = L" + \n" + MatrixToString(m_MatrixB.atrix);OutputDebugString(str.c_str());str = L" = \n" + MatrixToString(m_MatrixC.atrix) + L"\n \r\n";OutputDebugString(str.c_str());}else{OutputDebugString(L"!!!!!!!! ########## \r\n"); }
}
1.创建计算命令队列
创建CreateCommandQueue时指定D3D12_COMMAND_LIST_TYPE_COMPUTE类型。
void CD3D12ComputeShader::OnInit(HWND h)
{m_hWnd = h;UINT flags = OpenDebug();CreateDevice(flags, m_factory, m_device);CreateCommandQueue(m_device, m_commandQueue, D3D12_COMMAND_LIST_TYPE_COMPUTE);CreateComputeRootSignature(m_device);CreateComputeGPUPipelineState(m_device);CreateFenceSynchronization(m_device, m_fence, m_fenceEvent, m_fenceValue);CreateResourceView(m_device);}由于命令队列与命令分配器、命令列表的类型是一一对应(只针对本例子),所以通过命令队列GetDesc()得到类型,创建命令分配器、命令列表,代码如下:
void CD3D12Basic::CreateComputePipelineState(ComPtr<ID3D12Device>device, ComPtr<ID3D12CommandQueue> commandQueue, D3D12_COMPUTE_PIPELINE_STATE_DESC& psoDesc, ComPtr<ID3D12PipelineState>& pipelineState, ComPtr<ID3D12CommandAllocator>& commandAllocator, ComPtr<ID3D12GraphicsCommandList>& commandList, UINT nodeMask)
{D3D12_COMMAND_QUEUE_DESC queueDesc = commandQueue->GetDesc();ThrowIfFailed(device->CreateComputePipelineState(&psoDesc, IID_PPV_ARGS(&pipelineState)));ThrowIfFailed(device->CreateCommandAllocator(queueDesc.Type, IID_PPV_ARGS(&commandAllocator)));ThrowIfFailed(device->CreateCommandList(nodeMask, queueDesc.Type, commandAllocator.Get(), pipelineState.Get(), IID_PPV_ARGS(&commandList)));
}
2.创建根签名
1.用两个着色器资源视图 (SRV),存放两个矩阵数据
2.一个无序访问视图 (UAV),存放两个矩阵相加结果
3.一个shader.hlsl程序,实现加法运算
编写根签名代码
void CD3D12ComputeShader::CreateComputeRootSignature(ComPtr<ID3D12Device>device)
{CD3DX12_DESCRIPTOR_RANGE1 ranges[2];ranges[0].Init(D3D12_DESCRIPTOR_RANGE_TYPE_SRV, 2, 0, 0, D3D12_DESCRIPTOR_RANGE_FLAG_DATA_STATIC);ranges[1].Init(D3D12_DESCRIPTOR_RANGE_TYPE_UAV, 1, 0, 0, D3D12_DESCRIPTOR_RANGE_FLAG_DATA_VOLATILE);CD3DX12_ROOT_PARAMETER1 computeRootParameters[2];computeRootParameters[0].InitAsDescriptorTable(2, ranges);computeRootParameters[1].InitAsConstants(4, 0); //可以没有CD3DX12_VERSIONED_ROOT_SIGNATURE_DESC computeRootSignatureDesc;computeRootSignatureDesc.Init_1_1(_countof(computeRootParameters), computeRootParameters);CreateRootSignature(m_device, computeRootSignatureDesc, m_rootSignature);
}3.创建计算管线状态对象(Compute Pipeline State Object,CPSO)
vs编译Shader.hlsl程序,在exe目录下会有.cso后缀文件,读文件内容到程序中就可以使用
void CD3D12ComputeShader::CreateComputeGPUPipelineState(ComPtr<ID3D12Device>device)
{std::vector<uint8_t> hlslData = ReadHLSLData(GetShaderFilePath(L"ComputeShader.cso").c_str());D3D12_COMPUTE_PIPELINE_STATE_DESC computePsoDesc = {};computePsoDesc.pRootSignature = m_rootSignature.Get();computePsoDesc.CS.pShaderBytecode = hlslData.data();computePsoDesc.CS.BytecodeLength = hlslData.size();CreateComputePipelineState(m_device, m_commandQueue, computePsoDesc, m_pipelineState, m_commandAllocator, m_commandList);m_commandList->Close();
}4.创建资源
1. 如何选择资源的创建方式:
已提交资源CreateCommittedResource,实现代码简单。已定位资源CreatePlacedResource,要指定堆,D3D12推荐方式。为了简单化使用已提交资源方式。
2. 如何选择堆类型:
默认堆D3D12_HEAP_TYPE_DEFAULT, GPU可读写,CPU不能访问
上传堆D3D12_HEAP_TYPE_UPLOAD , GPU可读,CPU可读写
回读堆D3D12_HEAP_TYPE_READBACK,GPU可读写,CPU可读
我们用色器资源视图 (SRV)作为存放矩阵数据,GPU只有读数据的需求,如果堆类型 选择默认堆,那么还要一个上传堆,对其进行复制数据 (第二章处理纹理方式)。如果堆类型上传堆,只要对上传堆数据进行初始化数据就可以了,GPU只读数据,满足需求。所以堆类型上传堆。
我们用 无序访问视图 (UAV) 存放两个矩阵相加结果,由GPU将计算结果写到无序访问视图 (UAV)的资源中,GPU对其可写需求,所以必须 选用 默认堆
由于矩阵计算结果放在了GPU的默认堆上,CPU不能访问,解决方法:创建一个回读堆让GPU将默认堆的结果,复制回读堆上,CPU访问回读堆,也就是借回读堆读到计算结果
3. 创建描述符堆
指定 色器资源视图 (SRV)、无序访问视图 (UAV) 之间的关系
指定类型 D3D12_DESCRIPTOR_HEAP_TYPE_CBV_SRV_UAV,数量 3个.
