CVPR-2025 | 南洋理工基于图表示的具身导航统一框架!UniGoal:通用零样本目标导航方法

- 作者:Hang Yin 1 ^{1} 1, Xiuwei Xu 1 ^{1} 1, Linqing Zhao 1 ^{1} 1, Ziwei Wang 2 ^{2} 2, Jie Zhou 1 ^{1} 1, Jiwen Lu 1 ^{1} 1
- 单位: 1 ^{1} 1南洋理工大学, 2 ^{2} 2清华大学
- 论文标题:UniGoal: Towards Universal Zero-shot Goal-oriented Navigation
- 论文链接:https://arxiv.org/abs/2503.10630
- 项目主页:https://bagh2178.github.io/UniGoal/
- 代码链接:https://github.com/bagh2178/UniGoal
主要贡献
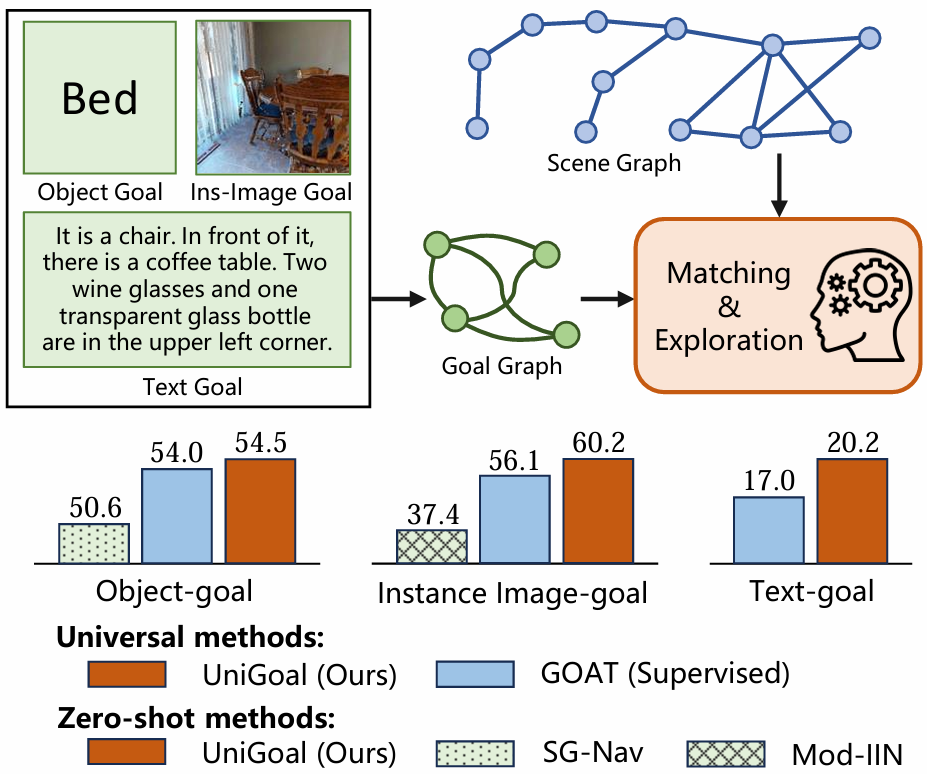
- 论文提出了统一的图表示方法来统一不同的目标类型,包括对象类别、实例图像和文本描述,能够在保持结构信息的同时,利用LLM进行显式的基于图的推理。
- 设计了多阶段的场景探索策略,根据场景图和目标图的匹配状态生成长期探索目标,包括在零匹配时迭代搜索子图,在部分匹配时使用坐标投影和对齐锚点对,并在完美匹配时进行场景图校正和目标验证。
- 为了实现鲁棒的阶段切换,引入了黑名单机制,用于记录不成功的匹配结果,避免重复探索。这有助于提高探索效率和成功率。
- 在多个基准数据集上进行了广泛的实验,验证了UniGoal在三种任务上的零样本性能,在所有任务上都达到了SOTA水平,甚至在某些情况下超过了特定任务的零样本方法和需要训练或微调的通用方法。
研究背景
研究问题
- 论文主要解决的问题是如何实现通用零样本目标导向导航。
- 现有的零样本方法通常针对特定任务构建推理框架,这些框架在整体流程上存在很大差异,并且无法在不同类型的目标之间进行泛化。
研究难点
该问题的研究难点包括:
- 如何统一不同类型的任务(如对象类别、实例图像和文本描述),
- 如何在零样本情况下进行有效的推理和决策,