CreateDescriptorHeap(m_device, m_cbvSrvUavDescriptorHeap, D3D12_DESCRIPTOR_HEAP_TYPE_CBV_SRV_UAV,3, D3D12_DESCRIPTOR_HEAP_FLAG_SHADER_VISIBLE);
4. 创建色器资源视图 (SRV) 相关资源
void CreateCommittedResource2(int nSize, D3D12_HEAP_TYPE heap, ComPtr<ID3D12Resource>& outResource, D3D12_RESOURCE_STATES init = D3D12_RESOURCE_STATE_GENERIC_READ, D3D12_RESOURCE_FLAGS descFlags = D3D12_RESOURCE_FLAG_NONE){CD3DX12_HEAP_PROPERTIES descHeap = CD3DX12_HEAP_PROPERTIES(heap);CD3DX12_RESOURCE_DESC descResource = CD3DX12_RESOURCE_DESC::Buffer(nSize, descFlags);CreateCommittedResource(m_device, descHeap, D3D12_HEAP_FLAG_NONE, descResource, init, outResource);}int srvMatrixDataSize = sizeof(MatrixBuffer)*2;CreateCommittedResource2(srvMatrixDataSize, D3D12_HEAP_TYPE_UPLOAD, m_srvInputMatrixBuffer);{UINT8* pDataBuffer = NULL;ThrowIfFailed(m_srvInputMatrixBuffer->Map(0, NULL, reinterpret_cast<void**>(&pDataBuffer)));memcpy(pDataBuffer, &m_MatrixA, sizeof(MatrixBuffer));memcpy(pDataBuffer + sizeof(MatrixBuffer), &m_MatrixB, sizeof(MatrixBuffer));m_srvInputMatrixBuffer->Unmap(0, NULL);}资源 要存放 矩阵A和矩阵B的数据,所以大小是 sizeof(MatrixBuffer)*2,memcpy(pDataBuffer, &m_MatrixA, sizeof(MatrixBuffer));是复制矩阵数据到资源中。
5. 创建色器资源视图 (SRV)
D3D12_SHADER_RESOURCE_VIEW_DESC srvDesc = {};srvDesc.Format = DXGI_FORMAT_UNKNOWN;srvDesc.ViewDimension = D3D12_SRV_DIMENSION_BUFFER;srvDesc.Shader4ComponentMapping = D3D12_DEFAULT_SHADER_4_COMPONENT_MAPPING;srvDesc.Buffer.NumElements = 1;srvDesc.Buffer.FirstElement = 0;srvDesc.Buffer.StructureByteStride = sizeof(MatrixBuffer);srvDesc.Buffer.Flags = D3D12_BUFFER_SRV_FLAG_NONE;CD3DX12_CPU_DESCRIPTOR_HANDLE srvHandle1(m_cbvSrvUavDescriptorHeap->GetCPUDescriptorHandleForHeapStart(), 0, m_cbvSrvUavDescriptorSize);CreateShaderResourceView(m_device, m_srvInputMatrixBuffer.Get(), srvDesc, srvHandle1);srvDesc.Buffer.FirstElement = 1;CD3DX12_CPU_DESCRIPTOR_HANDLE srvHandle2(m_cbvSrvUavDescriptorHeap->GetCPUDescriptorHandleForHeapStart(), 1, m_cbvSrvUavDescriptorSize);CreateShaderResourceView(m_device, m_srvInputMatrixBuffer.Get(), srvDesc, srvHandle2);