- 以及如何在不进行训练或微调的情况下实现强泛化能力。
相关工作
-
零样本导航:
- 传统监督方法:传统的监督导航方法需要在模拟环境中进行大规模训练,限制了其在实际环境中的泛化能力。
- 按目标类型的零样本导航:零样本导航可以根据目标类型分为对象导航(ON)、实例图像导航(IIN)和文本导航(TN)。每种类型的零样本导航都有其特定的方法和挑战。
- 基于CLIP的方法:一些方法利用开放词汇的CLIP模型来构建零样本导航的基线,通过探索前沿区域来进行目标定位。
- 结合大语言模型的方法:其他方法进一步利用大语言模型(LLM)来提取物体之间的常识关系,以进行目标位置推理。
-
基于场景图的探索:
- 场景表示方法:为了更好地理解和探索场景,研究者们提出了多种场景表示方法,其中基于场景图表示因其显式图结构而受到关注。
- 结合LLM和VLM的方法:一些工作尝试将图表示与LLM和视觉语言模型(VLM)结合,以实现高层次的推理和决策。
- 如SayPlan和OVSG,它们利用图表示进行任务规划和实体定位。
-
现有方法的局限性:
- 特定任务的局限性:现有的零样本导航方法通常是为特定任务设计的,无法在更广泛的目标类型之间进行转移。
- 缺乏通用性:尽管有一些通用方法如GOAT和PSL,但它们仍然需要训练资源,并且在真实世界中的应用效果有限。
方法
目标导向导航
任务定义
- 在目标导向导航中,智能体的任务是在未知环境中导航到一个指定的目标 g g g 。
- 其中 g g g 可以是对象类别(Object-goal Navigation, ON)、包含可以在场景中找到的对象的图像(Instance-Image-goal Navigation, IIN)或关于某个对象的描述(Text-goal Navigation, TN)。
- 智能体接收RGB-D视频流,并在每次接收到新的RGB-D观测时执行动作
a
∈
A
a \in A
a∈A ,其中
A
A
A 是动作集合,包括
move_forward,turn_left,turn_right和stop。
任务规范
目标是研究通用零样本目标导向导航,具有两个特点:
- 通用性:设计一个在三个子任务之间切换时不需要修改的通用方法。
- 零样本:所有三种目标都可以通过自由形式的语言或图像指定。导航方法不需要任何训练或微调。
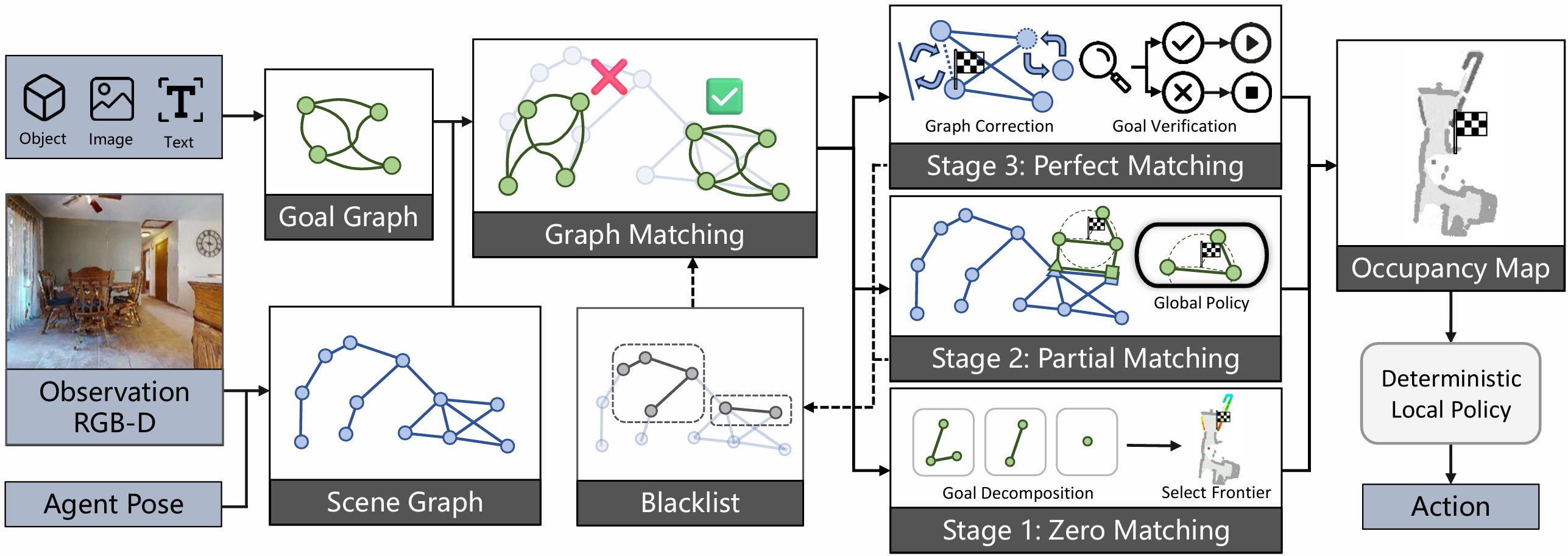
框架概述
- 为了实现通用零样本目标导向导航,利用大模型(LLM)进行零样本决策。
- 通过将场景和目标表示为图(即场景图和目标图),使不同的目标统一表示,并保持一致的场景和目标表示。
- 基于这种表示,提示LLM进行场景理解、图匹配和探索决策。
图的构建与匹配
-
图的构建:定义图 G = ( V , E ) \mathcal{G} = (\mathcal{V}, \mathcal{E}) G=(V,E) 为一组节点 V \mathcal{V} V 和连接它们的边 E \mathcal{E} E 。每个节点代表一个对象,每条边代表对象之间的关系。节点和边的内容以文本格式描述。
-
图的嵌入:节点的嵌入函数为 E m b e d ( v ) = c o n c a t ( C L I P ( v ) , D e g r e e ( v ) ) Embed(v) = concat(CLIP(v), Degree(v)) Embed(v)=concat(CLIP(v),Degree(v)) ,其中 C L I P ( ⋅ ) CLIP(\cdot) CLIP(⋅) 是CLIP[28]文本编码器,Degree ( ⋅ ) (\cdot) (⋅) 是节点的度。边的嵌入函数为 E m b e d ( e ) = C L I P ( e ) Embed(e) = CLIP(e) Embed(e)=CLIP(e) 。
-
图匹配:通过图匹配确定目标或其相关对象是否被观察到。设计了三种匹配度量:节点匹配、边匹配和拓扑匹配。具体来说,对于节点和边,提取它们的嵌入并计算成对相似性,使用二分匹配确定匹配的节点和边对:
M N = B ( thr ( Embed ( V t ) ⋅ Embed ( V g ) T ) ) \mathcal{M}_{N} = \mathcal{B}\left(\operatorname{thr}\left(\operatorname{Embed}\left(\mathcal{V}_{t}\right) \cdot \operatorname{Embed}\left(\mathcal{V}_{g}\right)^{T}\right)\right) MN=B(thr(Embed(Vt)⋅Embed(Vg)T))