1. srvDesc.Format = DXGI_FORMAT_UNKNOWN; 使用自定义数据结构
2. srvDesc.Buffer.NumElements = 1; 一个SRV对应一个矩阵数据
3. srvDesc.Buffer.FirstElement = 0;或srvDesc.Buffer.FirstElement = 1; 矩阵数据在资源中的位置
4.CD3DX12_CPU_DESCRIPTOR_HANDLE srvHandle1(m_cbvSrvUavDescriptorHeap->GetCPUDescriptorHandleForHeapStart(), index, m_cbvSrvUavDescriptorSize); 其中index指定在描述符堆(D3D12_DESCRIPTOR_HEAP_TYPE_CBV_SRV_UAV)的位置。同理 创建无序访问视图 (UAV)和资源
6. 创建无序访问视图 (UAV)和资源
srvMatrixDataSize = sizeof(MatrixBuffer);UINT nUavAlign = UPPER_ALING_DIV(srvMatrixDataSize, D3D12_UAV_COUNTER_PLACEMENT_ALIGNMENT);CreateCommittedResource2(nUavAlign + srvMatrixDataSize, D3D12_HEAP_TYPE_DEFAULT, m_uavOutputMatrixGpuBuffer, D3D12_RESOURCE_STATE_COPY_DEST, D3D12_RESOURCE_FLAG_ALLOW_UNORDERED_ACCESS);/// uav D3D12_UNORDERED_ACCESS_VIEW_DESC uavDesc = {};uavDesc.Format = DXGI_FORMAT_UNKNOWN;uavDesc.ViewDimension = D3D12_UAV_DIMENSION_BUFFER;uavDesc.Buffer.FirstElement = 0;uavDesc.Buffer.NumElements = 1;uavDesc.Buffer.StructureByteStride = sizeof(MatrixBuffer);uavDesc.Buffer.CounterOffsetInBytes = nUavAlign;uavDesc.Buffer.Flags = D3D12_BUFFER_UAV_FLAG_NONE;CD3DX12_CPU_DESCRIPTOR_HANDLE uavHandle(m_cbvSrvUavDescriptorHeap->GetCPUDescriptorHandleForHeapStart(), 2, m_cbvSrvUavDescriptorSize);CreateUnorderedAccessView(m_device, m_uavOutputMatrixGpuBuffer, m_uavOutputMatrixGpuBuffer, uavDesc, uavHandle);
创建无序访问视图 (UAV)的资源时要比资源本身大一倍 所以 资源大小是nUavAlign + srvMatrixDataSize。nUavAlign数据对齐大小是 D3D12_UAV_COUNTER_PLACEMENT_ALIGNMENT(4096)。
uavDesc.Buffer.StructureByteStride = sizeof(MatrixBuffer); 矩阵数据结构大小
uavDesc.Buffer.CounterOffsetInBytes = nUavAlign; 数据对齐大小
7. 创建回读堆资源