M E = B ( thr ( Embed ( E t ) ⋅ Embed ( E g ) T ) ) \mathcal{M}_{E} = \mathcal{B}\left(\operatorname{thr}\left(\operatorname{Embed}\left(\mathcal{E}_{t}\right) \cdot \operatorname{Embed}\left(\mathcal{E}_{g}\right)^{T}\right)\right) ME=B(thr(Embed(Et)⋅Embed(Eg)T))
其中 Embed ( ⋅ ) ∈ R K × C \operatorname{Embed}(\cdot) \in R^{K \times C} Embed(⋅)∈RK×C , K K K 是节点或边的数量, C C C 是通道维度。 thr ( ⋅ ) \operatorname{thr}(\cdot) thr(⋅) 是应用于相似性矩阵的逐元素阈值函数,将小于 τ \tau τ 的值设置为 -1 以禁用对应对的匹配。 B ( ⋅ ) \mathcal{B}(\cdot) B(⋅) 是二分匹配,输出所有匹配的节点或边对。 -
拓扑相似性:基于 M N \mathcal{M}_{N} MN 和 M E \mathcal{M}_{E} ME ,进一步计算 G t \mathcal{G}_{t} Gt 和 G g \mathcal{G}_{g} Gg 之间的拓扑相似性,定义为它们之间的图编辑相似性:
S T = 1 − D ( S ( F ( G t , M N , M E ) ) , S ( G g ) ) S_{T} = 1 - \mathcal{D}\left(\mathcal{S}\left(\mathcal{F}\left(\mathcal{G}_{t}, \mathcal{M}_{N}, \mathcal{M}_{E}\right)\right), \mathcal{S}\left(\mathcal{G}_{g}\right)\right) ST=1−D(S(F(Gt,MN,ME)),S(Gg))
其中 F ( ⋅ ) \mathcal{F}(\cdot) F(⋅) 表示 G t \mathcal{G}_{t} Gt 的最小子图,包含 M N \mathcal{M}_{N} MN 中的节点和 M E \mathcal{M}_{E} ME 中的边。 S ( ⋅ ) \mathcal{S}(\cdot) S(⋅) 表示图的拓扑结构,忽略节点和边的内容。 D ( ⋅ ) \mathcal{D}(\cdot) D(⋅) 是两个图之间的归一化编辑距离。
-
最终匹配分数:定义为 S = S N + S E + S T 3 S = \frac{S_{N} + S_{E} + S_{T}}{3} S=3SN+SE+ST
多阶段场景探索策略
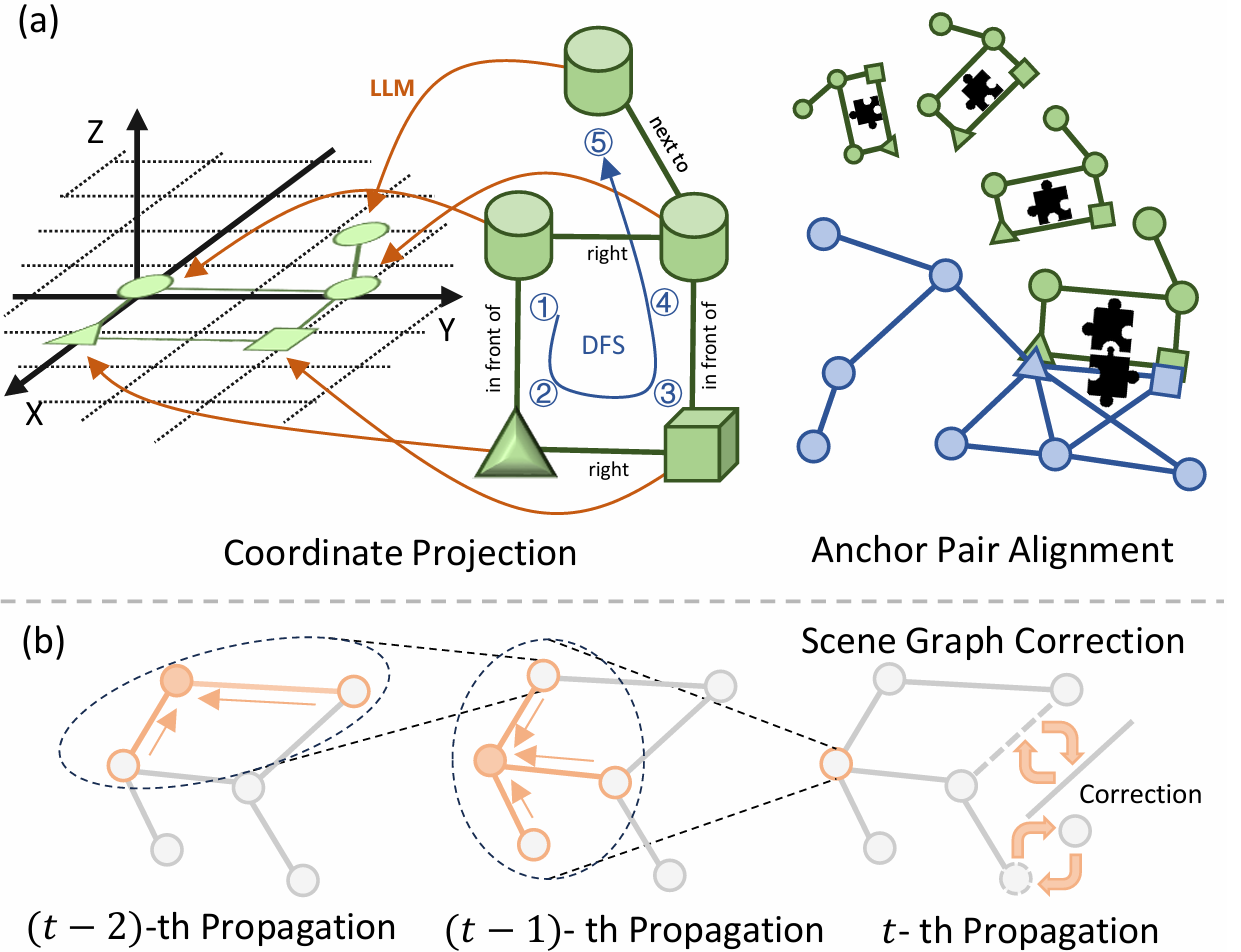
- 阶段1:零匹配:如果匹配分数 S S S 小于阈值 σ 1 \sigma_1 σ1 ,则进入零匹配阶段。智能体扩展其探索区域以找到目标元素。目标可能是一个复杂的图,将其分解为多个内部相关的子图,并使用LLM指导的分解策略进行处理。
- 阶段2:部分匹配:随着智能体的探索,目标的元素逐渐被观察到,匹配分数
S
S
S 增加。当
S
S
S 超过
σ
1
\sigma_1
σ1 但小于
σ
2
\sigma_2
σ2 时,进入部分匹配阶段。使用坐标投影和锚点对齐来推断目标位置。假设锚点是
v
t
1
,
v
t
2
∈
G
t
v_{t}^{1}, v_{t}^{2} \in \mathcal{G}_{t}
vt1,vt2∈Gt 和
v
g
1
,
v
g
2
∈
G
g
v_{g}^{1}, v_{g}^{2} \in \mathcal{G}_{g}
vg1,vg2∈Gg ,建立坐标转移矩阵
P
P
P :