CreateCommittedResource2(nUavAlign + srvMatrixDataSize, D3D12_HEAP_TYPE_READBACK, m_uavOutputBeadBackData, D3D12_RESOURCE_STATE_COPY_DEST);ThrowIfFailed(m_uavOutputBeadBackData->Map(0, NULL, reinterpret_cast<void**>(&m_pOutputMatrixData)));MatrixBuffer* m_pOutputMatrixData = nullptr;回读堆资源大小应与(UAV)的资源一样 nUavAlign + srvMatrixDataSize。
5.命令队列执行计算着色器
1. 调用 命令列表接口 ID3D12GraphicsCommandList::Dispatch()执行计算
2.序访问视图 (UAV)的资源设置屏障等Shader程序计算完成
CD3DX12_RESOURCE_BARRIER barrier1 = CD3DX12_RESOURCE_BARRIER::Transition(m_uavOutputMatrixGpuBuffer.Get(),D3D12_RESOURCE_STATE_UNORDERED_ACCESS, D3D12_RESOURCE_STATE_COPY_SOURCE);
m_commandList->ResourceBarrier(1, &barrier1);3. 调用 命令列表接口 ID3D12GraphicsCommandList ::CopyResource(),将计算结果复制回读堆上
m_commandList->CopyResource(m_uavOutputBeadBackData.Get(), m_uavOutputMatrixGpuBuffer.Get());m_commandList->Close();4.调用 命令队列ExecuteCommandLists()执行
ID3D12CommandList* ppCommandLists[] = { m_commandList.Get() };m_commandQueue->ExecuteCommandLists(_countof(ppCommandLists), ppCommandLists);
5. 围栏等命令队列执行结束
WaitForFenceCompletion(m_commandQueue, m_fence, m_fenceEvent, m_fenceValue);
m_fenceValue++;6. 检测矩阵数据是否计算正确
bool bResultMatrix = true;for (int i = 0; i < 4 && bResultMatrix; i++){for (int j = 0; j < 4 && bResultMatrix; j++){if (m_pOutputMatrixData->atrix.m[i][j] != m_MatrixC.atrix.m[i][j]){bResultMatrix = false;break;}}}6. Shader.hlsl程序
1. vs创建计算着色器 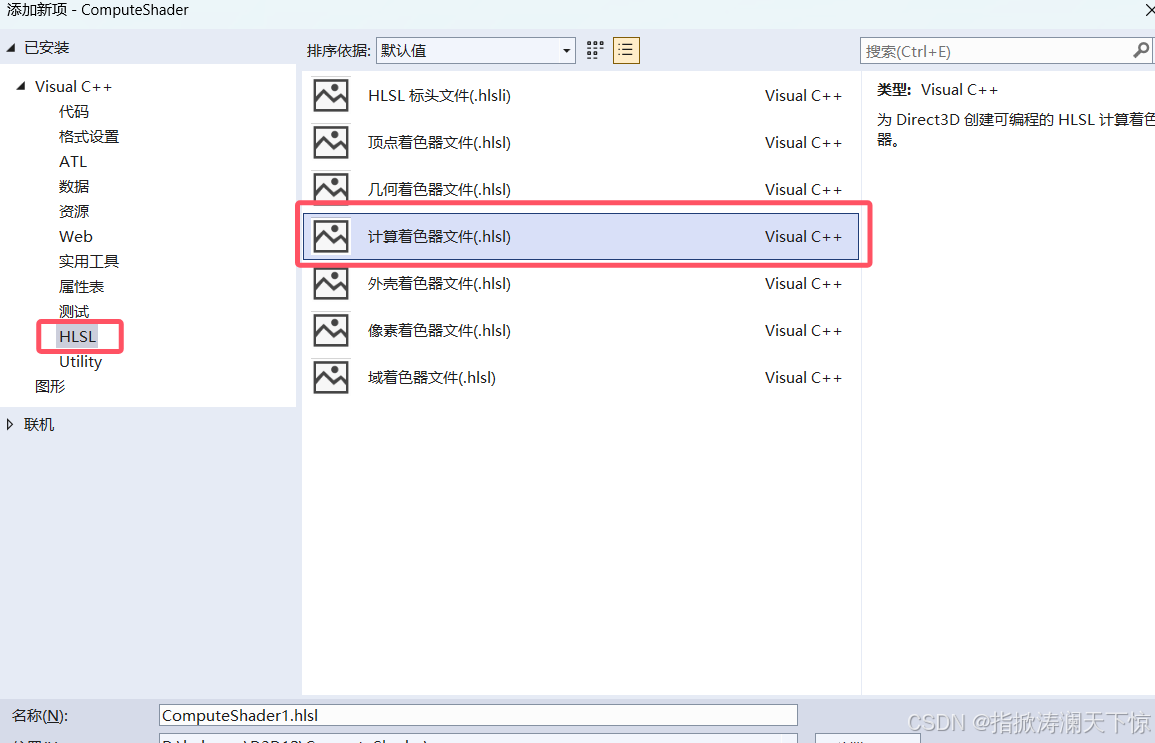
ComputeShader.hlsl文件
struct MatrixBuffer
{float4x4 atrix;float padding[48];
};StructuredBuffer<MatrixBuffer> gInputA : register(t0);
StructuredBuffer<MatrixBuffer> gInputB : register(t1);
RWStructuredBuffer<MatrixBuffer> gOutput : register(u0);[numthreads(1, 1, 1)]
void main( uint3 DTid : SV_DispatchThreadID )
{gOutput[DTid.x].atrix = gInputA[DTid.x].atrix + gInputB[DTid.x].atrix;
}1.StructuredBuffer 只读的结构化缓冲区
2.RWStructuredBuffer可读写的结构化缓冲区
3.register(t0) 表示第一个色器资源视图 (SRV)资源
4. register(u0);表示 无序访问视图 (UAV)的资源
5. [numthreads(1, 1, 1)] GPU线程组数量= X*Y*Z
程序最终运行效果:

感谢大家的支持,如要问题欢迎提问指正。