P = S ⋅ R ⋅ T = [ s cos ( θ ) − s sin ( θ ) t x s sin ( θ ) s cos ( θ ) t y 0 0 1 ] P = S \cdot R \cdot T = \begin{bmatrix} s \cos(\theta) & -s \sin(\theta) & t_{x} \\ s \sin(\theta) & s \cos(\theta) & t_{y} \\ 0 & 0 & 1 \end{bmatrix} P=S⋅R⋅T= scos(θ)ssin(θ)0−ssin(θ)scos(θ)0txty1
基于锚点关系,建立方程 v t 1 = P ⋅ v g 1 v_{t}^{1} = P \cdot v_{g}^{1} vt1=P⋅vg1 和 v t 2 = P ⋅ v g 2 v_{t}^{2} = P \cdot v_{g}^{2} vt2=P⋅vg2 ,求解参数 t x , t y , θ , s t_{x}, t_{y}, \theta, s tx,ty,θ,s 。使用坐标转移矩阵 P P P 将 G g \mathcal{G}_{g} Gg 的其余节点投影到 G t \mathcal{G}_{t} Gt 的坐标中。 - 阶段3:完美匹配:
- 当 S S S 超过 σ 2 \sigma_2 σ2 且目标中心对象 o o o 被匹配时,进入完美匹配阶段。
- 智能体移动到匹配的对象并进行进一步验证。提出一个图校正和目标验证管道流程来修正场景图中的不合理结构,并在接近 o o o 的过程中判断目标的置信度。
黑名单机制
- 为了避免重复探索,提出了黑名单机制来记录不成功的匹配结果。
- 黑名单初始化为空,匹配失败时扩展黑名单。
实验
实验设置
-
数据集:
- UniGoal在对象导航(ON)、实例图像导航(IIN)和文本导航(TN)上进行评估。
- 对于ON,实验在广泛使用的Matterport3D(MP3D)、Habitat-Matterport 3D(HM3D)和RoboTHOR上进行,遵循SG-Nav的设置。
- 对于IIN和TN,与其他方法在HM3D上进行比较,分别遵循Mod-IIN和InstanceNav的设置。
-
评估指标:
- 使用成功率(SR)和路径长度加权的成功率(SPL)。
- SR表示成功导航的比例,而SPL衡量路径与最优路径的接近程度。
-
对比方法:
- 与研究的三项任务中的最新方法进行比较。
- 对于ON,与监督方法SemEXP、ZSON、OVRL-v2和零样本方法ESC、OpenFMNav、VLFM、SG-Nav进行比较。
- 对于IIN,与监督方法Krantz等、OVRL-v2(来自IEVE的实现)、IEVE和零样本方法Mod-IIN进行比较。
- 对于TN,由于目前没有零样本方法可用,与监督方法PSL和GOAT进行比较。
- PSL和GOAT也是通用方法,也与其他两项任务进行比较。
-
实现细节:
- 在Habitat Simulator中设置智能体。
- 部署LLaMA-2-7B作为LLM,通过文本部署LLaVA-v1.6-Mistral-7B作为视觉语言模型(VLM)。
- 在图匹配期间使用CLIP文本编码器提取节点和边的嵌入。超参数在附录中详细说明。
与最新方法的比较
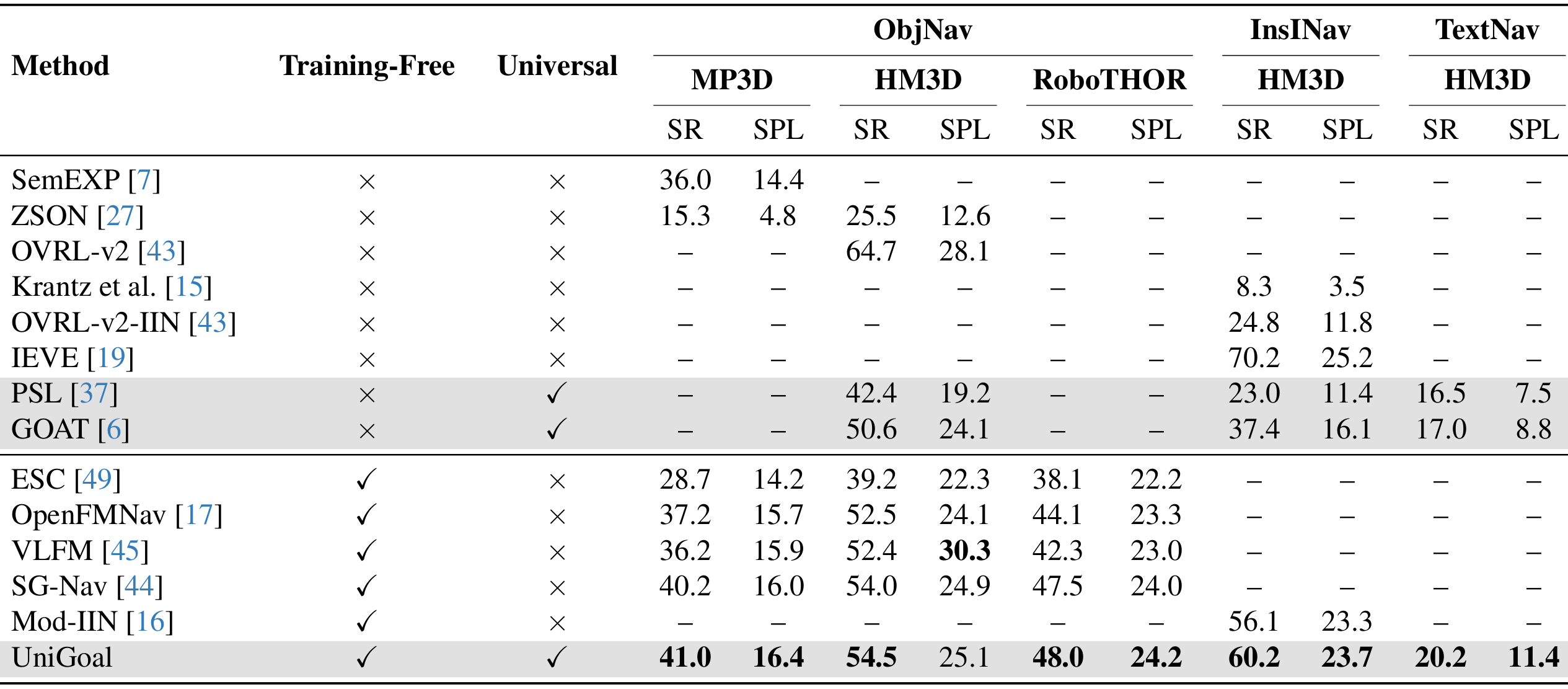
- UniGoal与不同设置的目标导向导航方法的最新方法进行比较,包括监督、零样本和通用方法。
- 在零样本ON和IIN上,UniGoal分别超越了最新的方法SG-Nav和Mod-IIN,分别提高了0.8%和4.1%。
- 即使在与其他通用方法比较时,UniGoal也表现出色,甚至在某些情况下超过了需要训练或微调的监督方法。
消融研究
在HM3D上进行消融实验,验证UniGoal各部分的有效性。报告消融版本在代表性IIN任务上的表现。

- 管道流程设计:
- 消融图匹配方法和多阶段探索策略。首先简化图匹配方法,通过移除分数计算来简化。
- 类似地,一旦中央对象 o o o 被匹配,智能体将直接进入阶段3。
- 结果显示,如果没有匹配程度的判断,智能体无法在最佳时机切换探索策略,导致更多失败案例。
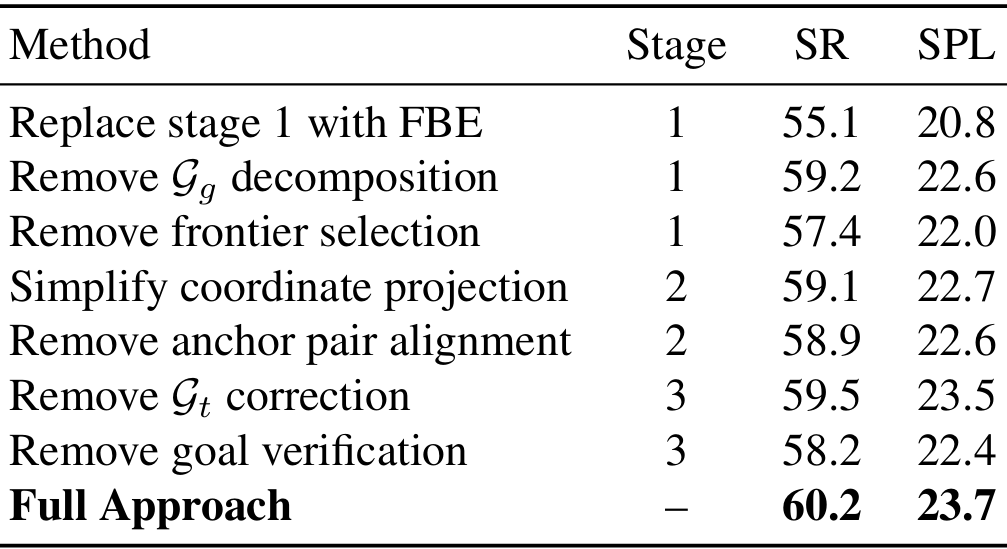
- 每个探索阶段的效果:
对每个探索阶段进行消融研究。- 对于阶段1,首先用简单的FBE策略替换整个阶段。然后移除目标图分解,并提示LLM使用整个图。还通过让LLM预测目标的位置而不是为每个前沿打分来移除前沿选择。结果显示,阶段1的每个组件都是有效的。
- 对于阶段2,首先简化LLM基于的坐标投影方法,随机猜测2D坐标。然后移除锚点对对齐方法,直接让LLM基于BEV图预测目标位置。实验结果验证了利用图之间的结构重叠来推断目标位置的有效性。
- 对于阶段3,依次移除场景图校正和目标验证,并报告结果。结果显示,这两种方法都能很好地提高最终性能,这意味着校正场景图以及验证目标图对于稳健导航至关重要。
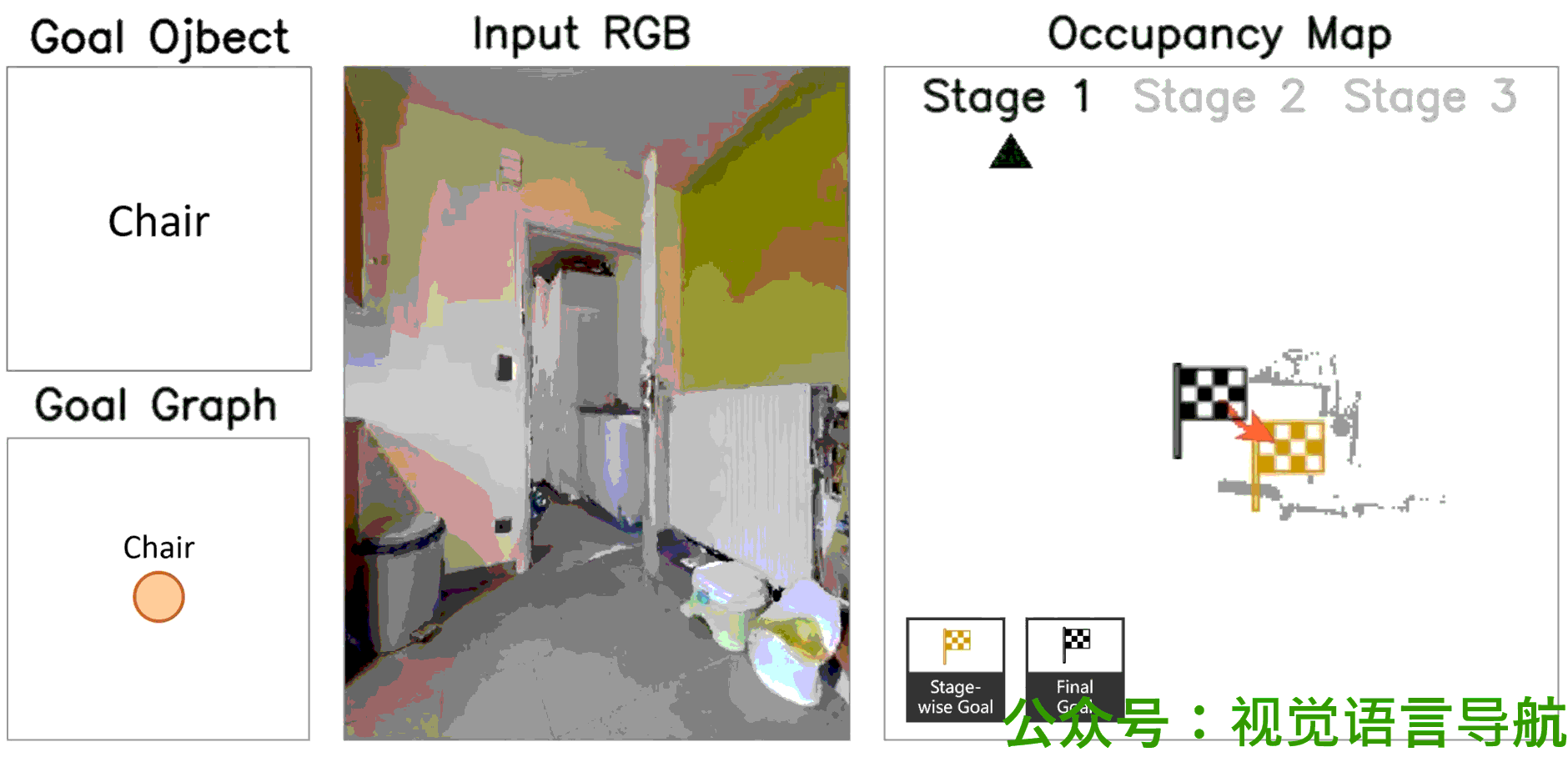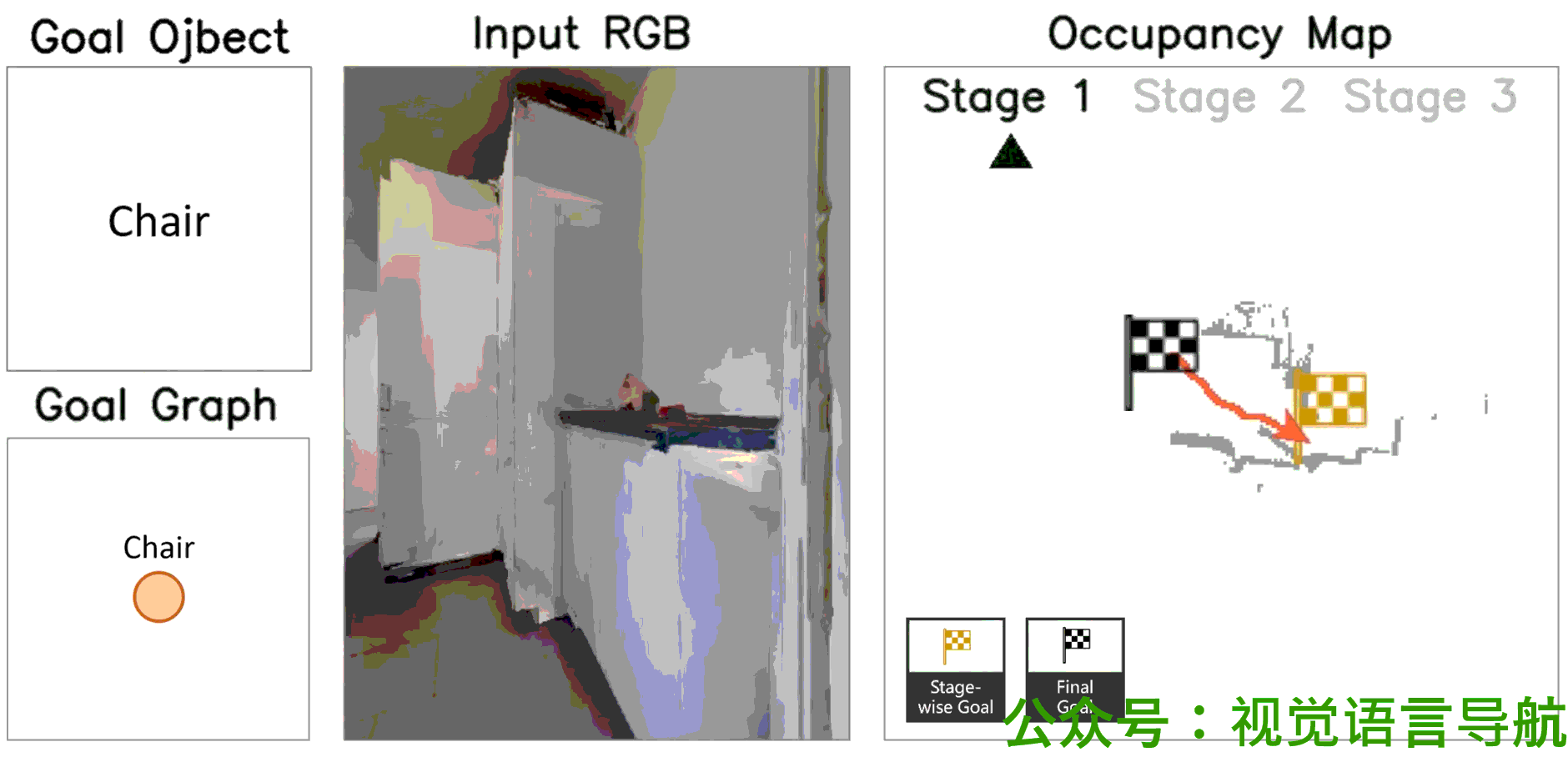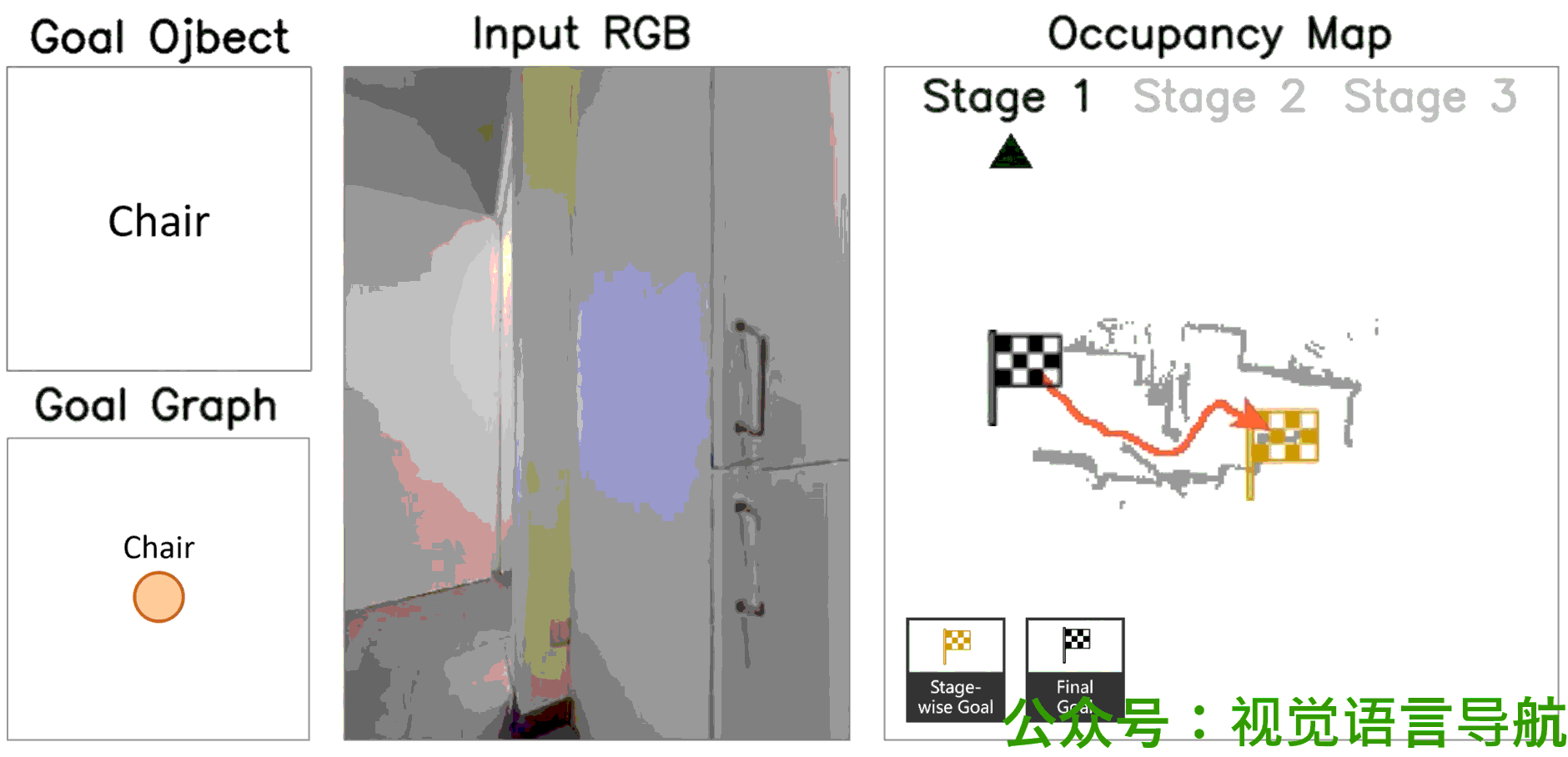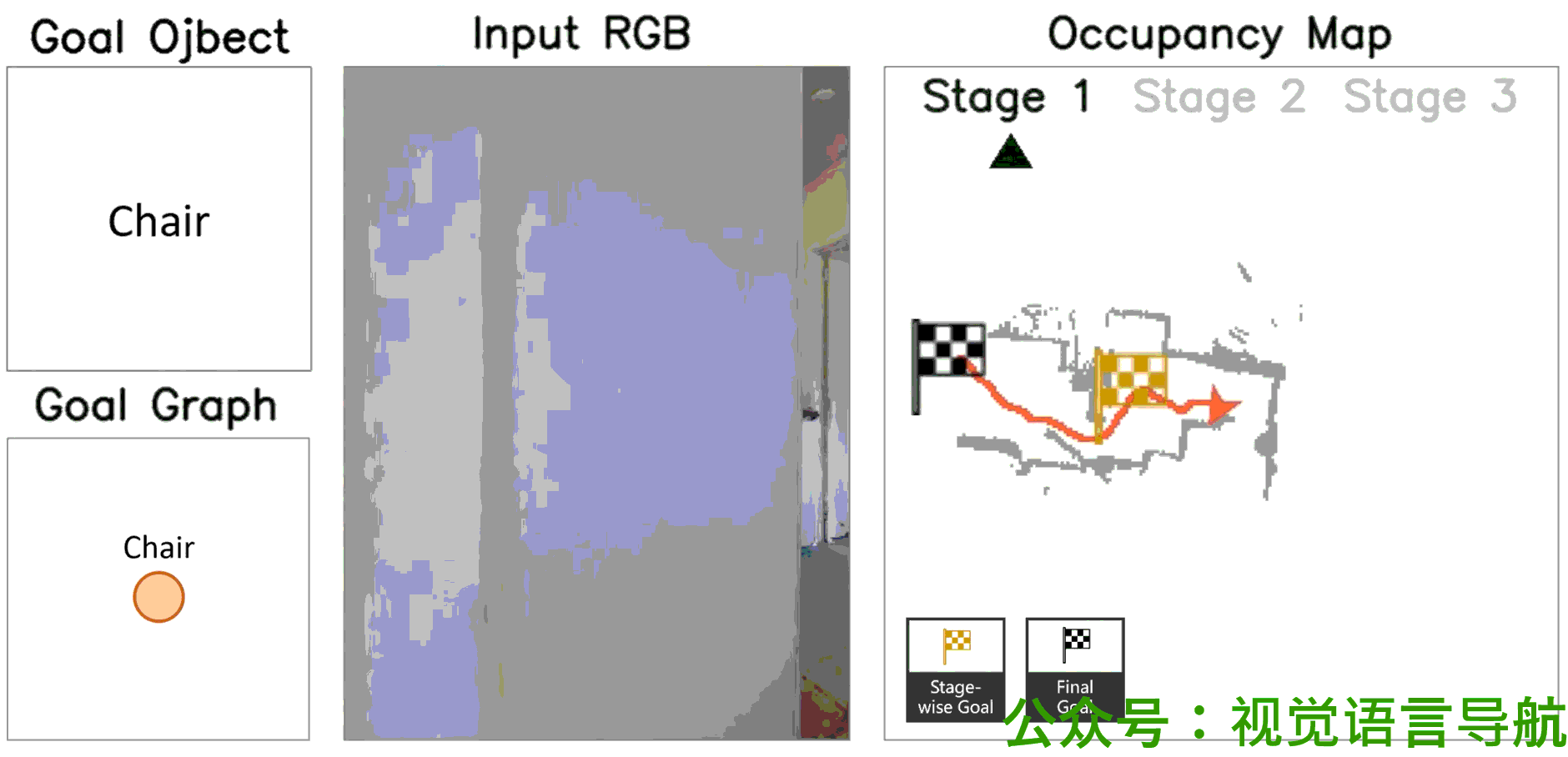
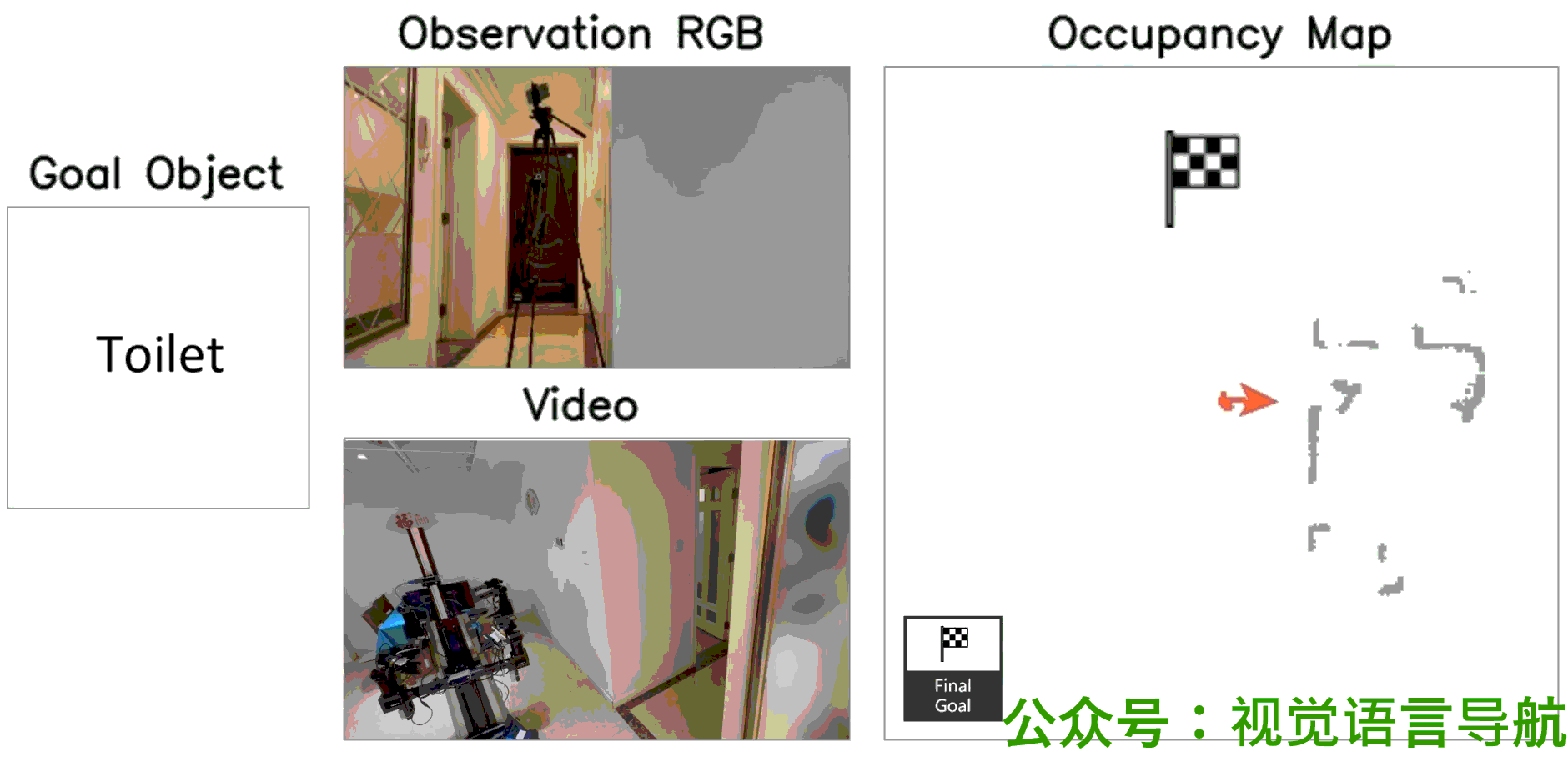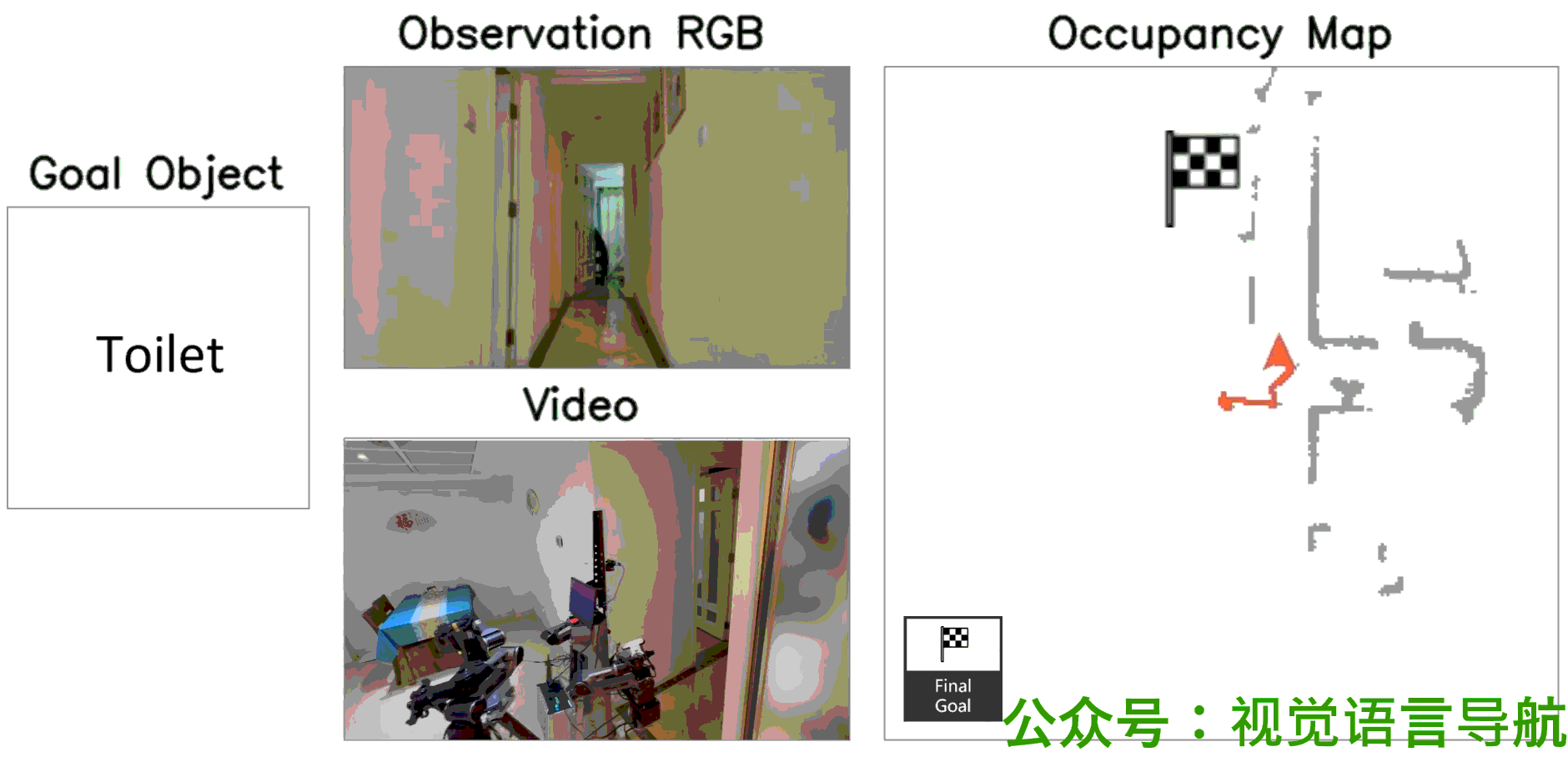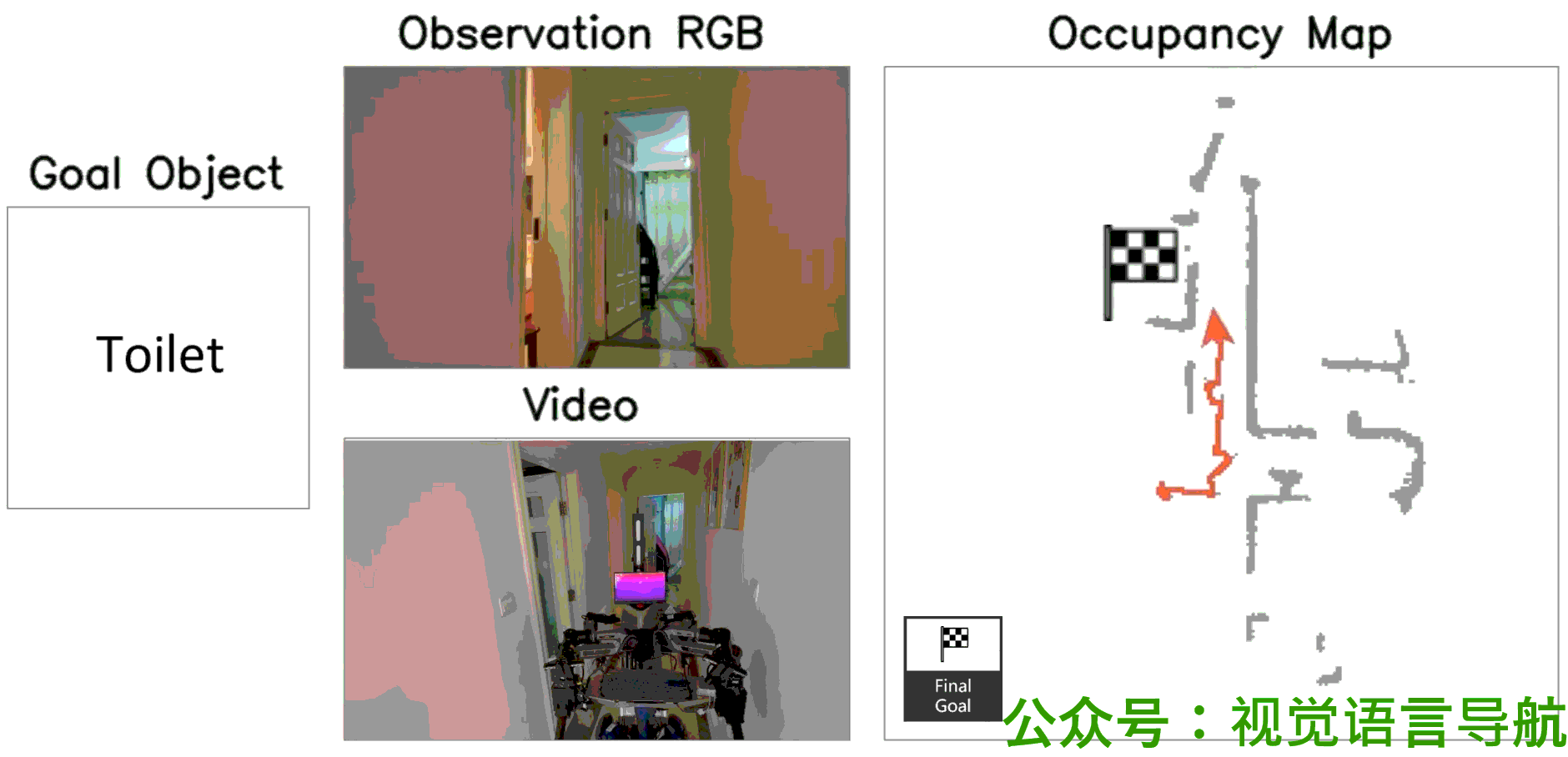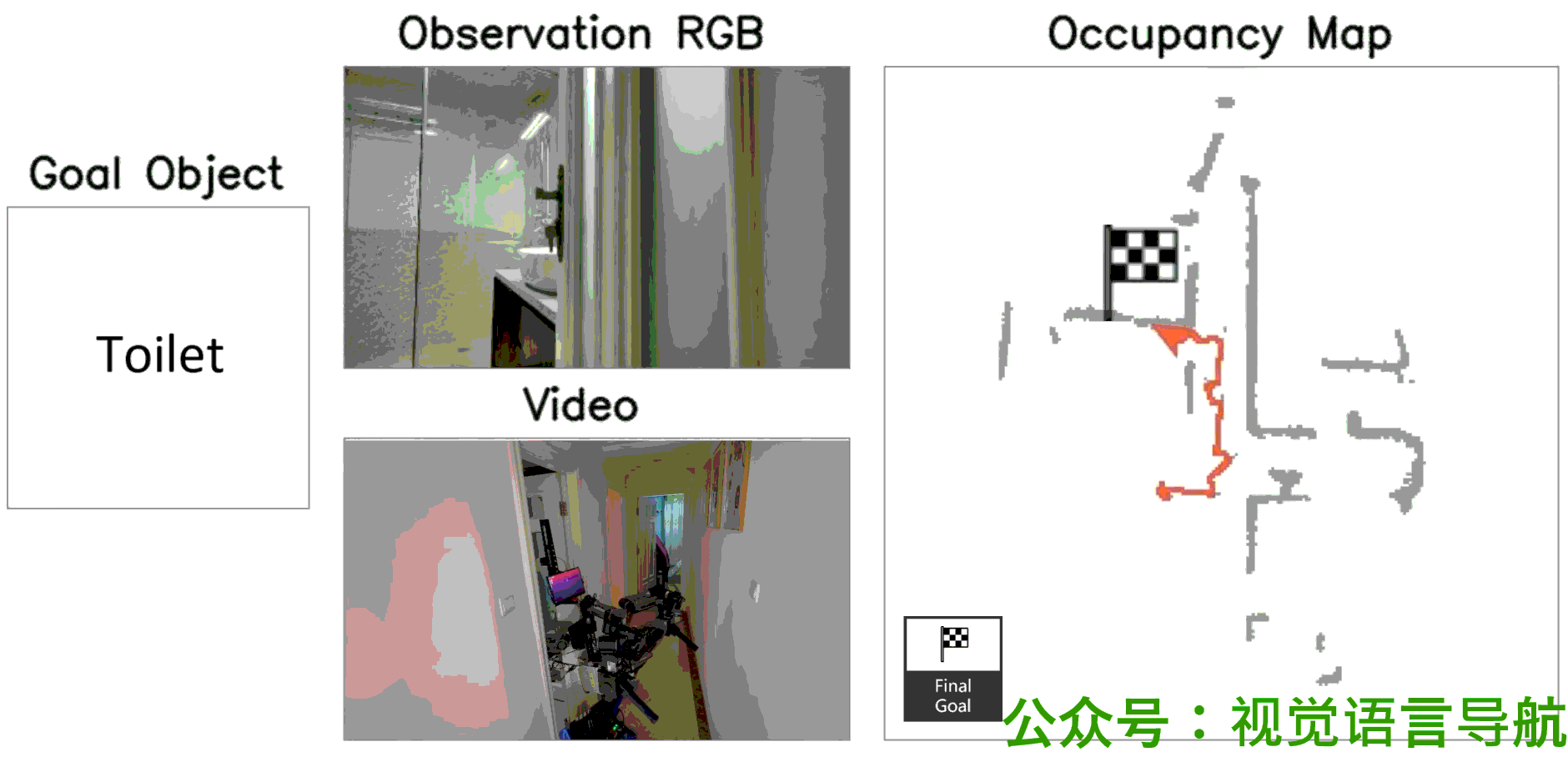
定性分析
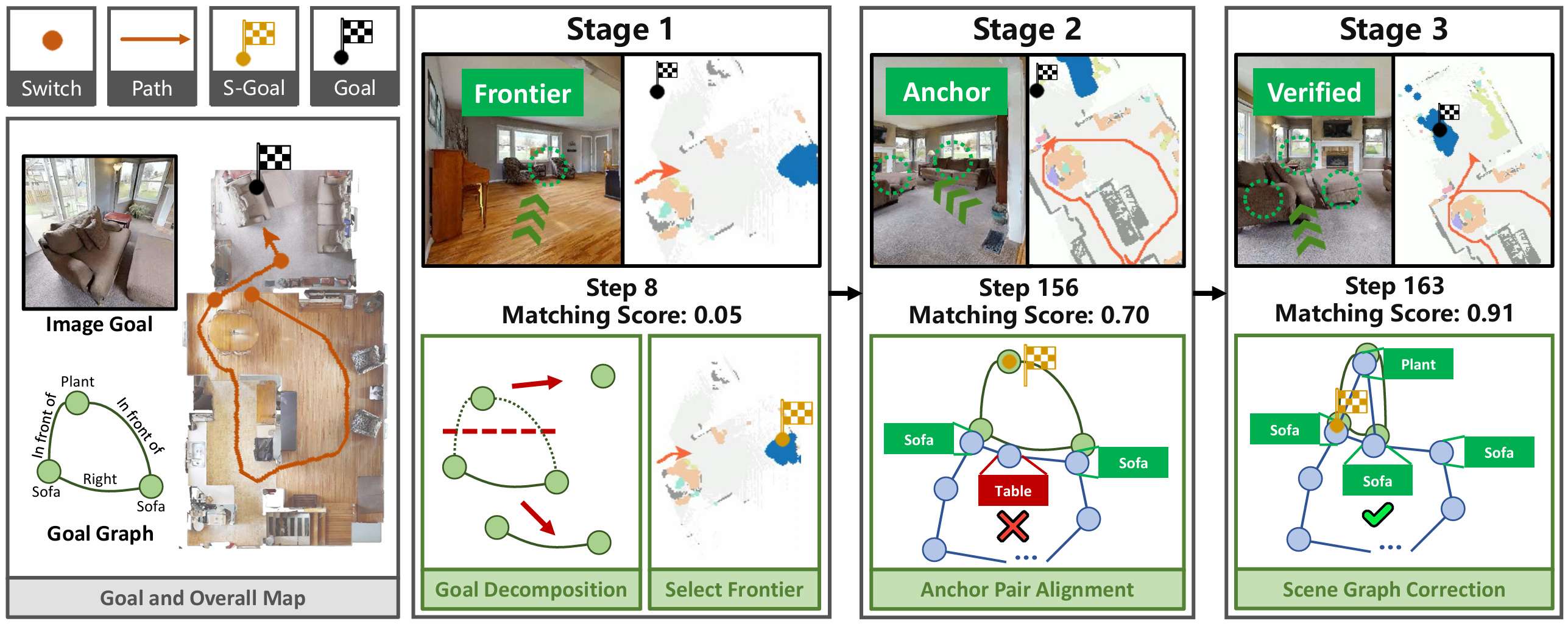
-
决策过程:
- UniGoal通过基于图的探索方法逐步增加匹配分数,展示了其决策过程的逐步进展。
- 这表明UniGoal能够有效地识别和接近目标。
-
导航路径:
- 通过可视化展示了UniGoal在不同任务上的导航路径。
- UniGoal能够在多种任务中生成高效的导航轨迹,显示出其在处理多样化目标类型时的能力。
-
通用性:
- UniGoal的设计使其能够在不同任务和环境中共享相同的框架,无需针对特定任务进行修改或重新训练,显示出其强大的适应性和泛化能力。

总结
- 论文提出了UniGoal,一种无需训练或微调的通用零样本目标导向导航框架。
- 通过统一的图表示和多阶段探索策略,UniGoal能够在不同任务之间进行有效的推理和决策。
- 实验结果表明,UniGoal在三个广泛使用的数据集上均取得了最先进的零样本性能,甚至在某些情况下超过了为特定任务设计的零样本方法和需要训练或微调的通用方法。
- UniGoal在真实世界机器人平台上的部署也展示了其强大的泛化能力和应用价值。
